19.5. Induktív logikai programozás
Az induktív logikai programozás (ILP) az induktív módszereket az elsőrendű reprezentációk erejével kombinálva, az elméletek logikai programok formájában történő kifejezésére helyezi a hangsúlyt.[192] Az ILP három oknál fogva terjedt el. Először is az ILP az általános tudásalapú induktív tanulási probléma precíz, szigorú megközelítését adja. Másodszor, teljes algoritmusokat szolgáltat az általános elsőrendű elméletek indukciós úton, példák alapján történő előállítására. Következésképpen olyan területeken is képes sikeresen tanulni, ahol az attribútumalapú algoritmusokat nehéz alkalmazni. Ennek egy példája a fehérjemolekulák összehajtogatásának a tanulása (lásd 19.10. ábra). A fehérjemolekula háromdimenziós konfigurációját egy attribútumhalmazzal ésszerűen kifejezni nem lehet, mert a konfiguráció lényege az objektumok közötti relációkra vonatkozik, és nem az egyes objektumok attribútumaira. A relációk leírására megfelelő apparátus az elsőrendű logika. Harmadszor, induktív logikai programozás által létrehozott hipotézisek emberek számára (viszonylag) könnyen olvashatók. A 19.10. ábrabeli természetes nyelvű fordítást a gyakorló biológusok végigelemezhetik és kritizálhatják. Ez azt jelenti, hogy az induktív logikai programrendszerek részt vehetnek a kísérletezés, a hipotézisgenerálás, a megvitatás és a cáfolat tudományos ciklusában. Az ilyen részvétel a „fekete doboz” osztályozókat gyártó módszerek számára, mint amilyenek például a neurális hálók, lehetetlen lenne.
Emlékezzünk a (19.5) egyenlet alapján, hogy az általános tudásalapú indukciós probléma az alábbi vonzatkényszer:
Háttértudás ∧ Hipotézis ∧ Leírások ⊨ Besorolások
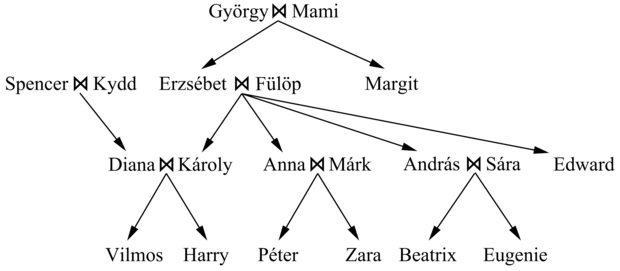
„megoldása” az ismeretlen Hipotézis-re nézve, feltéve, hogy adottak a Háttértudás, valamint a Leírások és a Besorolások által leírt példák. Hogy ezt megvilágítsuk, tekintsük a rokonsági relációk példák alapján történő tanulását. A megfigyeléseket egy kiterjedt családfa képezi, az Anyja, Apja, Házas relációkkal, valamint a Férfi és Nő tulajdonságokkal leírva. A 8.11. feladat családfáját fogjuk használni, amit a 19.11. ábra mutat. A példához tartozó leírások az alábbiak:
Apja(Fülöp, Károly) Apja(Fülöp, Anna) ...
Anyja(Mami, Margit) Anyja(Mami, Erzsébet) ...
Házas(Diana, Károly) Házas(Erzsébet, Fülöp) ...
Férfi(Fülöp) Férfi(Károly) ...
Nő(Beatrix) Nő(Margit) ...
A Besorolások állításai azon múlnak, hogy milyen célfogalmat szeretnénk megtanulni. A célpredikátumok olyan fogalmak lehetnének, mint például a Nagyszülője, a Sógora, illetve az őse. A Nagyszülője esetén a Besorolások teljes halmaza 20 × 20 = 400
Nagyszülője(Mami, Károly) Nagyszülője(Erzsébet, Beatrix) …
¬Nagyszülője(Mami, Harry) ¬Nagyszülője(Spencer, Péter) …
alakú konjunktból áll. Természetesen e teljes halmaz részhalmazából is tudnánk tanulni.
19.10. ábra - Az (a) és (b) ábra a fehérjemolekula összehajtogatásának tárgyterületén a „négy-helikális fel-és-le köteg” fogalom pozitív és negatív példáját mutatja. Mindkét példa struktúráját egy olyan kb. 100 konjunktív tagot tartalmazó logikai kifejezésbe kódolták, mint amilyen például a TeljesHossz(D2mhr, 118) ∧ HelikálisSzám(D2mhr, 6) ∧ … kifejezés.
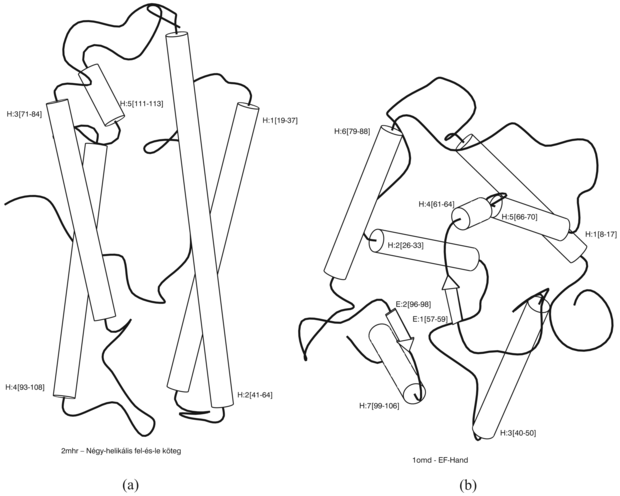
Az ilyen leírásokból és az Összehajtogatás(NÉGY-HELIKÁLIS-FEL-ÉS-LE-KÖTEG, D2mhr) jellegű besorolásokból a PROGOL induktív logikai programrendszer (Muggleton, 1995) az alábbi szabályt tanulta meg:
Összehajtogatás(Négy-Helikális-Fel-és-Le-Köteg, f) ⇐
Helikális(f, cs1) ∧ Hossz(cs1, Magas) ∧ Pozíció(f, cs1, n)
∧ (1 ≤ n ≤ 3) ∧ Szomszédos(f, cs2, cs2) ∧ Helikális(f, cs2)
Ilyen típusú szabályt az előbbi fejezetekben látott, attribútumalapú mechanizmusokkal megtanulni, sőt kifejezni sem lehet. A szabály a természetes nyelvben kifejezve:
Az F fehérje a „Négy-helikális fel-és-le köteg” összehajtogatási osztályhoz tartozik, ha egy hosszú cs1 helikálist tartalmaz a másodlagos struktúra 1. és 3. közötti pozícióban, valamint cs1 a második helikálissal szomszédos.
Az induktív tanuló program tárgya egy olyan állításhalmaz Hipotézis-ként való előállítása, amely a vonzatkényszert kielégíti. Átmenetileg tegyük fel, hogy az ágens nem rendelkezik háttértudással, a Háttértudás üres. Akkor egy lehetséges megoldás a Hipotézis-re a következő:
Nagyszülője(x, y) ⇔[ ∃z Anyja(x, z) ∧ Anyja(z, y)]
[∃z Anyja(x, z) ∧ Apja(z, y)]
[∃z Apja(x, z) ∧ Anyja(z, y)]
[∃z Apja(x, z) ∧ Apja(z, y)]
Vegyük észre, hogy egy attribútumalapú tanuló algoritmus, mint például a DÖNTÉSI-FA-TANULÁS sehogy sem fog ezzel a problémával boldogulni. Ahhoz, hogy a Nagyszülője-t attribútumként (azaz egy unáris predikátumként) fejezzük ki, az embereket párosával objektumként kell tudnunk kezelni:
Nagyszülője(〈Mami, Károly〉)…
Ezek után ott akadunk el, amikor megkíséreljük egy példa leírását formálisan reprezentálni. Csupán olyan elrettentő attribútumokat tudnánk használni, mint az:
ErzsébetAnyjaAzElsőElem(〈Mami, Károly〉)
Fontos
A Nagyszülője-nek az ilyen attribútumokkal kifejezett definíciója nem lesz más, mint egy nagy diszjunkció, ami az egyes konkrét esetekből áll, és amit lehetetlen az új esetekre általánosítani. Az attribútumalapú tanuló algoritmusok képtelenek relációs predikátumokat megtanulni. Az ILP egyik legfontosabb előnye tehát az, hogy a problémák sokkal szélesebb választékában alkalmazhatók, beleértve a relációs problémákat is.
Az olvasó természetesen észreveszi, hogy egy kis háttértudás segítene a Nagyszülője definíciójának reprezentációjánál. Így például, ha a Háttértudás tartalmazná az alábbi állítást:
Szülője(x, y) ⇔ [Anyja(x, y) ⋁ Apja(x, y)]
akkor a Nagyszülője definícióját a:
Nagyszülője(x, y) ⇔ [∃z Szülője(x, z) ∧ Szülője(z, y)]
állításra lehetne redukálni. Ez megmutatja, hogy mennyire tud a háttértudás hozzájárulni a példák megmagyarázásához szükséges hipotézis méretének drasztikus csökkentéséhez.
Az ILP-algoritmus új predikátumokat is létesíthet, hogy a magyarázó jellegű hipotézis kifejezését egyszerűsítse. Az előbbi példát tekintve, teljesen ésszerű egy pótpredikátumot javasolni – amit „Szülője”-nek tudnánk nevezni –, hogy a célpredikátum definícióját egyszerűsítsük. Azok az algoritmusok, amelyek új predikátumokat tudnak létesíteni, az ún. konstruktív indukciós (constructive induction) algoritmusok. Világos, hogy a konstruktív indukció a bevezetőben vázolt kumulatív tanulás egy szükséges komponense. A kumulatív tanulás a gépi tanulás egyik legnehezebb problémája, azonban egyes ILP-technikák kellően hatékony mechanizmusnak bizonyultak a megoldására.
A fejezet hátralévő részében az ILP két alapvető megközelítését fogjuk tanulmányozni. Az első a döntési fák általánosításán, a másik a rezolúciós bizonyítás invertálásán alapul.
Az ILP első megközelítésében egy igen általános szabállyal kezdünk és azt fokozatosan leszűkítjük, hogy az adatokra illeszkedjen. Ez az, ami lényegében a döntési fa tanulásánál történik, ahol a döntési fa fokozatosan növekszik, amíg a megfigyelésekkel konzisztens nem lesz. Hogy az ILP-t magvalósítsuk, elsőrendű literálokat használunk attribútumok helyett, a hipotézis pedig egy klózhalmaz, a döntési fa helyett. Ebben a részben az egyik legelső ILP-programmal, a FOIL-lal foglalkozunk (Quinlan, 1990).
Tegyük fel, hogy továbbra is a Nagyszülője(x, y) predikátum definícióját szeretnénk megtanulni az előbb közölt családi példák alapján. A döntési fa tanulásához hasonlóan a példákat pozitív és negatív példákra bontjuk. A pozitív példák:
〈György, Anna〉, 〈Fülöp, Péter〉, 〈Spencer, Harry〉, …
míg a negatív példák:
〈György, Erzsébet〉, 〈Harry, Zara〉, 〈Károly, Fülöp〉, …
Figyeljük meg, hogy mindegyik példa egy objektumpáros, hiszen a Nagyszülője egy bináris predikátum. Egészét tekintve a családfában 12 pozitív és 388 negatív (a személyek minden más párosítása) példa található.
A FOIL program klózok egy halmazát alakítja ki, mindegyik Nagyszülője(x, y)-nal mint fejjel. A klózoknak a 12 pozitív példát a Nagyszülője(x, y) reláció példányosításának kell osztályozniuk, a többi 388-at viszont kizárni. A klózok Horn-klózok, melyeket negált literálokkal bővítünk ki, ahol a negálást mint kudarcot használjuk, hasonlóan a Prologhoz. Egy üres testű klózzal kezdünk:
⇒ Nagyszülője(x, y)
Mivel ez a választás minden példát pozitívnak sorol be, leszűkítésre szorul. Ez úgy tehető meg, hogy egy lépésben egy literált adunk a bal oldalhoz. A három lehetséges eset:
Apja(x, y) ⇒ Nagyszülője(x, y)
Szülője(x, z) ⇒ Nagyszülője(x, y)
Apja(x, z) ⇒ Nagyszülője(x, y)
(Vegyük észre, hogy a Szülője-t definiáló klózzal a háttértudás már rendelkezik.) E három eset közül az első az összes 12 pozitív példát helytelenül negatívnak sorolja be, így ezt az esetet kizárjuk. A második és a harmadik az összes pozitív példával összhangban van. A második eset azonban a negatív példák nagyobb halmazán – pontosabban kétszer annyi példán – helytelen, mert az anyákat és az apákat is megengedi. Így a választásunk a harmadik esetre esik.
Most az esetet tovább kell szűkíteni, kizárva azokat az eseteket, amikor x valamilyen z szülője, de z mégsem y szülője. Egy egyedi Szülője(z, y) literál hozzáadása a következő klózt eredményezi:
Apja(x, z) ∧ Szülője(z, y) ⇒ Nagyszülője(x, y)
amely az összes példát helyesen sorolja be. A FOIL képes lesz ezt a literált megtalálni és kiválasztani, és ezzel a tanulási feladatot megoldja. Általánosságban, a helyes megoldás megtalálása előtt, a FOIL-nak számos sikertelen klóz között kell keresnie. Ez a példa a FOIL működésének egyszerű illusztrációja. A teljes algoritmus váza a 19.12. ábrán látható. Az algoritmus lényegében literálról literálra egy klózt konstruál, amíg az meg nem egyezik a pozitív példák valamilyen részhalmazával, és egyik negatív példával sem egyezik. A klóz által lefedett pozitív példákat ekkor a tanító halmazból elhagyjuk, és az eljárást folytatjuk, amíg egyetlen pozitív példa sem marad. Az algoritmus két fő komponense szorul magyarázatra – az ÚJ-LITERÁLOK, amely a klózhoz hozzáadandó összes új literált konstruálja, és a LITERÁL-MEGVÁLASZTÁSA, amely kiválasztja a hozzáadandó literált.
19.12. ábra - A
FOIL algoritmus váza, amely példákból elsőrendű Horn-klózokat tanul meg. Az ÚJ-LITERÁLOK és a LITERÁL-MEGVÁLASZTÁSA eljárásokat a szövegben magyarázzuk meg.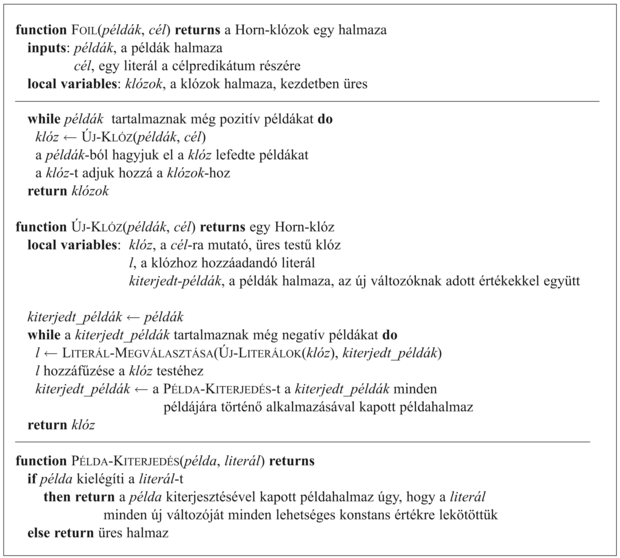
Az ÚJ-LITERÁLOK egy klózt kap bementként, és minden lehetséges „hasznos” literált konstruál, amit a klózhoz hozzá lehetne adni. Vegyük például az alábbi klózt:
Apja(x, z) ⇒ Nagyszülője(x, y)
Háromfajta literált adhatunk hozzá a klózhoz:
-
Predikátumokat használó literálok: a literál lehet negált vagy ponált, minden létező predikátum (a célpredikátumot is beleértve) használható, és minden argumentum csakis változó lehet. A predikátumok argumentumai tetszőleges változók lehetnek, egy kikötéssel: minden literálnak tartalmaznia kell legalább egy változót egy korábbi literálból vagy a klóz fejéből. Olyan literálok, mint: Anyja(z, u), Házas(z, z), ¬Férfi(y) és Nagyszülője(v, x) megengedettek, ám Házas(u, v) nem. Megjegyzendő, hogy a klóz fejéből származó predikátumok használata lehetővé teszi, hogy a
FOILa rekurzív definíciót is megtanulja. -
Egyenlőségi és egyenlőtlenségi literálok: ezek a klózban már szereplő változókat kötik össze. Így például a klózhoz hozzáadhatjuk, hogy: z ≠ x. Ezekben a literálokban a felhasználó által specifikált konstansok is felhasználhatók. Az aritmetikát tanulva célszerű kitüntetni a 0-t és az 1-et, a listafüggvényeknél pedig az üres [] listát.
-
Aritmetikai összehasonlítások: folytonos változójú függvények tanulásánál célszerű lehet az olyan literálok hozzáadása, mint az x > y és az y ≤ z. A döntési fa tanulásához hasonlóan egy konstans küszöbértéket is lehet használni, ami a teszt diszkriminációs erejét maximalizálja.
Mindez a keresési térben nagyon nagy elágazási tényezőhöz vezet (lásd 19.6. feladat), azonban a Foil implementációiban a típusinformációt is fel lehet használni a hipotézistér leszűkítésére. Az embereket és a számokat tartalmazó tárgytartományban például a típusleszűkítés nem engedné, hogy az ÚJ-LITERÁLOK olyan literálokat generáljon, mint a Szülője(x, n), ahol x egy ember, n viszont egy szám.
A LITERÁL-MEGVÁLASZTÁSA az információnyereségre (lásd 18.3.4. szakasz - Attribútumteszt-választás rész) valamilyen mértékben hasonló heurisztikát használ, hogy eldöntse, melyik literált adja hozzá a klózhoz. A részletek itt nem különösen fontosak, ráadásul számos kipróbált változat is létezik. A Foil egyik érdekes járulékos tulajdonsága az Ockham borotvája elvének az alkalmazása bizonyos hipotézisek eliminálására. Ha (egy bizonyos mérték szerint) egy klóz hosszabbnak mutatkozik, mint az általa megmagyarázott pozitív példák összhossza, akkor ezt a klózt a továbbiakban nem tekintjük lehetséges hipotézisnek. Ezzel a technikával elkerülhetjük az adatokban található zajra illeszkedő, túlságosan bonyolult klózok származtatását. A zaj és a klózhossz kapcsolatának magyarázatát lásd a 20.1. szakasz - Statisztikai tanulás részben.
A FOIL-t és társait számos definíció megtanulására vetették be. Az egyik leghatásosabb demonstráció (Quinlan és Cameron-Jones, 1993) a listakezelő függvényekre vonatkozó feladatok hosszú sorának a megoldása volt Bratko Prolog-tankönyvéből (Bratko, 1986). A program mindegyik esetben képes volt a függvény helyes definícióját kisszámú példa alapján megtanulni, miközben háttértudásként használta a korábban megoldott függvényeket.
Az ILP-nek másik fő megközelítése a megszokott deduktív bizonyítási folyamat invertálása. Az inverz rezolúció (inverse resolution) azon az észrevételen alapul, hogy ha a példa Besorolások a Háttértudás ∧ Hipotézis ∧ Leírások-ból következnek, akkor ezt a tényt rezolúcióval be kell tudnunk bizonyítani (hiszen a rezolúció teljes). Ha képesek volnánk a bizonyítást „visszafelé pörgetni”, akkor tudnánk egy olyan Hipotézis-t találni, amire a bizonyítás sikeres lesz. A kulcsprobléma tehát, hogy hogyan tudnánk a rezolúciós eljárást invertálni, hogy a bizonyítás visszafelé fusson le.
Az inverz rezolúció visszafelé haladó bizonyítási eljárását mutatjuk be, amely egyedi visszafelé mutató lépésekből áll. Egy közönséges rezolúciós lépés a C1 és C2 klózból indul ki, és azokat rezolválja egy C rezolvenst létrehozva eredményül. Az inverz rezoluciós lépés a C rezolvens alapján két klózt, C1-et és C2-t hoz létre úgy, hogy C a C1 és C2 rezolválásának az eredménye, vagy pedig C és C1 alapján állít elő egy lehetséges C2-t.
19.13. ábra - Az inverz rezolúciós eljárás kezdő lépései. Az árnyékolt klózokat az inverz rezolúciós eljárás generálja a jobb oldalon és az alatta lévő klózokból. A nem árnyékolt klózok a Leírások-ból és a Besorolások-ból származnak.
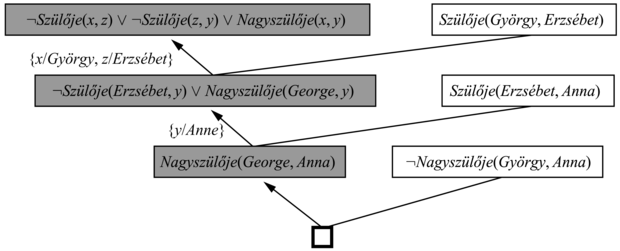
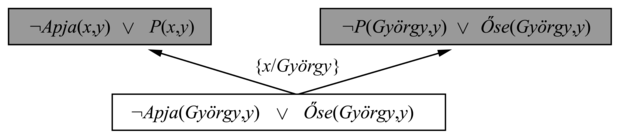
A 19.13. ábra inverz rezolúciós eljárás kezdő lépéseit mutatja, ahol a figyelem középpontjában a Nagyszülője(György, Anna) pozitív példa áll. Az eljárás a bizonyítás végén kezd (amit az ábra alján ábrázolunk). A C rezolvensnek üres klózt (azaz egy ellentmondást) választunk, C2-nek pedig a ¬Nagyszülője(György, Anna)-t, amely a célpélda negálása. Az első inverz lépés C-ből és C2-ből C1-nek a Nagyszülője(György, Anna)-t generálja. A következő lépés e klózt C-nek veszi, a Szülője(Erzsébet, Anna) klózt pedig C2-nek, és az alábbi C1 klózt generálja:
¬Szülője(Erzsébet, y) ∨ Nagyszülője(György, y)
Az utolsó lépés ezt a klózt rezolvensként kezeli. A Szülője(György, Erzsébet) klózt C2-nek véve, egy lehetséges C1 klóz az alábbi hipotézis lehet:
Szülője(x, z) ∧ Szülője(z, y) ⇒ Nagyszülője(x, y)
Egy rezolúciós bizonyításunk van tehát arra, hogy a hipotézis, a leírások és a háttértudás maga után vonzza a Nagyszülője(György, Anna) osztályozást.
Világos, hogy az inverz rezolúció keresést tartalmaz. Minden egyes inverz rezolúciós lépés nemdeterminisztikus, hiszen az adott C és C1-hez több, sőt végtelen sok olyan C2 klóz lehet, amely kielégíti azt a feltételt, miszerint C1-gyel rezolválva C-t ad eredményül. Így a 19.13. ábra utolsó lépésében a ¬Szülője(Erzsébet, y) ∨ Nagyszülője(György, y) megválasztása helyett az inverz rezolúciós lépés a következő állításokat is tudná generálni:
¬Szülője(Erzsébet, Anna) ∨ Nagyszülője(György, Anna)
¬Szülője(z, Anna) ∨ Nagyszülője(György, Anna)
¬Szülője(z, y) ∨ Nagyszülője(György, y)
(Lásd a 19.4. és a 19.5. feladatot.) Az egyes lépésekben részt vevő klózokat meg lehet választani a Háttértudás-ból, a példa Leírások-ból, a negált Besorolások-ból vagy az inverz rezolúciós fában eddig már legenerált hipotézisklózokból. A nagyszámú lehetőség, egyéb kontroll nélkül, nagy elágazási tényezőt (és így kevéssé hatékony keresést) jelent. A keresés kézben tartására több megközelítést probáltak ki az implementált ILP-rendszerekben:
-
A redundáns választások eliminálhatók – például a legspecifikusabb lehetséges hipotézisek generálásával, valamint megkövetelve, hogy a hipotézisklózok mind konzisztensek legyenek egymással és a megfigyelésekkel. Az utolsó kritérium kizárná az előbbiekben megadott ¬Szülője(z, y) ∨ Nagyszülője(György, y) klózt.
-
A bizonyítási stratégia szintén megszorítható. A 9. fejezetben láttuk például, hogy a lineáris rezolúció (linear resolution) egy teljes, megszorított stratégia, amely lehetővé teszi, hogy a bizonyítási fáknak csak lineáris elágazási struktúrája lehessen (mint a 19.13. ábrán).
-
A reprezentációs nyelv is megszorítható, a függvényszimbólumok eliminálásával és csak Horn-klózokat megengedve. A
PROGOLpéldául Horn-klózokkal dolgozik, inverz vonzatrelációt (inverse entailment) alkalmazva. Az ötlet a
Háttértudás ∧ Hipotézis ∧ Leírások ⊨ Besorolások
vonzatkényszer megváltoztatása a
Háttértudás ∧ Leírások ∧ ¬Besorolások ⊨ ¬Hipotézisek
logikailag ekvivalens formára.
Ebből a Hipotézisek származtatására már a Prolog-beli normál Horn-klóz dedukcióra hasonlító módszert használhatjuk, negálással mint kudarccal. Mivel ez Horn-klózokra korlátozott, így nem teljes módszer, azonban a teljes rezolúciónál hatékonyabb lehet. Inverz vonzatrelációval lehetséges a teljes következtetés alkalmazása is (Inoue, 2001).
-
A következtetést modellellenőrzéssel is megvalósíthatjuk a tételbizonyítás helyett. A
PROGOLrendszer (Muggleton, 1995) a modellellenőrzés egy formáját használja kereséskorlátozás céljára. Azaz, hasonlóan a válaszhalmaz-programozáshoz, a logikai változók lehetséges értékeit generálja, és a konzisztenciát ellenőrzi. -
A következtetést az alap ítéletklózokkal is megtehetjük az elsőrendű logika helyett. A
LINUS-rendszerben (Lavrac és Dzeroski, 1994) az elsőrendű elméleteket ítéletlogikára fordítják le, ítéletlogikai tanuló rendszerrel oldják meg azokat, majd visszafordítják. Egyes problémák esetén ítéletlogikai állításokkal sokkal hatékonyabban lehet dolgozni, ahogy ezt a 11. fejezetben aSATPLANesetében már láttuk.
Egy teljes rezolúciós stratégiát invertáló inverz rezolúciós eljárás elvben az elsőrendű elméletek tanulásának egy teljes algoritmusa. Ez azt jelenti, hogy ha valamely ismeretlen Hipotézis egy sor példát generál, akkor az inverz rezolúciós eljárás a példákból tudja generálni a Hipotézis-t. Ez a megfigyelés egy érdekes lehetőséget is sugall. Tegyük fel, hogy a rendelkezésre álló példák szabadon eső testek által leírt trajektóriák egy halmazát tartalmazzák. Lehetséges, hogy egy inverz rezolúciós program elvben képes a gravitáció törvényét megtanulni? A válasz természetesen igen, mert a gravitáció törvénye, megfelelő matematikai háttér mellett, lehetővé teszi a példák magyarázatát. Hasonlóképpen el lehet képzelni, hogy az elektromágneses hullámok elmélete, a kvantummechanika és a relativitáselmélet, mind beletartoznak az ILP-programok hatáskörébe. Persze a gépíró majom hatáskörébe is beletartoznak; jobb heurisztikákra és a keresési teret jobban strukturáló technikákra még mindig szükség van.
Egy dolgot azért az inverz rezolúciós rendszer meg fog tenni a részünkre: új predikátumokat fog kitalálni. Ez a képessége kissé mágikusnak tűnik, hiszen a számítógépre szokás úgy tekinteni, mint ami „csak azzal dolgozik, amit bemenetként kapott”. Tény, hogy az új predikátumok egyenesen az inverz rezolúciós lépésből pottyannak ki. A legegyszerűbb az az eset, amikor egy adott C klóz esetén két új klóz, C1 és C2 létezését kellene felvetni. A C1 és C2 rezolúciója a két klóz által közösen tartalmazott literált eliminálta, lehetséges hát, hogy az eliminált literálban olyan predikátum is szerepelt, amely C-ben már nem lép fel. Visszafelé haladva tehát lehetőségként adódik egy új predikátum létrehozása, amiből viszont a hiányzó literál már rekonstruálható.
A 19.14. ábra arra mutat példát, ahogy az Őse definíciójának tanulása közben egy új P predikátumot generálunk. Ha már előállítottuk a P-t, akkor ez használható az inverz rezolúció későbbi lépéseiben is. Egy későbbi lépés például feltételezheti, hogy az Anyja(x, y) ⇒ P(x, y). Az új predikátum jelentését így a predikátumot felhasználó hipotézis generálása korlátozza. Egy másik példa elvezethet az Apja(x, y) ⇒ P(x, y)-ig. Más szóval a P predikátum olyan valami, ami minket általában a Szülője relációra emlékeztet. Korábban említettük, hogy új predikátumok bevezetése a célpredikátum definíciójának a méretét lényegesen csökkentheti. Az új predikátumok kialakításának beépített képességével, az inverz rezolúciós rendszer sokszor olyan tanulási problémákkal is megbirkózik, amelyekre más módszerek alkalmatlanok.
A tudomány legmélyebbre ható forradalmai új predikátumok és függvények bevezetésével függnek össze, ilyen például a Galilei felfedezte gyorsulás vagy Joule termikus energiája. Ha ezek a fogalmak már adottak, az új törvények felfedezése (viszonylag) egyszerű. A fő nehézség arra rájönni, hogy egy új entitás bevezetése, amely a létező entitásokkal meghatározott konkrét kapcsolatban van, lehetővé teszi a megfigyelések egész halmazának a korábban lehetségesnél sokkal egyszerűbb és elegánsabb elmélet keretein belül történő magyarázatát.
Az ILP-rendszerek egyelőre Galilei- vagy Joule-szintű felfedezéseket nem tettek, a felfedezéseit azonban tudományos irodalomban való publikálásra érdemesnek találták. Így például Journal of Molecular Biology-ban Turcotte írja le a fehérje összehajtogatási szabályok automatikus felfedezését a PROGOL ILP programmal (Turcotte és társai, 2001). A Progol által felfedezett szabályok közül sokat az ismert elvekből ugyan le lehetett volna következtetni, a többségét azonban a standard biológiai adatbázisok részeként korábban mégsem publikálták (lásd 19.10. ábra példája). Egy ehhez kapcsolódó kutatás részeként Srinivasan (Srinivasan és társai, 1994) molekula-struktúraalapú szabályok felfedezésével foglalkozott nitroaromatikus komponensek mutagenicitására. Ilyen komponensek a gépkocsik által kibocsátott kipufogógázban találhatók. A standard adatbázisokban lévő komponensek 80%-ában lehetséges a négy fontos jellemzőt azonosítani, és az erre épülő lineáris regresszió jobb az ILP-nél. A maradék 20% esetén a jellemzők önmagukban nem elegendők az előrejelzéshez, az ILP relációkat azonosít, amelyekkel a lineáris regresszió, a neurális hálók és a döntési fák képességein túltesz. King (King és társai, 1992) azt mutatta meg, hogy a különböző gyógyszerek gyógykezelési hatását hogyan lehetne előre jelezni. Ezen esetek mindegyikében úgy tűnik, hogy az ILP nagy hatékonyságához a relációk reprezentálási képessége és a háttértudás használata járulnak hozzá. Az a tény, hogy az ILP által megtalált szabályokat az emberek is képesek interpretálni, inkább segíti ezeknek a technológiáknak az elfogadását a biológiai folyóiratokban, mint a számítógépes tudománnyal foglalkozó folyóiratokban.
Az ILP a biológián túl más tudományokhoz is hozzájárult. A legfontosabbak egyike a természetes nyelvfeldolgozás, ahol az ILP-t komplex relációs információ szövegekből való kinyerésére alkalmazták. Ezeket az eredményeket a 23. fejezet foglalja össze.
[192] Azt javasoljuk, hogy ezen a ponton az olvasó ismételten fusson végig a 9. fejezetben bemutatott néhány fogalmon, beleértve a Horn-klózokat, a konjunktív normál formát, az egyesítést és a rezolúciót.
