20.1. Statisztikai tanulás
Az ebben a fejezetben használt alapvető koncepciók ismét az adat (data) és a hipotézis (hypothesis), éppúgy, mint ahogy a 18. fejezetben volt. Itt az adatok a tények (evidence) – ezek a területet leíró valószínűségi változók egy részének vagy mindegyikének egy konkrét megvalósulását jelentik. A hipotézis valamilyen valószínűségi elmélet arról, hogy a világ adott területe hogyan is működik, ennek speciális esetei a logikai elmélettel leírt területek.
Vegyünk egy nagyon egyszerű példát. Kedvenc „meglepetés” cukorkánk kétféle, meggy- (nyam-nyam) és citrom- (brrrr) ízben kapható. A cukorkagyártónak sajátos humora van, és mindegyik cukorkát – ízétől függetlenül – ugyanolyan átlátszatlan papírba csomagolja. Az édességet nagyon nagy zsákokban árulják, amelyekből ötféle van – kívülről megint csak megkülönböztethetetlenek egymástól:
h1: 100% meggy
h2: 75% meggy + 25% citrom
h3: 50% meggy + 50% citrom
h4: 25% meggy + 75% citrom
h5: 100% citrom
Egy adott új zsák cukorka esetén a H (hipotézist jelölő) véletlen változó a zsák típusát jelenti, lehetséges értékei h1-től h5-ig terjednek. Természetesen H közvetlenül nem figyelhető meg. Ahogy a cukorkákat felbontjuk és megvizsgáljuk, adatokat gyűjtünk – amelyeket D1, D2, …, DN jelöl. Mindegyik Di egy olyan véletlen változó, amelynek lehetséges értékei a meggy, illetve a citrom. Az ágens feladata, hogy jóslást adjon a következő cukorka ízére.[194] Ez a nyilvánvalóan triviális feladat érdekes módon mégis jó betekintést nyújt a legfontosabb problémák közül többre is. Az ágensnek valóban elméletet kell alkotnia a világról, bár csak nagyon egyszerűt.
A Bayes-tanulás (Bayesian learning) során egyszerűen kiszámítjuk minden egyes hipotézis valószínűségét az adatokra támaszkodva, majd ennek alapján adunk predikciót. Azaz nem egyetlen „legjobb” hipotézist használunk a predikcióhoz, hanem az öszszes hipotézist használjuk, valószínűségükkel súlyozva őket. Reprezentálja D az összes adatot, legyen d a megfigyelt értékek vektora, ekkor az egyes hipotézisek valószínűségét a Bayes-szabállyal adhatjuk meg:
P(hi|d) = αP(d|hi)P(hi) (20.1)
Tegyük fel, hogy egy ismeretlen X mennyiségre vonatkozó predikció a célunk. Ebben az esetben:
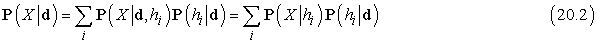
ahol azt feltételeztük, hogy az összes hipotézis meghatároz X-re valamilyen eloszlást. Ez az összefüggés azt mutatja, hogy a predikció az egyes hipotézisekből adódó predikciók súlyozott összege. Maguk a hipotézisek tulajdonképpen a nyers adatok és a predikciók közti „közvetítők”. A Bayes-megközelítésben a P(hi) prior hipotézisek (hypothesis prior), illetve a hipotézisek mellett fellépő P(d|hi) adatvalószínűségek (likelihood) a kulcsmennyiségek.
A cukorka példánkban azt feltételezzük, hogy a h1,…, h5 a priori valószínűségei megfelelnek a gyártó reklámjában közölt 〈0,1, 0,2, 0,4, 0,2, 0,1〉 értékeknek. Az adatok valószínűségét e.f.e (angol rövidítése: i.i.d.) feltételezéssel számítjuk – azaz egyforma és független eloszlást (independently and identically distributed) teszünk fel, így:

Tegyük fel például, hogy a cukorkás zsák valójában csupa citromtípusú (h5), és az első 10 kibontott cukorka mind citromízű, ekkor P(d|h3) = 0,510, mivel a h3 típusú zsákokban a cukorkák fele citrom.[195] A 20.1. (a) ábra mutatja, hogyan változik az öt hipotézis a posteriori valószínűsége, ahogy sorban észleljük a 10 citromízű cukorkát. Vegyük észre, hogy a valószínűségek az a priori értékekről indulnak, ennek megfelelően kezdetben h3 a legvalószínűbb lehetőség, és ez így is marad még az első cukor felbontása után is. A második citromízű cukorka felbontása után h4 a legvalószínűbb, 3 és több esetén h5 (a rettegett csupa citrom zsák). 10 citromízű cukorka után már meglehetősen biztosak vagyunk végzetünket illetően. A 20.1. (b) ábra mutatja annak a (20.2) egyenlet alapján jósolt valószínűségét, hogy a következő cukorka citromízű. Várakozásunknak megfelelően monoton növekszik az 1 felé.
20.1. ábra - (a) A (20.1) egyenletből számított P(hi|d1,…,dN) a posteriori valószínűségek. A megfigyelések száma 1-től 10-ig terjed, és mindegyik megfigyelés citromízű cukorka. (b) A (20.2) egyenlet alapján számított P(dN+1 = citrom|d1,…,dN) Bayes-predikció.
Fontos
Példánk azt mutatja, hogy a Bayes-predikcióban az igaz hipotézis végülis dominánssá válik. Ez jellemző a Bayes-tanulásra. Bármilyen rögzített priorra, amely nem zárja ki a helyes megoldást, a hamis hipotézisek a posteriori valószínűsége végülis nullához tart. Ennek egyszerűen az az oka, hogy elhanyagolhatóan kicsi annak valószínűsége, hogy végtelen ideig „nem jellemző” adatokat generáljunk. (Ezen a ponton érvelésünk hasonló a 18. fejezetben, a VKH-tanulásnál alkalmazottal.) Ennél is fontosabb, hogy a Bayes-predikció optimális, akár kicsi, akár nagy adathalmazunk van. Adott a priori hipotéziseloszlás mellett bármely más predikció ritkábban lesz helyes, mint a Bayes-predikció.
A Bayes-tanulás optimalitásának természetesen ára van. Mint a 18. fejezetben láttuk, a valós tanulási problémáknál a hipotézistér rendszerint nagyon nagy vagy végtelen. Néha a (20.2) egyenletben az összegzés (vagy folytonos esetben az integrálás) pontos elvégzése kezelhető problémára vezet, de a legtöbb esetben közelítő vagy egyszerűsített megoldásokra kell szorítkoznunk.
Nagyon elterjedt approximációs módszer – a tudományos feladatokban rendszerint ezt alkalmazzuk –, hogy egyetlen, a legvalószínűbb hipotézis alapján végezzük a predikciót, azaz olyan hi alapján, amely maximálja a P(hi|d)-t. Ezt maximum a posteriori vagy MAP hipotézisnek nevezzük. A MAP hipotézis alapján végzett predikciók közelítőleg Bayes-predikciók. Ez a közelítés annyira jó, amennyire jó a P(X|d) ≈ P(X|hMAP közelítés. A cukorka példánkban három egymás utáni citromízű cukor észlelése után hMAP = h5, így a MAP-tanulás alapján a negyedik cukorra 1,0 valószínűséggel citromízűt jósolunk. Ez nyilván sokkal veszélyesebb jóslat, mint a Bayes-predikció, amely 0,8valószínűségű, ahogy a 20.1. ábrán is láthatjuk. Ahogy egyre több adatunk van, a MAP és Bayes-predikciók egyre inkább konvergálnak egymáshoz, mivel a MAP hipotézis alternatívái egyre kevésbé valószínűvé válnak. Bár példánk ezt nem mutatja, de a MAP hipotézis előállítása sokszor lényegesen egyszerűbb, mint a Bayes-tanulásé. Ennek oka, hogy csupán egy optimalizálási probléma megoldását igényli, szemben egy nagyon nagy összegzési (vagy integrálási) problémával. A fejezet későbbi részében majd látunk példákat erre.
Mind a Bayes-tanulásban, mind a MAP-tanulásban a P(hi) a priori hipotézis valószínűségek nagy szerepet játszanak. Láttuk a 18. fejezetben, hogy túlilleszkedés (overfitting) léphet fel, ha túlzottan nagy a hipotézistér kifejezőképessége, vagyis túl sok olyan hipotézist tartalmaz, amely jól illeszkedik az adatokra. A Bayes- és a MAP-tanulás nem alkalmaz valamilyen önkényes korlátot a figyelembe vett hipotézisekre, inkább az a priori valószínűségeket használják fel arra, hogy büntessék a hipotézisek komplexitását. A komplex hipotéziseknek tipikusan kisebb az a priori valószínűsége – részben azért, mert sokkal több komplex hipotézis van, mint egyszerű. Másrészről a komplex hipotéziseknek nagyobb kapacitása van az adatokra való illeszkedéshez. (Extrém esetet véve egy táblázat 1,0 valószínűséggel és tökéletes pontossággal reprodukálni tudja az adatokat.) Ennek megfelelően az a priori valószínűségben testesül meg a hipotéziskomplexitás és az adatokra való illeszkedési képesség közötti kompromisszum.
Fontos
Ezt a kompromisszumot a logikai esetben figyelhetjük meg legjobban, amikor is H csak determinisztikus hipotéziseket tartalmaz. Ebben az esetben P(d|hi) értéke akkor 1, ha hi konzisztens az adatokkal, különben 0. A (20.1) egyenlet alapján azt látjuk, hogy hMAP a legegyszerűbb logikai hipotézis lesz, amely konzisztens az adatokkal. Tehát a maximum a posteriori tanulás Ockham borotvájának egy természetes megvalósulása.
A hipotéziskomplexitás és az adatokra való illeszkedési képesség közötti kompromisszumot új módon világítja meg, ha a (20.1) egyenlet logaritmusát képezzük. A hMAP hipotézis olyan kiválasztása, amely maximálja a P(d|hi)P(hi)-t ugyanaz, mint amikor minimalizáljuk a következő kifejezést:
–log2P(d|hi) –log2P(hi)
Használjuk fel az információkódolás és a valószínűség között a 18. fejezetben bevezetett kapcsolatot. Azt látjuk, hogy a –log2P(hi) tag nem más, mint a hi hipotézis specifikálásához szükséges bitek száma. A –log2 P(d|hi)-tag viszont azoknak a további biteknek a száma, amelyek ahhoz szükségesek, hogy az adott hipotézis feltételezésével specifikáljuk az adatokat. (Ennek demonstrálására mutatjuk be azt az esetet, amikor a hipotézis pontosan megjósolja az adatokat, ilyenkor nincs szükség egyetlen bitre sem az adatok specifikálásához. Ilyen például a h5 hipotézis esete, amikor sorban érkeznek a citromízű cukorkák – és valóban log2 1 = 0.) Ebben az értelemben a MAP-tanulás jellemzője, hogy maximálisan tömöríti az adatokat. Ezt a feladatot sokkal közvetlenebbül célozza a minimális hosszúságú leírás (MHL) (minimum description length, MDL) tanulási módszer, amely a valószínűségekkel való foglalkozás helyett a hipotézis méretének és az adat kódolásának minimalizálására törekszik.
Az utolsó egyszerűsítést az adja, ha a hipotézistérben egyenletes (uniform) priort feltételezünk. Ebben az esetben a MAP-tanulás egy olyan hi választására redukálódik, amely maximálja P(d|hi) -t. Ezt maximum-likelihood (ML) hipotézisnek nevezzük, és hML-lel jelöljük. A maximum-likelihood tanulás nagyon elterjedt a statisztikában. Ez egy olyan tudomány, amelynek sok kutatója nem bízik az a priori hipotézisek szubjektív természetében. Ez józan megközelítés akkor, amikor nincs semmi okunk, hogy apriori kitüntessük az egyik hipotézist egy másikkal szemben, például amikor az öszszes hipotézis egyformán komplex. Az ML-tanulás jó közelítését adja a Bayes- és MAP-tanulásnak olyankor, amikor az adathalmaz nagy, hiszen az adatok végül is felülírják a hipotézisek a priori eloszlását, de kis adathalmazok esetén problémák merülnek fel az alkalmazásánál (mint látni fogjuk).
[194] A statisztikában jártasabb olvasó felismeri, hogy ez a példa valójában az urna és golyó (urn and ball) feladat változata. Úgy találtuk, hogy az urna és a golyó kevesebb kihívást jelent, mint a cukorka, továbbá a cukorka példa elvezet egy másik feladathoz – elcseréljük-e a zacskót egy barátunkkal, vagy sem (lásd 20.3. feladat).
[195] Korábbiakban leszögeztük, hogy a cukorkás zsákok nagyon nagyok, másképp az e.f.e. feltétel nem áll fenn. Korrektebb lenne (de kevésbé higiénikus) feltételezni, hogy minden vizsgálat, kóstolás után visszacsomagoljuk a cukorkát, és visszatesszük a zsákba.
