10.2. Kohonen háló, kompetitív hálózatok
A Kohonen háló − hasonlóan számos, eddig bemutatott hálóhoz − biológiai eredetű [Koh82]. A jelenlegi ismeretek alapján egyértelműen megállapítható, hogy az agy komplex adatstruktúrák belső modellezésénél térbeli leképzést használ [Koh89]. Kohonen ezt az ötletet használta fel, amikor a róla elnevezett hálózatot kialakította. A térbeli leképezés biztosítja azt is, hogy a hálózat adatokat tároljon olyan módon, hogy a tanító adatok térbeli és topológiai kapcsolatait megtartsuk és valamilyen jelentéssel bíró módon reprezentáljuk.
A Kohonen háló alapeleme egy lineáris összegző funkciót megvalósító processzáló elem; a processzáló elemek egyetlen rétegben, általában egy sík rácspontjaiban vannak elhelyezve. Minden bemenet a hálózat összes csomópontjához (processzáló eleméhez) kapcsolódik. A hálózatban nemcsak előrecsatolást megvalósító súlyok, hanem visszacsatolás is található, ez azonban a közvetlen szomszédos csomópontokkal való oldalsó összekötésekre korlátozódik. A háló további jellemzője, hogy nincs különálló kimeneti réteg − a rács minden egyes csomópontja egyben kimeneti csomópont is. A 10.2 ábrán bemutatott elrendezés valójában egy N-bemenetű − M-kimenetű Kohonen hálót mutat. A háló egyes kimenetei a bemeneti komponensek súlyozott összegei, vagyis a háló a bemenetek és a kimenetek között lineáris kapcsolatot valósít meg:
(10.7)
Az oldalirányú kapcsolatok rögzítettek; jellegük gerjesztő, ha egy processzáló elem önmagára való visszacsatolásáról van szó és gátló a többi esetben. Kialakításukról és szerepükről a későbbiekben szólunk.
A Kohonen hálózatoknál az adaptív, önszerveződő tanulás két legfontosabb kérdése a súly-adaptációs eljárás és a csomópontok topológiai környezetének fogalma. Mindkét fogalom jelentős mértékben eltér az eddig tárgyalt neurális hálózatoktól, ezért a Kohonen hálózat működésének bemutatását erre a két kulcsfogalomra építjük.
A Kohonen háló súlymódosítása a versengés felhasználásával a Hebb szabályon alapul. Ez azt jelenti, hogy a súlymódosítás a Hebb szabály, illetve a Hebb szabály normalizált változata szerint történik; de nem módosítjuk a hálózat összes súlyát, hanem csak a győztes processzáló elemét.
Egy adott bemenet mellett győztes az a processzáló elem, amelyik a legnagyobb kimenetet produkálja. Ha tehát
, (10.8)
akkor a győztes processzáló elem indexe i*. A tanítás során csak -ot módosítjuk:
(10.9)
Látható, hogy a súlymódosítás a Hebb szabály szerint történik, ami − ha figyelembe vesszük, hogy a győztes elem kimenete 1 lesz − az alábbi formában is felírható:
(10.10)
Ez azt mutatja, hogy a módosítás során a súlyvektort azon bemeneti vektorok irányába forgatjuk, amelyek mellett az adott elem a győztes. Egy adott neuron súlyvektora ennek megfelelően − konvergencia esetén − olyan értékre áll be, amely azon bemenő vektorok átlagaként áll elő, melyek hatására az adott neuron győztessé válik. A győztes elem vagy az egyes lineáris kimenetek összehasonlításával választható ki, vagy automatikusan az oldalirányú kapcsolatok eredményeképpen alakul ki. Az oldalirányú (gerjesztő és gátló) kapcsolatok ugyanis azt eredményezik, hogy annak a neuronnak a kimenete, amelyiknek kezdetben legnagyobb volt az értéke egyre nő, míg a többié csökken, addig, amíg a győztes kimenete 1, a többié 0 nem lesz. (Megjegyezzük, hogy a bináris kimenetet a legegyszerűbben úgy biztosíthatjuk, ha a lineáris összegzőt itt is egy nemlinearitás − a 0 és 1 közötti telítéses lineáris függvény − követi.)
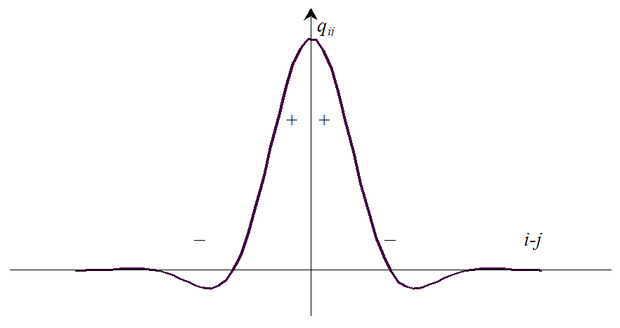
Az oldalirányú kapcsolatok súlyait a processzáló elemek egymástól való, valamilyen értelemben vett távolsága függvényében mutatja a 10.3 ábra, amelyet mexikói kalap függvénynek nevezünk. Az ábrán a (+) jel a gerjesztő kapcsolatot, a (−) jel a gátló kapcsolatot jelöli. Az oldalirányú kapcsolatok ilyen kialakítása azt is biztosítja, hogy a háló ún. topológikus leképezést valósít meg, ami azt jelenti, hogy a tanítás során a bemenetre kerülő minták közötti topológiai kapcsolatokat a háló megtartja. A topológikus leképezésről és a most bemutatott hálóarchitektúráról bővebben a következőkben szólunk.
Megjegyezzük, hogy az oldalirányú kapcsolatok ilyen kialakítása biológiai eredetű. Mind anatómiai, mind fiziológiai bizonyíték van arra, hogy az emlősök agyában megtalálhatók a szomszédos neuronok között a gerjesztő és gátló kapcsolatokat megvalósító oldalirányú összeköttetések [Koh89]
A súlyok (10.9) ill. (10.10) szerinti módosítása önmagában azonban nem alkalmazható, hiszen azt eredményezi, hogy a súlyok minden határon túl nőhetnek. A korrekt versengéshez pedig az kell, hogy a súlyoknak ne az abszolút értéke, hanem az iránya határozza meg a győztest. A megoldást a súlyok normalizálása jelenti. A normalizálásra több lehetőség is van. Leggyakrabban az ún. standard versengő tanulást szokták alkalmazni, ami a következő:
. (10.11)
Ez az eljárás biztosítja a súlyvektorok folyamatos normalizálását feltéve, hogy a bemeneti vektorok is normalizáltak.
A Kohonen háló megfelelő működéséhez is szükség van a súlyok kezdeti beállítására és a tanulási tényező megválasztására.
A súlyvektorok kezdeti értékének beállításánál némi óvatosságra van szükség. Az általános javaslat most is az, hogy indulásnál a hálózat súlyait véletlenszerű, normalizált értékekre állítsuk be. Azonban, ha a súlyvektorok valóban véletlen értékeket vesznek fel, lehetséges, hogy a tanítás nem lesz konvergens vagy a háló nagyon lassan fog tanulni. Ennek oka jórészt intuitív módon mutatható meg. Tipikus esetekben a bemeneti tanító vektorok a mintatér korlátozott tartományában valamilyen klasztert fognak képezni. Ha a hálózat súlyvektorai véletlenszerűen szóródnak, akkor könnyen előállhat az az eset, amikor sok súlyvektor iránya különbözik jelentősen a tanító minták többségének irányától. Az ilyen súlyvektorokkal rendelkező processzáló elemek sohasem fognak győzni (ún. halott processzáló elemek), és így nem is vesznek részt a tanulási folyamatban. Amennyiben túl sok halott neuronunk van, a háló tényleges mérete és képessége nem lesz elegendő a kitűzött feladat megoldására, pl. megfelelő számú klaszter kialakítására. Mindenképpen olyan megoldásra van szükség, amely minél több processzáló elemet bevon a tanulásba. Ennek érdekében a következő lehetőségekkel élhetünk:
• a súlyvektorok kezdeti értékeit magukból a tanítópontokból választjuk,
• nemcsak a győztes, hanem a többi neuron súlyvektorait is módosítjuk, de kisebb μ-vel; így a vesztes neuronok súlyvektorai is módosulnak és ezért esélyük lesz arra, hogy győztessé váljanak (ezt a tanulási változatot szivárgó tanulásnak(leaky learning) nevezik),
• geometriai alakzatban elrendezett neuronok esetében a győztes adott környezetében lévőket is módosítjuk a győztessel megegyező vagy ahhoz hasonló módon (ez a változat az ún. Kohonen térképet eredményezi, amit önszervező térképnek is szokás nevezni, ld. később),
• a bemeneti vektorokat egy közös kezdeti beállítási irányból (v) kiindulva fokozatosan adjuk a hálózatra; a győztes neuron súlymódosítása , ahol α kezdetben 0, majd lassan növekszik 1-re,
• a hálózat lineáris kimenetéből egy változó küszöbértéket vonunk ki; a gyakran győztesnél a küszöböt növeljük, így nehezebben lesznek ismét győztesek, a ritkán győzőknél pedig a küszöb csökkentésével a győzelmi esélyt növeljük,
• a bemeneti vektorokhoz zajt adunk, amelynek elég nagy a szórása ahhoz, hogy "mindenfajta" x érték előforduljon, így minden neuront be tudunk vonni a módosításokba.
A Kohonen hálót Kohonen térképnek, vagy önszervező térképnek (Kohonen map, self-organizing map, SOM) hívjuk, ha a bemeneti minták topológiai kapcsolatait is megőrzi: hasonló bemeneti mintákra egymáshoz geometriailag közelálló neuronok válaszolnak győztesként. (Ehhez az kell, hogy a Kohonen háló processzáló elemei között is értelmezni lehessen szomszédsági viszonyokat. A Kohonen térkép esetén a neuronok általában vagy egy vonal mentén vagy egy síkban vannak elrendezve, ahol a szomszédság definiálható.) Kohonen a topológikus kapcsolatok modellezésére javasolta az ún. környezetek definiálását és ehhez kapcsolódóan egy módosított tanulási szabály alkalmazását. Környezetnek nevezzük a győztes processzáló elem valamekkora − általában dinamikusan változó méretű − szomszédságában lévő processzáló elemek összességét. A módosított tanulási szabály a következő:
• nemcsak a győztes neuron súlyait módosítjuk a tanulás során, hanem a győztes adott méretű környezetében lévőket is,
• a tanulás során a környezetet csökkentjük, mintegy rázsugorítjuk a győztes neuronra, a környezet összes neuronjának súlyait a győztessel azonos tanulási szabály alapján módosítjuk:
(10.12)
Itt és az i-edik, illetve a győztes processzáló elem geometriai helyét adja meg, pedig az ún. szomszédsági függvény. A szomszédsági függvény megfelelő megválasztása alapvető fontosságú a topológiai tulajdonságok megtartása szempontjából. A rendszerint szimmetrikus függvény i=i*-nál 1 értéket, az i*-hoz közeli i értékekre 1-höz közeli értéket vesz fel, és a győztes neurontól való euklideszi távolság függvényében monoton csökken. Egy lehetséges választás:
, (10.13)
ahol a szomszédság szélességét befolyásoló, a tanulás előrehaladtával csökkenő értékű paraméter.
A súlyok alakulása a Kohonen térkép lépésenkénti felrajzolásával követhető. A Kohonen térkép egy olyan összekötött pontelrendezés a súlyvektor térben, ahol az egymással szomszédos neuronok súlyvektorainak végpontjai vannak összekötve. A Kohonen térkép alakulását mutatja be a tanulás folyamán a Kohonen mozi, melynek néhány képkockáját mutatja a 10.4 ábra.
Az ábrán olyan esetet mutatunk be, ahol a bemeneti mintapontok egy kétdimenziós egyenletes eloszlású valószínűségi változó egyes realizációi, a háló processzáló elemeit pedig egy egyenletes négyzetrács rácspontjaiban helyezzük el. Ebben az esetben, ha a Kohonen háló topológiai leképezést valósít meg, akkor egy adott geometriai pozícióban lévő neuron a bemeneti adatok azon részhalmazába tartozó minták hatására aktivizálódik, melyek geometriai elhelyezkedése a bemeneti mintatérben a processzáló elem geometriai elhelyezkedéséhez közeli. Látható, hogy a kiinduló helyzetben (a) az egyes processzáló elemek súlyvektorai véletlen elhelyezkedésűek, és ahogy a tanítással előrehaladunk − 200 iteráció után a (b), 4000 után a (c) ábrák −, a súlyvektorok kezdenek beállni a bemeneti minták eloszlásának megfelelően. A háló tanításának előrehaladásával − a 10.4 (d) ábra 78000 iterációs lépés utáni állapotot mutat − a súlyvektorok egyre inkább egy egyenletes rács pontjaira mutatnak, vagyis a súlyvektorok irányai megfelelnek a megfelelő neuronok topológiai elrendezésének; a Kohonen térkép tükrözi a hálózat bemeneti adatainak eloszlását. Az ábrákon a szürke „+” jelek a tanítópontokat jelzik.

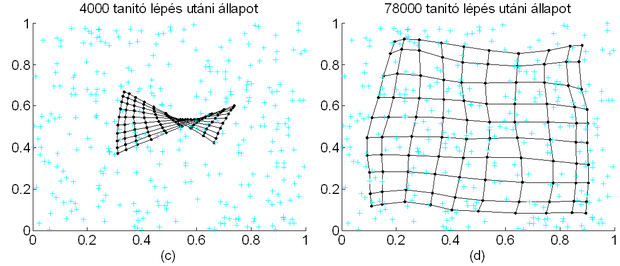
A topológiai térkép kialakulása általában két tanulási szakaszban valósul meg. Az első szakaszban egy durva leképezés jön létre, ekkor a térkép pontjai nagymértékben változnak, a tanulás viszonylag nagy tanulási együtthatóval történik (tipikusan μ > 0,5). A második szakaszban következik a súlyok finom–hangolása. Ekkor a súlyokon kisebb változásokat kell eszközölni, ezért a tanulási együttható kisebb, és az eljárás során fokozatosan még tovább is kell csökkentenünk. A finomhangolási szakasz tipikusan mintegy 100-1000-szer annyi lépést igényel, mint a durva leképezés kialakulása. A tanulás során előfordulhat, hogy egyes neuronok súlyvektorai a pozíciójuknak megfelelő súlyvektorok tükörképének felelnek meg. Ilyen esetre mutat példát a 10.4 (c) ábra, ahol a súlyvektorokat reprezentáló háló megcsavarodva látszik. A megcsavart állapotból általában különösen lassan alakul ki a mintapontok eloszlását tükröző súlyvektor-eloszlás. A 10.4 (d) ábra mutatja is ezt, hiszen a sok tízezer tanítólépés még mindig nem eredményezte a súlyvektorok egyenletes eloszlását.
Az önszervező térkép (SOM) számos alkalmazása közül ki kell emelni a szövegbányászati alkalmazásokat, melyet az utóbbi években a SOM kiterjesztéseként kifejlesztett WEBSOM felhasználásával oldhatunk meg sikeresen [Koh00], [Lag02], [Lag04]. A WEBSOM módszer az önszervező térképet (SOM) használja szöveges dokumentumok kétdimenziós térképre való leképezésére. A térképen a hasonló dokumentumok azonos vagy egymáshoz közeli térkép-elem(ek)en jelennek meg és minden egyes térkép-elemhez egy mutató is tartozik, ami a dokumentum adatbázisra mutat. Ezáltal egy keresésnél, miközben azon dokumentumokat megtaláljuk, melyek legjobban illeszkednek a kereső kifejezésre, további releváns eredményeket is találunk, melyek a megtalált dokumentumokat jelképező térképelemmel azonos vagy ahhoz közeli térképelemre voltak leképezve, függetlenül attól, hogy a keresési kifejezésnek megfeleltek-e vagy sem. A WEBSOMot kimondottan nagy szöveggyűjteményekben való keresésre dolgozták ki.
Annak ellenére, hogy a Kohonen hálózat felügyelet nélküli tanulást használ, Kohonen kialakított egy ellenőrzött tanuláson alapuló változatot is, amit tanuló vektorkvantálásnak nevezett el (learning vector quantization, LVQ) [Koh86], [Koh90].
Vektorkvantálásnak azt az eljárást nevezzük, amikor adattömörítési céllal a bemeneti vektorok egy tartományát az egész tartományt jellemző egyetlen vektorral, az ún. prototípus vektorral ill. a vektor sorszámával reprezentálunk. Vektorkvantálásnál tehát a bemeneti teret diszjunkt tartományokra bontjuk. Egy adott tartományt reprezentáló prototípus vektor (vagy a vektor sorszáma) úgy tekinthető, mint az adott tartományba eső bemenő vektorok kódja, ahol a lehetséges kódok száma − a diszjunkt tartományok száma − általában jóval kisebb, mint a lehetséges bemenő vektorok száma. A diszjunkt tartományokat reprezentáló kódok együttesét a vektorkvantálásnál kódkönyvnek nevezzük. Ha a kódkönyv elemeit, illetve a tartományokat úgy alakítjuk ki, hogy a tartományba eső bemenő vektoroknak a tartomány prototípusától vett átlagos euklideszi távolsága minimális legyen, akkor a vektorkvantálót Voronoi kvantálónak, a tartományokat pedig Voronoi tartományoknak vagy Voronoi régióknak nevezzük. A Voronoi tartományokat reprezentáló vektorok a Voronoi vektorok.
A tanuló vektorkvantálás valójában a Voronoi tartományok kialakításánál egy kétlépcsős eljárás második lépése: a Kohonen önszervező térkép által kialakított felosztás finomítását ellenőrzött tanulással biztosítja. Az ellenőrzött tanulás során a Voronoi vektorok és így a Voronoi régiók kismértékű módosítása következik be, javítva, finomítva a bemeneti mintatérben a klaszterek kialakítását és a Kohonen osztályozó minőségét.
A hálózat tanítása a következőképpen történik: a bemeneti tér egy vektorát a hálózatra adjuk, majd a választól függően végezzük a súlymódosítást:
• ha a győztes neuron a kívánt neuronnal egyezik meg, akkor ennek súlyait a Kohonen szabály szerint kell módosítani:
, (10.14)
vagyis a Voronoi vektort az őt győztesként kiváltó bemenő vektor irányához közelítjük,
• ha győztes nem a megfelelő PE, akkor a győztes súlyvektorát a Kohonen szabály (-1)-szeresével módosítjuk:
, (10.15)
vagyis itt épp ellenkezőleg, az adott bemenő vektor irányától távolítjuk.
A fenti LVQ1-nek nevezett eljárást Kohonen 1986-ban javasolta [Koh86]. Az eljárásnak később módosított változatai is születtek (LVQ2, LVQ3), melyek tovább finomítják a klaszterek kialakítását. Az alábbiakban csak az LVQ2 szabály lépéseit foglaljuk össze, az LVQ3 eljárással kapcsolatban csak az irodalomra utalunk [Koh90].
Az LVQ2 tanulási szabálya:
• ha a győztes neuron a megfelelő PE, akkor az előző szerint módosítjuk a súlyait:
, (10.16)
• ha azonban a győztes nem a megfelelő PE, és lenne a megfelelő neuron indexe, továbbá, ha a bemenő vektor (x) az i* és az indexű tartományok határvonalához közel helyezkedik el az i* indexű oldalon, akkor a súlymódosítás:
, (10.17)
és
, (10.18)
egyébként az előzőek (LVQ1) szerint történik a súlymódosítás.
A tanuló vektorkvantálásnak számos alkalmazását ismerjük. Ezek közül az egyik első az ún. fonetikus írógép (phonetic typewriter), melyet Kohonen a finn beszéd felismerésére hozott létre [Koh88]. A fonetikus írógép egy olyan összetett rendszer, amely hagyományos digitális jelfeldolgozó eljárásokat (spektrumanalízis), neurális hálózatot (Kohonen térkép) és szakértői rendszert együttesen alkalmazva oldja meg a beszédfelismerési feladatot.
