18.3. Döntési fák megalkotása tanulással
A döntési fa tanulás egyike a legegyszerűbb, mégis az eddigiekben az egyik legsikeresebbnek bizonyult tanulási algoritmusnak. Jó bevezetésként szolgál az induktív tanulás területén, és ráadásul könnyen implementálható. Először bemutatjuk a cselekvő alrendszert, majd megmutatjuk, hogy miképpen lehet tanítani. Mindeközben olyan elveket mutatunk be, amelyek az induktív tanulás minden területére jellemzők.
Egy döntési fa (decision tree) bemenetként egy attribútumokkal (attributes) leírt objektumot vagy szituációt kap, és egy „döntést” ad vissza eredményként – a bemenetre adott válasz jósolt értékét. A bemeneti attribútumok lehetnek diszkrétek vagy folytonosak. Jelen tárgyalásban diszkrét bemeneteket tételezünk fel. A kimeneti érték szintén lehet diszkrét vagy folytonos; egy diszkrét értékkészletű függvény tanulását osztályozás (classification) tanulásnak, míg a folytonos függvény tanulását regressziónak (regression) nevezzük. Bináris (Boolean) osztályozásra fogunk koncentrálni, ahol minden példát vagy igaznak (pozitív), vagy hamisnak (negatív) sorolunk be.
A döntési fa egy tesztsorozat elvégzése során jut el a döntéshez. A fa minden egyes belső csomópontja valamely tulajdonság értékére vonatkozó tesztnek felel meg, a csomópontból kilépő ágakat pedig a teszt lehetséges kimeneteivel címkézzük. Minden egyes levélcsomópont megadja azt az értéket, amelyet vissza kell adnunk, ha ezt a levelet elértük. Úgy tűnik, hogy a döntési fa reprezentáció az emberek számára rendkívül természetes; valójában számos „Hogyan csináljuk?” kézikönyvet (például az autójavítási kézikönyveket) írtak meg egyetlen hatalmas, több száz oldalra kiterjedő döntési faként.
Valamelyest egyszerűbb példa lehet az a probléma, hogy várjunk-e egy étteremben egy asztal felszabadulására. Az a célunk, hogy tanulással kialakítsuk a VárjunkE célpredikátum (goal predicate) definícióját. Ahhoz, hogy ezt tanulási feladatként kezelhessük, először meg kell határozzuk, hogy milyen attribútumok állnak rendelkezésre ahhoz, hogy ezen a problématerületen leírjuk a példákat. A 19. fejezetben megmutatjuk, hogyan lehet automatizálni ezt a feladatot; most egyszerűen tegyük fel, hogy a következő attribútumlista mellett döntöttünk:
-
Alternatíva: van-e a közelben megfelelő alternatívaként kínálkozó étterem.
-
Bár: van-e az étteremnek kényelmes bár része, ahol várakozhatunk.
-
Péntek/Szombat: igaz értéket vesz fel pénteken és szombaton.
-
Éhes: éhesek vagyunk-e.
-
Vendégek: hány ember van az étteremben (értékkészlet Senki, Néhány és Tele).
-
Drága: az étterem menyire drága ($, $$, $$$).
-
Eső: esik-e odakint az eső.
-
Foglalás: foglaltunk-e asztalt.
-
Konyha: az étterem típusa (francia, olasz, thai vagy burger).
-
BecsültVárakozás: a pincér becsülte várakozási idő (0–10, 10–30, 30–60, >60 perc)
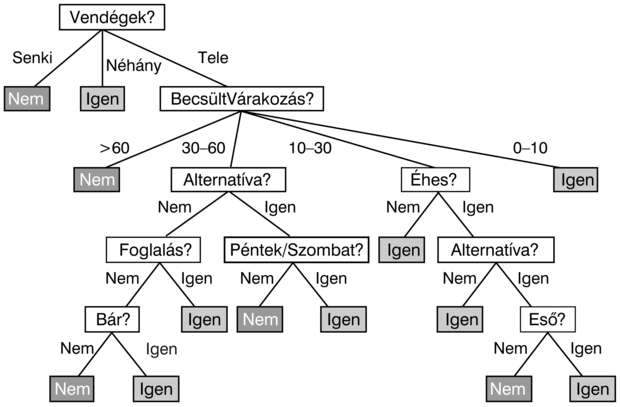
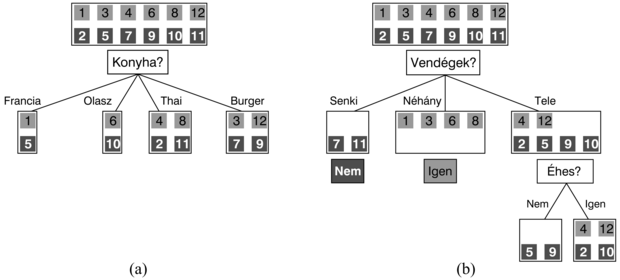
A szerzők egyike (SR) által erre a problémára rendszerint használt döntési fa a 18.2. ábrán látható. Vegyük észre, hogy a fa nem használja a Drága és a Konyha attribútumokat, valójában irrelevánsnak tekinti azokat. A példákat a döntési fa a gyökérnél kezdi feldolgozni, követi a megfelelő ágakat, amíg egy levélhez el nem ér. Például egy Vendégek = Tele és BecsültVárakozás = 0–10 attribútumokkal jellemezhető példa pozitív kimenetet fog eredményezni (azaz várni fogunk egy asztalra).
Logikai felírást használva minden egyes döntési fa, amely a VárjunkE célpredikátum egy hipotézise, a következő formában felírt állításnak felel meg:
∀s VárjunkE(s) ⇔ (P1(s) ∨ P2(s) ∨ … ∨ Pn(s))
ahol mindegyik Pi(s) feltétel azon tesztek konjunkciójának felel meg, amelyeket a gyökértől egy pozitív kimenetet jelentő levélig megtett út során végeztünk. Bár ez egy elsőrendű logikában felírt mondatnak tűnik, valójában bizonyos értelemben ítéletlogikai kifejezés, mivel csak egyetlen változót tartalmaz és az összes predikátum unáris. Valójában a döntési fa a VárjunkE és az attribútumértékek bizonyos logikai kapcsolatát írja le. A döntési fa nem használható olyan tesztek reprezentálására, amelyek kettő vagy több különböző objektumra vonatkoznak – például:
∃r2 Közel(r2, r) ∧ Drága(r, p) ∧ Drága(r2, p2) ∧ Olcsóbb(p2, p)
(van a közelben egy olcsóbb étterem?). Nyilvánvalóan felvehetnénk egy OlcsóbbÉtteremKözel nevű logikai attribútumot, de az összes ilyen attribútum hozzáadása kezelhetetlenné teszi a problémát. A 19. fejezet mélyebbre hatol az elsőrendű logikában történő tanulás területén.
Az ítéletlogikai nyelvek területén a döntési fák teljes kifejezőképességgel bírnak, ami azt jelenti, hogy tetszőleges logikai (Boole) függvény felírható döntési faként. Ezt triviálisan megvalósíthatjuk, ha a függvény igazságtáblájának minden sorát megfeleltetjük a döntési fa egy útjának. Ez exponenciálisan növekvő döntési fára vezet, mivel az igazságtábla exponenciálisan növekvő számú sort tartalmaz. Nyilvánvalóan a döntési fák sok függvényt jóval kisebb fával képesek reprezentálni.
Ugyanakkor némely függvényfajtánál ez valóban problémát jelent. Például ha a függvényünk a paritásfüggvény (parity function), amely akkor és csak akkor ad 1-et, ha páros számú bemenet 1 értékű, akkor egy exponenciálisan nagy döntési fára lesz szükség. Hasonlóan nehéz a többségfüggvény (majority function) reprezentálása döntési fával, amely függvény akkor ad 1-et, ha bemeneteinek több mint fele 1 értékű.
Más szavakkal, a döntési fák bizonyos függvények esetén jók, mások esetén roszszak. Van bármilyen olyan reprezentáció, amely mindenfajta függvény esetén hatékony? A válasz sajnos az, hogy nincs. Ezt általánosan is meg tudjuk mutatni. Vizsgáljuk az összes n bemeneti attribútummal rendelkező logikai (Boole) függvényt. Hány különböző függvény van ebben a halmazban? Ez éppen a lehetséges felírható igazságtáblák számával egyezik meg, hiszen egy függvényt az igazságtáblája ad meg. Az igazságtáblának 2n sora van, mivel minden bemeneti esetet n attribútummal adunk meg. Úgy tekinthetjük a tábla „válasz” oszlopát, mint egy 2n bites számot, amely definiálja a függvényt. Mindegy, hogy a függvények milyen reprezentációját választjuk, néhánynak (valójában szinte mindegyiknek) a reprezentálásához tényleg szükség lesz ennyi bitre.
Ha 2n bitre van szükség a függvény megadásához, akkor n attribútum esetén 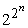 a lehetséges függvények száma. Ez megrázóan nagy szám. Például csupán hat Boole-változó esetén is
a lehetséges függvények száma. Ez megrázóan nagy szám. Például csupán hat Boole-változó esetén is 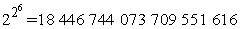 különböző logikai (Boole) függvény állítható elő. Szükségünk lesz néhány szellemes algoritmusra, hogy egy ilyen hatalmas térben konzisztens hipotézist tudjunk találni.
különböző logikai (Boole) függvény állítható elő. Szükségünk lesz néhány szellemes algoritmusra, hogy egy ilyen hatalmas térben konzisztens hipotézist tudjunk találni.
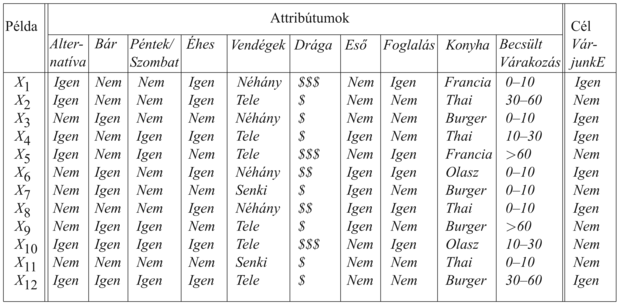
Egy logikai döntési fa által kezelhető példa a bemeneti attribútumok X vektorából és egyetlen logikai kimeneti értékből, y-ból áll. A 18.3. ábra egy (X1, y1)...( X12, y12) példahalmazt mutat. Azokat nevezzük pozitív példáknak (X1, X3, ...), amelyekben a VárjunkE értéke igaz, és azok a negatív példák, amelyekben az értéke hamis (X2, X5, …). A példák teljes halmazát tanító halmaznak (training set) nevezzük.
Az a probléma, hogy a tanító halmaznak megfelelő döntési fát találjunk, bonyolultnak tűnik ugyan, de valójában van egy triviális megoldása. Egyszerűen egy olyan fát konstruálhatunk, amelyben minden példához egy külön saját utat hozunk létre egy – a példához tartozó – levélcsomóponthoz. A levélhez vezető út mentén sorra teszteljük az attribútumokat, és a példához tartozó tesztértéket követjük, a levél pedig a példa besorolását adja. Ha ismét ugyanazt a példát[183] vesszük, akkor a döntési fa a helyes osztályozási eredményt adja. Szerencsétlen módon nemigen ad információt egyetlen más esetről sem!
Ezzel a triviális megoldással az a baj, hogy egyszerűen memorizálja a példákat. Mivel nem nyer ki semmilyen mintázatot a példákból, ezért nem várhatjuk, hogy extrapolálni tudjon azokra a mintákra, amelyeket még sohasem látott. Az Ockham borotvája elvét alkalmazva nekünk azt a legkisebb döntési fát kell megtalálnunk, amely konzisztens a példákkal. Sajnálatos módon a „legkisebb” összes értelmes definíciója esetén a legkisebb döntési fa megtalálása kezelhetetlen problémát jelent. Viszont némi egyszerű heurisztika bevetésével jó eredményt érhetünk el egy „kicsike” fa megtalálásában. A DÖNTÉSI-FA-TANULÁS algoritmus alapötlete az, hogy teszteljük először a legfontosabb attribútumot. A „legfontosabb” alatt azt az attribútumot értjük, amelyik a legnagyobb változást okozza a példák besorolásában. Ezen a módon – reményünk szerint – kisszámú teszttel helyes osztályozáshoz jutunk, ami azt jelenti, hogy a fában minden út rövid lesz, tehát az egész fa kicsi lesz.
A 18.4. ábrán látható, hogy hogyan indul az algoritmus. 12 példánk van, amelyeket pozitív és negatív példahalmazokba sorolunk. Ezek után eldöntjük, hogy melyik attribútumot teszteljük először a fában. A 18.4. (a) ábrán megmutattuk, hogy a Konyha attribútum rossz választás lenne, mert tesztjének 4 kimenetele van, és mindegyik esetén ugyannyi pozitív és negatív példánk lesz az eredményül kapott halmazokban. Másrészt viszont a 18.4. (b) ábrán látható, hogy a Vendégek egy meglehetősen fontos attribútum, hiszen ha értéke Senki vagy Néhány, akkor határozott választ tudunk adni (az első esetben Nem, a másodikban Igen a válaszunk). Ha az attribútum értéke Tele, akkor a példák vegyes halmazát kapjuk. Általánosságban megállapítható, hogy miután az első attribútum tesztje csoportokra bontotta a példákat, mindegyik teszteredmény egy újabb döntési fa tanulási problémát eredményez, kevesebb példával és egygyel kevesebb attribútummal. Négy esetet kell áttekintenünk ezekben a rekurzív problémákban:
-
Ha van néhány pozitív és néhány negatív példánk, akkor válasszuk a legjobb attribútumot a szétosztásukra. A 18.4. (b) ábrán bemutattuk, hogy az Éhes attribútum alkalmas a megmaradó példák osztályozására.
-
Ha valamennyi megmaradt példánk pozitív (vagy mind negatív), akkor készen vagyunk: válaszolhatunk Igen-t vagy Nem-et. A 18.4. (b) ábra bemutatja ezt a Senki, illetve a Néhány esetekben.
-
Ha nem marad példa a teszt egyik kimenetele esetén, akkor ez azt jelenti, hogy nem figyeltünk meg ilyen esetet, és a szülőcsomópontban többségben levő választ adjuk.
-
Ha nem maradt attribútumunk, amelyet tesztelhetnénk, de mind pozitív, mind negatív példáink maradtak, akkor bajban vagyunk. Ez azt jelenti, hogy ezeknek a példáknak pontosan azonos jellemzőik vannak, de különböző osztályokba tartoznak. Ez egyrészt akkor fordulhat elő, ha néhány adat nem megfelelő, azt mondjuk, hogy zajosak (noise) az adatok. Másrészt akkor is előállhat ez a helyzet, ha az attribútumok nem adnak elég információt a szituáció teljes leírására, vagy a problématér valójában nemdeterminisztikus. Egyszerű megoldása lehet ennek a problémának a többségi szavazás használata.
18.4. ábra - A példahalmaz attribútumteszteléssel történő szétosztása. (a) A Konyha alapján történő szétosztás nem visz közelebb ahhoz, hogy a pozitív és negatív példákat megkülönböztessük. (b) A Vendégek attribútum tesztje jól szeparálja a pozitív és negatív példákat. Miután a Vendégek tesztjét elvégeztük, az Éhes egy eléggé jó második tesztlehetőséget ad.
A DÖNTÉSI-FA-TANULÁS algoritmust a 18.5. ábrán mutatjuk be. Az ATTRIBÚTUM-VÁLASZTÁS módszer bemutatása a következő alfejezetben található.
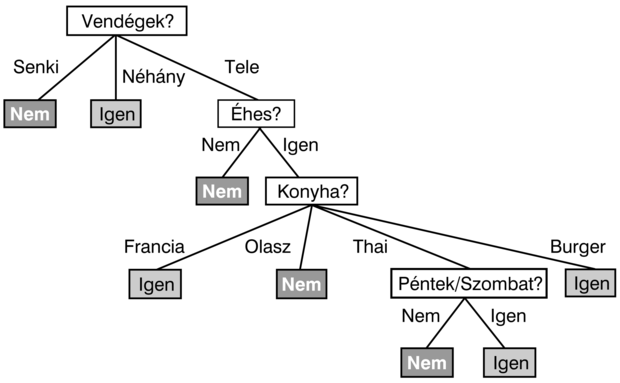
Az algoritmus által a 12 mintából álló adathalmaz alapján létrehozott fa a 18.6. ábrán látható. Az eredményként kapott fa nyilvánvalóan különbözik a 18.2. ábrán látható eredetitől, annak ellenére, hogy az adatokat egy, az eredeti fát használó ágens generálta. Arra gondolhatnánk, hogy az algoritmus nem ért el különösebben jó eredményt a helyes függvény megtanulásában. Mindamellett ez téves következtetés lenne. A tanuló algoritmus a példákat látja, nem az eredeti függvényt. Valójában a létrehozott hipotézis (lásd 18.6. ábra) nem csupán megfelel az összes példának, de lényegesen egyszerűbb is, mint az eredeti fa. A tanuló algoritmusnak semmi oka sincs az Eső és Foglalás attribútumokra vonatkozó teszteket felvenni, mivel ezek nélkül is tudja osztályozni az összes példát. Mellesleg, felfedett egy érdekes és váratlan viselkedést: az első szerző hétvégeken várni fog thai ételekre.

Természetesen ha több mintát gyűjtöttünk volna, akkor egy, az eredetihez hasonlóbb fát hozhattunk volna létre az induktív tanulással. A 18.6. ábrán látható fa elkerülhetetlenül hibákat is el fog követni; például sohasem látott olyan helyzetet, amelyben a várakozási idő 0–10 perc, de az étterem tele van. Egy olyan esetben, amikor az Éhes attribútum hamis értékű, a fa azt választja, hogy ne várjunk, pedig én (S. Russell) bizonyára várnék. Felmerül tehát az a kézenfekvő kérdés, hogy ha az algoritmus egy konzisztens, de inkorrekt fát indukál, akkor mennyire lesz inkorrekt ez a fa? Ezt azután fogjuk kísérletileg elemezni, hogy először elmagyaráztuk az attribútumteszt-választási lépés részleteit.
A döntési fa tanulás során az attribútumok kiválasztására szolgáló eljárás arra irányul, hogy minimalizáljuk az eredményül kapott fa mélységét. Az alapötlet az, hogy azt az attribútumot válasszuk, amellyel a lehető legmesszebbre jutunk a példák pontos osztályozásában. Egy tökéletes attribútum a példákat egy csupa pozitív és egy csupa negatív példát tartalmazó halmazra osztja. A Vendégek nem tökéletes attribútum, de meglehetősen jó. Egy valójában haszontalan attribútum, mint például a Konyha, tesztjének eredményeként a kapott halmazokban nagyjából ugyanolyan arányban lesz pozitív és negatív példa, mint az eredeti halmazban.
Mindössze arra van szükségünk, hogy formális mértéket találjunk arra, hogy mit jelent a „meglehetősen jó” és a „valójában haszontalan”, ezek után implementálni tudjuk a 18.5. ábrán látható ATTRIBÚTUM-VÁLASZTÁS függvényt. A mérték akkor érje el maximumát, amikor az attribútum tökéletes, és akkor legyen minimális, amikor az attribútumnak egyáltalán nincs semmi haszna. Egy megfelelő mérték az attribútum által szolgáltatott információ (information) várható értéke, ahol az információt abban a matematikai értelmezésben használjuk, ahogy először Shannon és Weaver definiálta (Shannon és Weaver, 1949). Az információ definíciójának megértéséhez gondoljunk például annak a kérdésnek a megválaszolására, hogy egy feldobott pénzérme fej oldala lesz-e felül. Az, hogy a válaszban mennyi információ rejlik, az az előzetes a priori tudástól függ. Minél kevesebbet tudunk, annál több a szolgáltatott információ. Az információelmélet bitekben méri az információtartalmat. Egy bit információ ahhoz elég, hogy egy olyan kérdésre, amelyről semmilyen előzetes elképzelésünk sem volt (például egy szabályos érme feldobásának eredménye) igen/nem választ megadjunk. Általánosságban, ha a lehetséges vi válaszok valószínűsége P(vi), akkor a válasz I információtartalmát a következő összefüggés adja meg:

A pénzfeldobás esetre ellenőrizve az összefüggést, a következőt kapjuk:
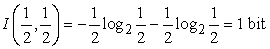
Ha az érme hamisított oly módon, hogy a dobás 99%-ban fejre jön ki, akkor I(1/100, 99/100) = 0,08 bitre van szükség, és ha a fej kimenetel valószínűsége 1-hez tart, akkor az aktuális kimenetel megjóslásához szükséges információ 0-hoz tart.
Döntési fa tanulás esetén a megválaszolásra váró kérdés az, hogy egy adott példának mi a helyes besorolása. Egy jó döntési fa választ ad erre a kérdésre. Még mielőtt egyetlen attribútumot teszteltünk volna, a válaszok valószínűségét becsülhetjük a tanító halmazban található pozitív és negatív minták arányával. Tegyük fel, hogy a tanító halmazban p pozitív és n negatív példa található. Ez esetben a helyes válasz információtartalmának becslése:
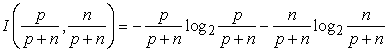
A 18.3. ábrán bemutatott étterem tanító halmaz p = n = 6 mintát tartalmaz, tehát 1 bit információra van szükségünk.
Egyetlen A attribútum tesztje nem fogja megadni mindezt az információt, de valamennyit megad belőle. Pontosan mérni tudjuk, hogy mennyit, ha megnézzük, hogy mennyi információra van még szükségünk az attribútumteszt után. Bármely A attribútum, amely v különböző értéket vehet fel, E1, ..., Ev részhalmazokra bontja az E tanító halmazt, az A lehetséges értékei szerint. Mindegyik Ei részhalmaz pi pozitív és ni negatív példát tartalmaz, így ezen az ágon továbbhaladva I(pi/(pi + ni), ni/(pi + ni)) bit információra van szükségünk a válasz megadásához. A tanító halmazból véletlen mintavétellel nyert minta esetén annak valószínűsége, hogy az A attribútum ezen a mintán az i-edik értéket veszi fel: (pi + ni)/(p + n). Ennek megfelelően az A attribútum tesztje után az átlagos információszükséglet, amely a példa osztályozásához kell:
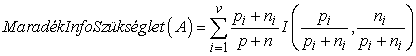
Az attribútum tesztjéből származó információnyereség (information gain) az eredeti (A tesztje előtti) információszükséglet és a teszt utáni új információszükséglet különbségeként kapható meg:
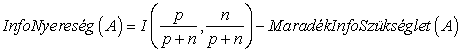
Az ATTRIBÚTUM-VÁLASZTÁS függvényben használt heurisztika csupán azt takarja, hogy válasszuk a legnagyobb nyereséget biztosító attribútumot. Visszatérve a 18.4. ábrán vizsgált attribútumokhoz:
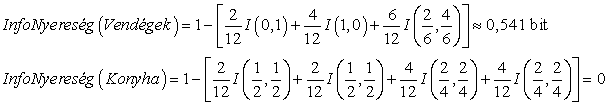
Ez megerősíti azt az intuíciónkat, hogy a Vendégek jobb attribútum a tanítóhalmaz részhalmazokra szabdalására, mint a Konyha. Az a helyzet, hogy a Vendégek attribútumnak van a legnagyobb információnyeresége, ezért a döntési fa tanuló algoritmus ennek tesztjét választaná a fa gyökércsomópontjába.
Egy tanuló algoritmus akkor jó, ha olyan hipotéziseket hoz létre, amelyek jól jósolják meg az általuk előzetesen nem látott példák osztályba sorolását. A 18.5. fejezetben azt mutatjuk be, hogy mi módon lehet előre megbecsülni a jóslás minőséget. Ebben a fejezetben egy olyan módszertant vizsgálunk meg, amellyel az osztályba soroló képességet méréssel lehet becsülni.
Nyilvánvalóan akkor jó egy jóslás, ha igaznak bizonyul, így a hipotézis minőségét megbecsülhetjük az ismertté vált tényleges osztálybasorolások alapján. Ezt egy teszthalmaznak (test set) nevezett mintahalmaz segítségével végezhetjük el. Ha az összes rendelkezésünkre álló példát tanításra használjuk, akkor továbbiakat kell gyűjtenünk a teszteléshez. Ezért gyakran kényelmesebb a következő módszert alkalmazni:
-
Gyűjtsünk egy nagy példahalmazt.
-
Osszuk két diszjunkt részre: a tanító halmazra (training set) és a teszthalmazra (test set).
-
Alkalmazzuk a tanító algoritmust a tanító halmazon, és így generáljunk egy h hipotézist.
-
Mérjük meg a teszthalmazon, hogy a h hipotézis a halmaz hány százalékára ad helyes osztálybasorolást.
-
Ismételjük meg az 1–4 lépéseket különböző tanító halmaz méretekre, és mindegyik mérethez különböző véletlenszerűen kiválasztott tanító halmazokra.
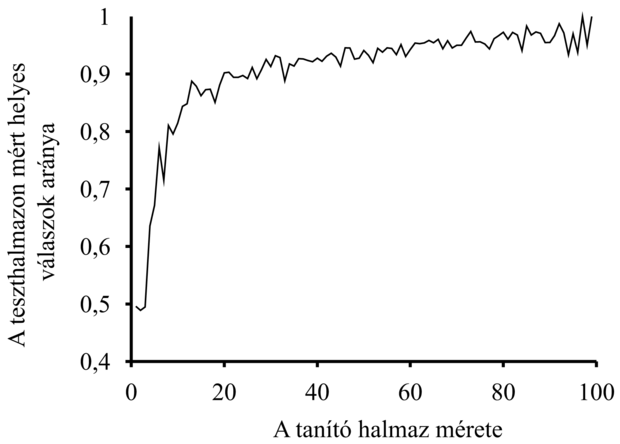
Ennek az eljárásnak az eredményeként egy adathalmazt kapunk, amelynek feldolgozásával megkaphatjuk az átlagos jóslási képességet a tanító halmaz méretének függvényében. Ezt a függvényt ábrázolva kapjuk az adott algoritmusnak egy adott tématerületre vonatkozó tanulási görbéjét (learning curve). A DÖNTÉSI-FA-TANULÁS algoritmus étterem példáinkkal felvett tanulási görbéje a 18.7. ábrán látható. Vegyük észre, hogy a tanító halmaz méretével javul a predikció minősége! (Ez okból az ilyen görbéket ún. boldog görbéknek (happy graphs) is nevezik.) Ez annak a jele ugyanis, hogy valóban van valami mintázat az adatokban, és az algoritmus felfedezi ezt a mintázatot.
18.7. ábra - Tanulási görbe az étterem problématérre véletlenszerűen generált 100 példa esetén. A görbe 20 kísérlet eredményét összegzi.
A tanuló algoritmusnak nyilvánvalóan nem szabad az előtt „látnia” a tesztadatokat, mielőtt a megtanított hipotézist teszteltük velük. Szerencsétlen módon nagyon könnyű beleesni abba a hibába, hogy tanítás közben a tesztadatokra kukucskálunk (peeking). Ez tipikusan a következő módon zajlik: egy tanuló algoritmus általában számos hangolási lehetőséggel rendelkezik, amellyel az algoritmus viselkedését változtatni tudjuk. Például számos különböző kritérium lehet, amelyek alapján a következő attribútumot kiválasztjuk a döntési fa tanulásnál. Különböző beállítások mentén számos különböző hipotézist generálunk, majd mindegyiket leteszteljük a teszthalmazon, és a legjobb hipotézis predikciós eredményét tekintjük eredménynek. Fájdalmas bár, de kukucskálás történt! Ennek oka, hogy a hipotézist a teszthalmazon elért eredménye alapján választottuk ki, így a teszthalmaz által hordozott információ beszivárgott a tanuló algoritmusba. Ennek a mesének az a tanulsága, hogy bármely eljárásnak, amelynek része a hipotéziseknek a teszthalmazon nyújtott teljesítményük alapján való összehasonlítása, egy új teszthalmazt kell használnia, amelyen a végül kiválasztott hipotézis teljesítményét méri. A gyakorlatban ez túl körülményes, így az emberek továbbra is ily módon szenynyezett adathalmazaikon folytatják kísérleteiket.
Korábban már láttuk, hogy ha van kettő vagy több olyan példa, amelyeknek azonos a leírásuk (az attribútumokra nézve), de eltérő az osztálybasorolásuk, akkor a DÖNTÉSI-FA-TANULÁS algoritmus nem lehet képes olyan döntési fát találni, amely minden példával konzisztens. Az általunk korábbiakban említett megoldás a következő. Ha determinisztikus osztályzásra van igény, akkor minden levélcsomópont adja vissza a hozzá tartozó halmaz többségi osztályát. Más esetekben pedig adja vissza a relatív gyakoriságok alapján becsült osztályba tartozási valószínűségeket. Sajnos, ez még távol van a történet végétől. Könnyen elképzelhető, sőt valójában elég valószínű, hogy a tanuló algoritmus akkor is talál egy olyan döntési fát, amely az összes példával konzisztens, ha nagyon fontos információ hiányzik. Ennek oka, hogy az algoritmus felhasználhat irreleváns attribútumokat, ha vannak ilyenek, hogy hamis megkülönböztetést tegyen a példák közt.
Vizsgáljuk meg azt a problémát, amikor egy kockadobás eredményét akarjuk megjósolni. Tegyük fel, hogy több napon át kísérleteket végzünk számos kockával. Mindegyik tanító példát a következő attribútumokkal írunk le:
-
Nap: az a nap, amelyen a kockadobást végeztük (hétfő, kedd, szerda, csütörtök).
-
Hónap: a hónap, amelyben a kockadobást végeztük (január vagy február).
-
Szín: a kocka színe (vörös vagy kék).
Mindaddig, amíg két dobásnak nem lesz pontosan azonos a leírása, a DÖNTÉSI-FA-TANULÁS képes lesz egzakt hipotézist találni. Minél több attribútum van, annál valószínűbb, hogy egzakt hipotézist kapunk. Viszont az összes ilyen hipotézis teljesen hamis lesz! Amit szeretnénk, az az, hogy a DÖNTÉSI-FA-TANULÁS – miután elég példát látott már – egyetlen levélcsomópontot adjon vissza, minden egyes dobási eredményhez közelítőleg 1/6 valószínűséggel.
Amikor a hipotézisek nagy halmaza lehetséges, akkor óvatosnak kell lennünk, nehogy arra használjuk az ebből eredő nagy szabadságot, hogy értelmetlen „szabályosságot” találjunk az adatokban. Ezt a problémát túlilleszkedésnek (overfitting) nevezzük. Ez rendkívül általános jelenség, akkor is jelentkezhet, amikor a keresett függvénynek egyáltalán nincs valószínűségi jellege. Mindamellett ez a probléma az összes tanulási algoritmust sújtja, nem csak a döntési fákat.
A túlilleszkedés kezelésének kimerítő matematikai tárgyalása meghaladja e könyv kereteit. A probléma megoldására itt csupán egy egyszerű – döntési fa metszés (decision tree pruning) nevű – módszert mutatunk be. A metszés (vagy nyesés) azon az alapon működik, hogy megakadályozzuk a nem nyilvánvalóan releváns attribútumok tesztje mentén a mintahalmaz ismételt (rekurzív) felosztását, még akkor is, ha az adatok osztálybasorolása az adott csomópontban nem egyforma. Az a kérdés, hogyan vesszük észre egy attribútumról, hogy irreleváns?
Tegyük fel, hogy egy irreleváns attribútumra alapozva osztottuk ketté a mintahalmazunkat. Általánosságban szólva azt várjuk, hogy ez esetben az eredményül kapott részhalmazokban nagyjából ugyanabban az arányban fognak szerepelni az egyes osztályokba tartozó minták, mint az eredeti halmazban. Ekkor az információnyereség közel nulla.[184] Tehát az információnyereség (annak hiánya) jó jelzés lehet az irrelevanciára. Most az a kérdés merül fel, hogy mekkorának kell lennie az információnyereségnek ahhoz, hogy ezen attribútum mentén szétosszuk a mintahalmazt?
Ezt a kérdést a statisztikai szignifikanciatesztet (significance test) használva válaszolhatjuk meg. Ez a teszt azzal a feltételezéssel indul, hogy a példákban egyáltalán nincs közös mintázat (ez az úgynevezett nullhipotézis). Ezek után az aktuális adathalmazt vizsgáljuk: meg akarjuk határozni annak mértékét, hogy az adathalmaz mennyire tér el a tökéletesen mintázat nélküli helyzettől. Ha az eltérés mértéke statisztikailag már valószínűtlen (rendszerint 5% vagy ennél kisebb valószínűséget értünk ezalatt), akkor ezt annak bizonyítékaként vesszük, hogy az adatokban jelen van egy alapvető mintázat. A valószínűséget a véletlen mintavételezés esetén várható eltérések standard eloszlását feltételezve számítjuk ki.
Ebben az esetben a nullhipotézis az, hogy az attribútum irreleváns, ennek megfelelően egy végtelen nagy mintahalmazra vett információnyereség nulla lenne. Azt kell kiszámítanunk, hogy a nullhipotézist feltéve egy ν méretű mintahalmazban a várt pozitív és negatív eseteloszlástól a megfigyelt eloszlás eltérése milyen valószínűséggel léphet fel. Az eltérés mértékét megadhatjuk a részhalmazok tényleges pozitív és negatív esetszámának (pi, ni) a nullhipotézis fennállása esetén várt esetszámokkal 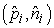 való összehasonlításával:
való összehasonlításával:

A teljes eltérés kényelmesen számítható mértékét a következő összefüggés adja:
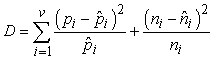
A nullhipotézist feltételezve a D eltérés mérték ν– 1 szabadságfokú χ2 (khí-négyzet) eloszlást követ. Annak valószínűségét, hogy az attribútum valóban irreleváns, standard χ2 táblázatok vagy statisztikai szoftver segítségével számíthatjuk ki. A 18.11. feladatban tűztük ki célul, hogy a DÖNTÉSI-FA-TANULÁS algoritmusban elvégezzük azokat a változtatásokat, amelyek a metszés ezen – χ2 metszés (χ2 pruning) néven ismert – formájához vezetnek.
A zaj metszés segítségével kezelhető: az osztályozási hibák lineáris növekedést okoznak a predikciós hibában, míg az esetleírásban fellépő hibák aszimptotikus hatást gyakorolnak, amely egyre rosszabb, ahogy a döntési fa egyre kisebb halmazok kezelésére zsugorodik. Ha az adatok nagy zajjal terheltek, akkor a metszéssel készült döntési fák lényegesen jobb eredményt adnak, mint a metszés nélkül készültek. Ráadásul a metszéssel készült fák gyakran jóval kisebbek, ezért könnyebben érthetők.
Egy másik túlilleszkedést csökkentő technika a keresztvalidáció (cross-validation). Bármely tanulási eljárásnál alkalmazható, nem csupán a döntési fa tanulásnál. Az alapvető ötlet annak megbecsülése, hogy az egyes hipotézisek mennyire jól fogják megjósolni a még nem látott esetekre adandó válaszokat. Ezt úgy becsülhetjük, hogy az ismert adatok egy részét félretesszük, és ezekkel teszteljük a megmaradt adatok alapján tanulással létrehozott fa predikciós képességét. K-szoros keresztvalidációnak nevezzük, ha k kísérletet végzünk, és minden esetben az adatok más és más 1/k-ad részét tesszük félre validációs tesztcélra, majd a végén átlagoljuk az eredményeket. Az 5 és a 10 elterjedten használt k értékek. Szélső esetként használják a k = n választást, amelyet hagyj-ki-egyet keresztvalidációs módszerként ismerünk. A keresztvalidációt tetszőleges döntési fa tanulási módszerrel együtt alkalmazhatjuk (beleértve a metszést is), célja mindig az, hogy olyan döntési fa kiválasztását segítsük elő, amely jó predikciós képességgel rendelkezik. A kukucskálási jelenség elkerülése végett ezek után ezt a predikciós képességet egy új teszthalmazon kell mérnünk.
Egy sor problémát meg kell oldanunk ahhoz, hogy a döntési fa indukciót a problémák szélesebb körére kiterjeszthessük. Nagyjából felvázoljuk mindegyiket, azt javasolva, hogy a teljesebb megértés érdekében a kapcsolódó feladatokat oldja meg az olvasó.
-
Hiányzó adatok (missing data): Számos területen nem ismerhető meg minden példa összes attribútuma. Lehet, hogy az értékek nem kerültek tárolásra, vagy túl drága lenne a mérésük. Ez két problémát vet fel: először, ha van is egy teljes döntési fánk, akkor hogyan tudunk egy olyan mintát osztályozni, amelynek egy tesztelendő attribútuma hiányzik? Másodszor, hogyan módosítsuk az információnyereségre vonatkozó formulát, ha néhány példa ezen attribútumának értéke nem ismert? Ezeket a kérdéseket a 18.2. feladatban vizsgáljuk.
-
Sokértékű attribútumok (multivalued attributes): Ha egy attribútum nagyszámú értéket vehet fel, akkor az információnyereség nagysága nem megfelelő mértéke az attribútum hasznosságának. Szélsőséges esetben egy olyan attribútumot használnánk, mint például az ÉtteremNév attribútum, amely minden példára más és más értéket ad. Ez esetben példák minden részhalmaza egyelemű lesz, egyedi osztálybasorolással, így az információnyereség erre az attribútumra veszi fel maximális értékét. Mindamellett ez az attribútum irreleváns, értéktelen. Egy lehetséges megoldás a nyereségarány (gain ratio) használata (lásd 18.13. feladat).
-
Folytonos és egész értékű bemeneti attribútumok (continuous and integer-valued input attributes): A folytonos vagy az egész értékű bemeneti attribútumok – mint például a Magasság és a Súly – által felvehető értékek halmaza végtelen. A döntési fa tanuló algoritmusok az ilyen esetekre nem generálnak végtelen elágazású csomópontokat, inkább megkeresik azt a küszöbpontot (split point), amely a legnagyobb információnyereséget eredményezi. Például egy adott csomópontnál az lehet a helyzet, hogy a Súly > 160 teszt adja a legnagyobb információnyereséget. Léteznek hatékony dinamikus programozási módszerek jó küszöbpontok megtalálására, de még mindig messze ez a legtöbb erőforrást igénylő része a döntési fa tanulási eljárások valós problémákra való alkalmazásának.
-
Folytonos értékkészletű kimeneti attribútumok (continuous-valued output attributes): Ha egy numerikus értéket akarunk megjósolni, például egy műtárgy árát, akkor nem osztályozásra van szükségünk, hanem egy regressziós fára (regression tree). Egy ilyen fa nem egyetlen értéket (osztályt) ad vissza az egyes levél csomópontjaiban, hanem egy attribútumhalmaz lineáris függvényét. Például a műtárgyak regreszsziós fájának kézzel festett metszetekre vonatkozó ága a területnek, a kornak és a színek számának lineáris függvényéhez vezethet. A tanuló algoritmusnak kell azt megoldania, hogy mikor álljon le a minták csomópontokban történő szétosztásával, áttérve a maradék attribútumokat (vagy azok bizonyos részhalmazát) felhasználó lineáris regresszió megalkotására.
Egy döntési fa tanulásra szolgáló, valós problémák megoldását célzó rendszernek képesnek kell lennie mindezen problémák kezelésére. A folytonos értékű változók kezelése különösen fontos, mivel mind a fizikai, mind a gazdasági folyamatok numerikus értékekkel jellemezhetők. Számos, üzleti forgalomban kapható programcsomag készült, amelyek megfelelnek mindezen a kritériumoknak, és segítségükkel több száz – valamilyen konkrét területen – alkalmazott rendszert fejlesztettek ki. Az ipar és kereskedelem sok területén, ha minták alapján kialakított osztályozásra van szükség, akkor elsősorban döntési fákkal próbálkoznak. A döntési fák egyik fontos tulajdonsága, hogy az ember számára jól érthető a tanuló algoritmus által előállított eredmény. (Valójában olyan gazdasági döntések esetén, amelyeknek megkülönböztetés elleni jogszabályoknak kell megfelelniük, ez jogi követelmény.) A neurális hálózatoknál hiányzik ez a fontos tulajdonság (lásd 20. fejezet).
