A szupport vektor gépek alkalmazásának legjelentősebb akadálya a nagy memória- és számítási komplexitás. Mint láttuk, ennek oka, hogy az SVM tanítása során egy nagy számításigényű kvadratikus programozási feladatot kell megoldani. Az előzőekben röviden összefoglalt néhány hatékony eljárás vagy a kvadratikus programozás gyors megvalósításával, vagy az SVM optimalizálási feladatának módosításával ér célt. Ezek a megoldások azonban mind az eredeti feladat megoldását keresik.
A probléma egy másik lehetséges megközelítése, ha az optimalizálási feladatot módosítjuk, az SVM elméleti hátterének, valamit előnyeinek lehetőség szerinti megtartása mellett. Ekkor azonban már nem az eredeti SVM feladat megoldására törekszünk. A biztonsági sáv maximalizálása, a duális felírás és a kernel trükk alkalmazása jelentik a módszer azon magját, amelyet meghagyva a számítási feladat átfogalmazásával az eredeti módszerhez hasonló kernel gépeket kaphatunk. Az SVM változatokkal szembeni fő elvárás, hogy egyszerűsítsék a szükséges számításokat, mindemellett megtartsák az eredeti eljárás jó tulajdonságait, mind a jó általánosítóképességet, mind a kapott megoldás ritkaságát (sparseness).
Az egyik legelterjedtebb ilyen módosítás a négyzetes hibára optimalizált szupport vektor gép, az LS-SVM(Least Squares Support Vector Machine) [Suy00], [Suy02]. Ez a megoldás az SVM-től eltérően a klasszikus neuronhálóknál szokásos négyzetes hibafüggvénnyel dolgozik, továbbá a kielégítendő feltételeket egyenlőségek formájában fogalmazza meg. Ennek köszönhetően a megoldás egy lineáris egyenletrendszer eredményeként áll elő, amelynek megoldása lényegesen egyszerűbb, mint a kvadratikus programozási feladaté.
Az SVM változatok közül először a legelterjedtebb LS-SVM-et mutatjuk be, ami megfelel a statisztikából ismert ridge regressziónak, amelyet később szintén bemutatunk röviden. A legkisebb négyzetes hiba alkalmazásából adódóan az eredeti LS-SVM és a ridge regresszió elveszíti a ritkasági tulajdonságot. Megfelelő módosítássokkal, kiterjesztésekkel azonban itt is elérhető, hogy ritka megoldást kapjunk. A ritka megoldásra vezető egyik lehetséges kiterjesztés az LS2-SVM. Ennek tárgyalását a redukált rangú kernel ridge regresszió(reduced rank kernel ridge regression, RRKRR) bemutatása követi, ami más megközelítést alkalmazva, de ugyancsak ritka megoldást biztosít.
A Johan Suykens által kidolgozott LS-SVM [Suy02] a hagyományos szupport vektor gépek olyan módosítása, ami az idő- és erőforrás-igényes kvadratikus programozással szemben, egy lineáris egyenletrendszer megoldására vezet.
Mivel az LS-SVM a hagyományos SVM módosítása, a kiinduló ötletek, illetve összefüggések hasonlóak, ezért a továbbiakban elsősorban az alapváltozattól való eltérések bemutatására törekszünk. A fő különbség a két módszer között az ε-érzéketlenségi sávval rendelkező költségfüggvény négyzetes függvényre való lecserélése, valamint, hogy az SVM mellékfeltételeit megfogalmazó egyenlőtlenségeket egyenlőségekre cseréljük.
Az LS-SVM tárgyalásánál csak a legáltalánosabb nemlineáris változatot származtatjuk.
Az osztályozásifeladat a már megszokott: adott egy
tanítópont-halmaz, ahol
egy N-dimenziós bemeneti vektor, illetve
az ehhez tartozó kívánt kimenet. A cél egy olyan modell létrehozása, ami jól reprezentálja a tanítópontok által leírt kapcsolatot.
Az osztályozó esetében az optimalizálási feladat az alábbi:
(6.79)
a
,
(6.80)
mellékfeltételekkel. A fenti képletben a négyzetes hibát megadó ei értékek a négyzetes költségfüggvényből adódó hibaértékek. Szerepük az SVM-ben bevezetett
gyengítő változóknak felel meg. Látható, hogy a feltételekben az SVM osztályozóhoz képest (lásd (6.24) összefüggés) az egyenlőtlenség helyett egyenlőség szerepel, valamint hogy a célfüggvényben a hiba négyzete (
) jelenik meg.
Az osztályozó most is a szokásos bázisfüggvényes alakban írható fel:
(6.81)
ahol a
leképezés az SVM-ben is használt nemlineáris leképezés egy magasabb, M-dimenziós jellemzőtérbe.
A fenti egyenletekből az alábbi Lagrange kritérium írható fel:
, (6.82)
ahol az
értékek a Lagrange multiplikátorok, amelyek az egyenlőségi feltételek miatt itt pozitív és negatív értékeket is felvehetnek.
Az optimumra vonatkozó feltételek az alábbiak.
(6.83)
A fenti egyenletekből egy lineáris egyenletrendszer írható fel, mely az alábbi kompakt formában is megadható:
, (6.84)
ahol:
(6.85)
és I egy megfelelő méretű egységmátrix. Látható, hogy az egyenletrendszer első sora a
feltételt írja le, míg a további sorok a
feltételből adódó egyenleteket írják le, behelyettesítve a (6.83)-ban megadott derivált számításokból
-re és
-re származtatott összefüggéseket.
Az osztályozó válasza – hasonlóan a hagyományos SVM-hez – a következő alakban írható fel:
. (6.86)
Az
súlyok és a b eltolásérték (bias) a fenti egyenletrendszerből számíthatók. Az eredmény jellemzője, hogy a megoldásban az összes tanítópont szerepel, tehát mind szupport vektor, azaz az egyenlőség használata miatt nincsenek nulla súlytényezők. Ezzel elveszítjük az SVM ritkasági tulajdonságát, nevezetesen, hogy a bemeneti vektoroknak csak egy kis része lesz szupport vektor. Az
súlyok nagyság szerinti sorba rendezéséből látszik, hogy melyek a fontosabb, illetve melyek a kevésbé fontos bemeneti vektorok. Ezen alapul a később bemutatásra kerülő komplexitás redukciós metszési (pruning) eljárás, ami az SVM ritkasági tulajdonságát adja vissza.
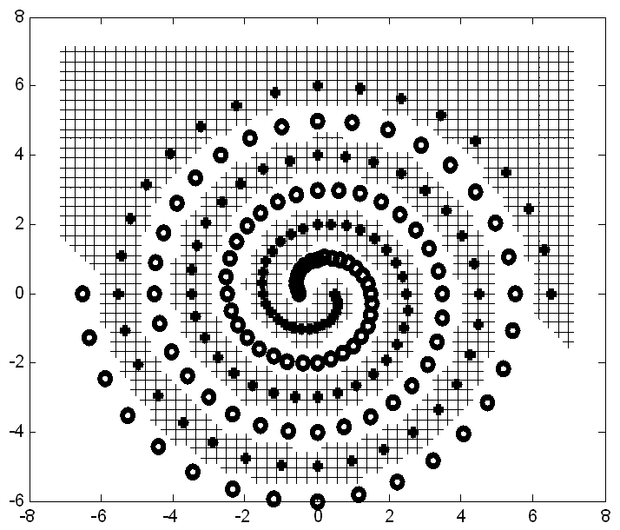
A 6.13 ábrán a szupport vektor gépek összehasonlításánál gyakran alkalmazott kettős spirál probléma LS-SVM-mel történő megoldását mutatjuk. Jól látható, hogy ennél az erősen nemlineáris feladatnál az LS-SVM – hasonlóan az SVM-hez – nagyon jól teljesít.
Az LS-SVM – hasonlóan az eddig látott hálózatokhoz – az osztályozós feladaton túl regressziós esetre is alkalmazható. Ekkor az eddigieknek megfelelően egy
függvény közelítése a cél adott
tanítópont-halmaz alapján, ahol
egy N-dimenziós bemeneti vektor és
a kívánt kimenet.
A regresszió esetén az optimálási feladat az alábbi:
(6.87)
a
, ahol
(6.88)
feltételekkel.
A regresszió válasza a következő alakban írható fel:
, (6.89)
ahol a
nemlineáris transzformáció most is a jellemzőtérbe való leképezést biztosítja. Az osztályozós esthez hasonlóan itt is felírhatunk egy Lagrange függvényt:
, (6.90)
ahol az
értékek a Lagrange multiplikátorok. Az optimumra vonatkozó feltételek az alábbiak.
(6.91)
A
és az
kifejezése után a következő lineáris egyenletrendszer írható fel:
(6.92)
ahol az
kivételével az egyenletrendszerben szereplő többi jelölés megegyezik a (6.85)-ben megadottakkal. Az
mátrix (i,j)-edik eleme :
,
. (6.93)
Az eredmény – hasonlóan a hagyományos SVM-hez – a következő alakban írható fel:
, (6.94)
ahol az
-k és
a fenti lineáris egyenletrendszer megoldásai.
Az egyenletrendszer felírása a parciális deriváltakból az osztályozós esetnél bemutatottak szerint történik. A regressziós esetben azonban az eredmény kiszámítása ((6.94) összefüggés) és az egyenletrendszer sorai között egyértelműen látszik a kapcsolat, nevezetesen, hogy az egyenletrendszer sorai a regularizációt (
) leszámítva pontosan megfelelnek az eredmény kiszámítására szolgáló összefüggésnek. Ez nem meglepő, hiszen a tanítópontok által reprezentált feltételek gyakorlatilag azt fogalmazzák meg, hogy az adott bemenetre milyen kimenetet várunk a modelltől. Ez a működés jól követhető a 6.10 ábrán. A tanítás során bevezetett regularizáció pedig megadja, hogy mennyire (mekkora hibával) kell illeszkedni a tanítópontokban. Az erősebb regularizáló hatás pontatlanabb illeszkedést követel és simább (egyszerűbb) megoldást, simább válaszfüggvényt eredményez.
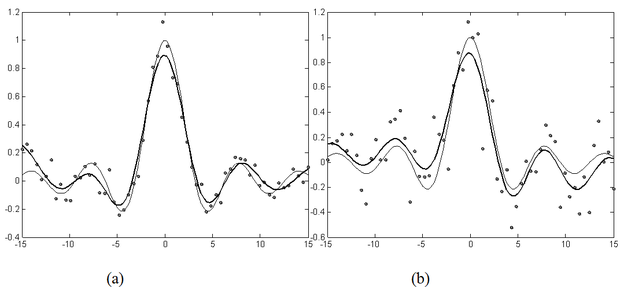
A 6.14 ábrán egy egyszerű példát mutatunk be LS-SVM használatával megoldott regressziós feladatra. Látható, hogy még jelentősebb mértékben zajos tanítópontok mellett is jó megoldást kapunk.
A Least-Squares megoldás egyik hátránya, hogy a megoldás nem ritka (sparse), hiszen mint láttuk, minden tanító vektor szupport vektor is egyben. Ha a végeredményt neurális hálózatként értelmezzük, akkor ebben P (azaz a felhasznált tanítópontok számával megegyező számú) nemlineáris neuron található, így az eredmény komplexitása (a háló mérete) nagyobb, mint a hagyományos SVM-mel nyert hálózatoké, melyek valóban szelektálnak a bementek közül. Ez abból is látszik, hogy a megoldásban felhasználjuk az
egyenletet, ami mutatja, hogy a i-edik tanítópontban kapott hiba arányos a tanítóponthoz, mint szupport vektorhoz tartozó
súllyal. Figyeljük meg, hogy a négyzetes hibafüggvényalkalmazása miatt az
sáv hiányában gyakorlatilag nincs 0 hibaérték, így nincs
érték sem. Ahhoz, hogy a hagyományos SVM ritkasági tulajdonságát visszanyerjük további lépésekre van szükség.
Intuitíven állíthatjuk, hogy a kisebb
-k kevésbé járulnak hozzá a megoldáshoz, azaz a kialakított modellhez. A következő „pruning” (metszési) eljárás egy ezen alapuló iteratív módszer, mellyel az LS-SVM alkalmazásánál is elérhető egy egyszerűbb eredmény, azaz kisebb hálózat. A megoldás menete az alábbi:
Tanítsuk a hálózatot az összes rendelkezésre álló (P) tanítóponttal.
Távolítsuk el egy kisebb részét (pl. 5%–át) a pontoknak úgy, hogy azokat hagyjuk el, melyekhez a legkisebb
-k tartoznak.
Tanítsuk újra az LS-SVM-et a kisebb tanítókészlettel.
Folytassuk a 2. lépéstől, amíg a válasz minősége nem romlik. Ha a teljesítmény romlik, akkor a hiperparaméterek (
és Gauss kernel esetén a
) hangolásával esetleg korrigálhatjuk, illetve még tovább csökkenthetjük a megoldás méretét.
A negyedik pontban említett hiperparaméter hangolásának oka jól látható például egy Gauss kerneles hálózat esetén. Ha a metszési (pruning) eljárás eredményeképpen csökken a kernelek száma, akkor az egymástól távolabb eső középpontok miatt gyakran növelni kell a Gauss függvények szélességét (
).
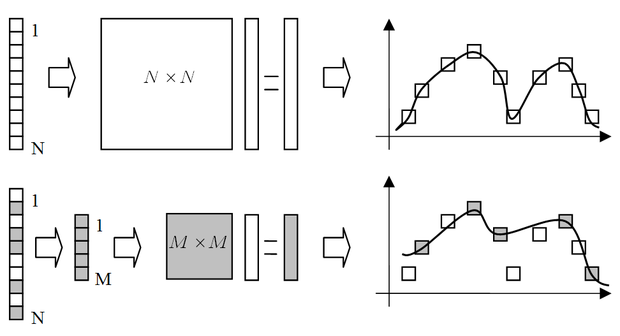
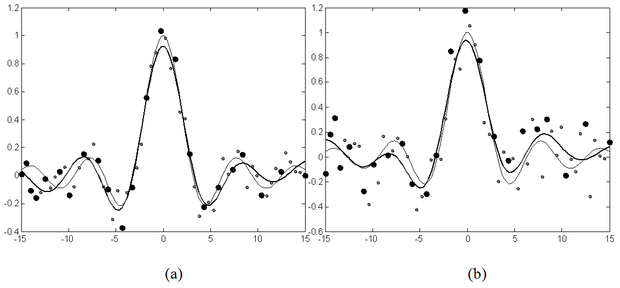
Fontos megjegyezni, hogy a metszési eljárás során, a minták elhagyásával gyakorlatilag a tanítókészlet méretét redukáljuk, ami – főként jelentősebb redukció esetén – információvesztéssel és így a háló minőségének romlásával jár(hat). Ez egyértelmű különbség a Vapnik-féle SVM-hez képest, hiszen ott a ritka megoldást úgy nyertük, hogy közben a Lagrange multiplikátorok meghatározásában az összes tanítópont részt vett. Ennek a kedvezőtlen hatásnak egyfajta mérséklését, vagy kiküszöbölését oldja meg a későbbiekben bemutatásra kerülő LS2-SVM. A mintapontok redukciójának hatását illusztrálja a 1.15 ábra. Az ábrán az üres négyzetek képviselik az összes tanítópontot, az árnyékolt négyzetek pedig a redukált mintakészlet pontjait.
A 6.16 ábrasorozat az eljárás valós példán történő futtatásának eredményét mutatja. Az (a) ábrán az eredeti LS-SVM megoldása látható. A további ábrák az egyre nagyobb mértékű redukció eredményét mutatják: a (b), (c) és (d) ábrákon egyre több pontot hagytunk el az eredeti tanítókészletből, miközben az approximáció minősége jelentősen nem változott.
A négyzetes hibafüggvény a nem normál eloszlású zaj (például kilógó minták, „outlier”-ek) esetén nem optimális, ezért ilyen tanítómintáknál a modellt egy további módosítással hangolhatjuk. A módszer, hasonlóan a „pruning”-hoz az
összefüggésen alapul. Ez az összefüggés azt mutatja, hogy az egyes pontokban kapott hiba, ei arányos az eredményként kapott αi súlyokkal. A módosított eljárás célja, hogy az egyes mintapontok szerepét a szerint mérlegelje, hogy ott mekkora a hiba. Ha ei nagy, akkor az ehhez tartozó mintapont kevésbé megbízható, tehát a teljes eljárásban a szerepét célszerű csökkenteni, míg a pontosabb mintapontok szerepét, ahol ei kisebb, érdemes növelni. Ezt a hatást egy újonnan bevezetett
súlykészlettel érjük el. Az optimalizálandó egyenlet (a regressziós esetre felírva) ekkor a következőképpen módosul:
. (6.95)
A tanítópontokra vonatkozó feltételek nem változnak:
,
. (6.96)
A lineáris egyenletrendszerben ez a következőket jelenti:
(6.97)
ahol a
az alábbi diagonál mátrix:
(6.98)
A
súlyokat az
értékek alapján választhatjuk meg, például a következők szerint:
(6.99)
ahol c1, c2 és s megválasztása a statisztikában ismert módszerek alapján történhet [Suy02].
Az algoritmus menete a következő:
-
Tanítsuk a hálózatot súlyozás nélkül az összes rendelkezésre álló (P) tanítóponttal és határozzuk meg az ei értékeket.
-
Határozzuk meg a vi súlyokat az előzőek ((6.99) összefüggés) szerint.
-
Számítsunk ki egy súlyozott LS-SVM modellt a vi súlyok segítségével.
Ez az eljárás iteratívan ismételhető, de a gyakorlatban egy súlyozó lépés általában elegendő.
Az LS2-SVM fő célja egy ritka LS-SVM megoldás elérése, csökkentve a modell komplexitását, azaz a rejtett rétegbeli nemlineáris neuronok számát. A módszer két fontos lépést tartalmaz:
-
Az első lépés átalakítja az LS-SVM megoldást úgy, hogy az a tanítópontoknak csak egy részhalmazát használja „szupport vektornak”. Ennek következtében egy túlhatározott egyenletrendszert kapunk, melynek LS megoldása adja az eredményt.
-
A második lépés a “szupport vektorok” (a kernel függvényeket meghatározó vektorok) automatikus meghatározására ad eljárást.
Túlhatározott egyenletrendszer
Az új megközelítés kiindulópontja az LS-SVM lineáris egyenletrendszere. Ha a tanító készlet P mintapontot tartalmaz, akkor az egyenletrendszer
ismeretlent, az
-kat és a b-t,
egyenletet és
együtthatót tartalmaz. Az együtthatók a
kernel függvény értékek. A mintapontok száma tehát meghatározza az egyenletrendszer méretét, ami egyúttal a megoldás komplexitását, a hálózat méretét is megszabja. Hogy ritka megoldást, azaz egy kisebb modellt kapjunk, az egyenletrendszert, illetve az együtthatómátrix méretét redukálni kell.
Vizsgáljuk meg közelebbről az LS-SVM regressziós problémát leíró egyenletrendszert és jelentését. Az első sor jelentése:
(6.100)
míg a j-edik sor a
(6.101)
feltételt, megkötést tartalmazza.
Az egyenletrendszer redukálásánál sorokat, illetve oszlopokat hagyhatunk el.
-
Ha a j-edik oszlopot hagyjuk el, akkor az ennek megfelelő
•
• kernel szintén “eltűnik”, így az eredményként megkapott hálózat mérete csökken. Az első sor által támasztott feltétel azonban automatikusan alkalmazkodik, hisz a megmaradó
•
• -k összege 0 marad.
-
Ha a j-edik sort töröljük, akkor az
•
• tanítópontnak megfelelő információ elvész, hiszen a j-edik megkötést elveszítjük.
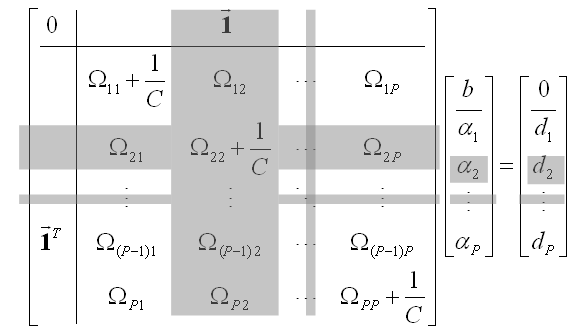
A fentiek alapján az egyenletrendszert leíró mátrix legfontosabb része a [
] részmátrix, ahol
az összes lehetséges tanítóvektor kombinációját tartalmazza (
). A mátrix redukálása során abból sorokat, oszlopokat, illetve mindkettőt (sort a hozzá tartozó oszloppal) törölhetünk.
Minden oszlop egy neuronnak felel meg, míg a sorok bemenet-kimenet relációkat, azaz a megoldás által teljesítendő feltételeket fogalmaznak meg. A mátrix az alábbi két módon redukálható:
Az
tanítópontot teljesen elhagyjuk, azaz mind a hozzá tartozó sort, mind pedig az oszlopot töröljük. Az alábbi egyenlet a tanító minták teljes elhagyásának hatását mutatja. A törölt elemeket szürkével jelöltük.
 (6.102)
(6.102)
A hagyományos metszési (pruning) technika esetében pontosan ez történik, hisz a metszési algoritmus iteratívan kihagyja a tanítópontok egy részét. Az elhagyott tanítópontok által hordozott információ ezért teljesen elvész. A tanítópontok által hordozott információ megőrzése a részleges redukció mellett lehetséges.
A
tanító mintát csak részben hagyjuk el, úgy, hogy töröljük a ponthoz tartozó oszlopot, de megtartjuk a hozzá tartozó sort. Így a tanítóminta által hordozott megkötés továbbra is érvényben marad, hisz az adott sor súlyozott összegének amennyire csak lehet egyezni kell a
kívánt kimenettel .
Ha kiválasztunk
(
) “szupport vektort” (oszlopot), de megtartjuk az összes megkötést (sort), az egyenletrendszer túlhatározottá válik. A részleges redukció hatását a mutatja a következő összefüggés, ahol a szürkével jelölt részeket távolítjuk el.
 (6.103)
(6.103)
A fentiek alapján kapott túlhatározott (
méretű) egyenletrendszert legkisebb négyzetes hiba értelemben oldhatjuk meg. Egyszerűsítsük a jelöléseinket úgy, hogy a fenti egyenletrendszer mátrix alakja legyen:
, (6.104)
melynek legkisebb négyzetes hibájú megoldása:
. (6.105)
Az oszlopok törlése a sorok megtartása mellet biztosítja, hogy a kernelek (neuronok) száma csökkenjen, miközben az eljárás az összes ismert megkötést (tanítómintát) figyelembe veszi. Ez a kulcsa annak, hogy a modell komplexitása a pontosság megtartása mellett is csökkenthető legyen.
Látható, hogy a kernel mátrix redukciója során az oszlopok elhagyásával a regularizálás „aszimmetrikussá” válik, hiszen a továbbiakban nem minden sorban szerepel regularizáció. Ennek kiküszöbölésére megtehető, hogy a regularizációt már csak a kernel térbeli megoldás során használjuk, ami a kernel térbeli margó maximalizálásnak (
minimalizálásának) felel meg. Ez hasonló az SV megoldások nemlineáris kiterjesztéséhez, ahol a w súlyvektor minimalizálása valójában a jellemző térben történik. A kernel térben regularizált megoldás:
, (6.106)
ahol
,
. (6.107)
A módosított, részlegesen redukált egyenletrendszert legkisebb négyzetes hibájú (least-squares) értelemben oldjuk meg, ezért nevezzük ezt a módszert Least Squares LS-SVM-nek vagy röviden LS2-SVM-nek [Val04].
Az itt bemutatott részleges redukció hasonlít a hagyományos SVM kiterjesztéseként bevezetett redukált szupport vektor gép (Reduced Support Vector Machine − RSVM) alapelvéhez [Lee01b]. Az RSVM esetén azonban, mivel az SVM eleve kisebb (ritka) modellt eredményez, a részleges redukció célja az algoritmikus komplexitás csökkentése, míg az LS-SVM esetében elsődlegesen a modell komplexitásának, a hálózat méretének csökkentése, azaz a ritka LS-SVM elérése a cél.
A fenti részleges redukció alkalmazása esetén szükség van valamilyen módszerre, ami meghatározza a szükséges szupport vektorokat. A kernel mátrix oszlopaiból kiválasztható egy lineárisan független részhalmaz, melynek elemeiből lineáris kombinációival a többi előállítható. Ez a kernel mátrix „bázisának” meghatározásával érhető el, hiszen az oszlopvektorok terének bázisa az a legkisebb vektorkészlet, amellyel a feladat megoldható. Ha a bázis meghatározásánál nem követeljük meg, hogy az oszlopvektorok által kifeszített tér és a kiválasztott bázisok által kifeszített tér azonos legyen, hanem bizonyos toleranciát is megengedünk, akkor a tolerancia mértékének meghatározásával egy szabad paramétert kaptunk. Ez a szabad paraméter lehetővé teszi, hogy kontroláljuk a bázisvektorok számát (M), hiszen a célunk az, hogy a P darab P-dimenziós oszlopvektorból M<P bázisvektort határozzunk meg, ahol M minél kisebb.
A bázisvektorok száma, ami egyben a szupport vektorok száma is, valójában nem függ a mintapontok számától (P), csak a probléma nehézségétől, hiszen M a mátrix lineárisan független oszlopainak száma. A gyakorlatban ez azt jelenti, hogy ha egy probléma nehézsége M neuront igényel, akkor a tanításhoz felhasznált mintapontok számától függetlenül a modell mérete nem növekszik.
A szupport vektorok kiválasztása az
mátrix RRE alakra (reduced row echelon form, RREF) hozása során részleges pivotolással végrehajtott Gauss-Jordan eliminációval történik [Pre02], [Gol89b] (ld. Függelék). A tolerancia figyelembevétele a pivot elem (p) ellenőrzésével lehetséges. Eredetileg a pivotolás lényege, hogy az elimináció végrehajtása során szükséges osztásban a lehető legnagyobb elemet használjuk fel a numerikus stabilitás érdekében. A kiválasztott pivot elem nagysága azonban információt hordoz arról is, hogy mennyire fontos a hozzá tartozó oszlop a pontos megoldáshoz. Ha
(ahol ε’ a tolerancia paraméter), akkor az adott oszlop elhagyható, ellenkező esetben az oszlopnak megfelelő bemenet egy szupport vektor. A módszer azon oszlopvektorok listáját adja meg, melyek az ε’ toleranciaérték értelmében lineárisan függetlenek.
A megfelelő tolerancia helyes meghatározása hasonló a többi hiperparaméter (C, ε, valamint a kernel paraméterek) megválasztásához. Egy lehetséges megoldás a kereszt kiértékelés (cross-validation) alkalmazása. Minél nagyobb a tolerancia, annál kisebb a hálózat, és annál nagyobb az approximáció hibája. Az ε’ helyes megválasztása egy olyan kompromisszum alapján lehetséges, ahol a pontos approximáció, illetve a modell komplexitása áll szemben egymással.
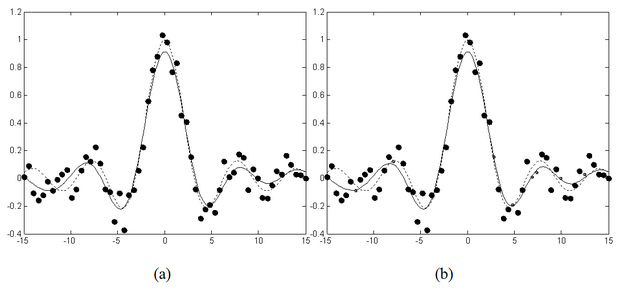
A 6.17 ábra zajos mintapontok mellett mutatja az LS2-SVM eredményét. Fontos hangsúlyozni, hogy nulla tolerancia esetén az LS2-SVM és az LS-SVM megoldás azonos, mivel ebben az esetben a kiválasztási módszer a mátrix minden oszlopát, azaz az összes tanítómintát megtartja (kivéve, ha a tanítópontok között volt redundancia).
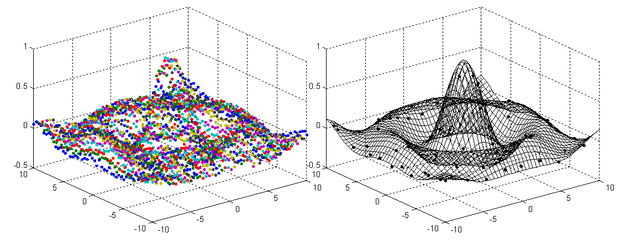
Az alábbiakban az LS2-SVM alkalmazására mutatunk két mintapéldát. A 6.18 ábrán egy kétdimenziós sinc függvény LS2-SVM-mel történő approximációja látható. A bal oldali ábra a kiinduló tanítópontokat mutatja, a jobboldali pedig a megoldást, ahol külön megjelennek az eljárás által meghagyott tanítópontok (szupport vektorok) is. Láthatóan a tanítópontok elenyésző töredéke elég a megfelelően pontos approximáció eléréséhez. A 6.19 ábra a klasszikus kettős spirál probléma megoldását adja meg. A módszer hatékonyságnövelő hatása itt is jól követhető.
Az LS-SVM-nél megmutattuk, hogy egy iteratív eljárással súlyozott megoldás is adható, ami zajos esetben, főként kilógó minták (outlierek) esetén jelentősen jobb megoldásra vezet.
Amennyiben ismert vagy becsülhető a tanító mintákat terhelő zaj mértéke, ezt az információt az LS2-SVM esetén is fel lehet használni. A mintapontok azonos kezelése helyett ebben az esetben a pontosabb mintákat nagyobb, a pontatlan, azaz zajos mintákat kisebb súllyal célszerű figyelembe venni. A hiba súlyozott számítása:
(6.108)
A túlhatározott LS2-SVM egyenletrendszer súlyozott megoldása az előbbiekben bevezetett átírást alkalmazva:
, (6.109)
ahol a V súlyozó mátrix egy diagonálmátrix, amely a főátlóban a
súlyokat tartalmazza. A súlyokat úgy kell beállítani, hogy jól tükrözzék az egyes tanítóminták hatását a lineáris illesztésre. A zaj mértéke, illetve a súlyozás meghatározható egy előzetes megoldás alapján (vagy a priori információ alapján), de a túlhatározott egyenletrendszer megoldására használhatunk olyan statisztikai megoldó módszereket is, amelyek csökkentik a nagyon hibás adatok hatását. Ilyen például a Least Absolute Residuals – LAR, a Bisquare weights vagy a Least Trimmed Squares - (LTS) módszer [Ciz04], [Hol77], [Hub81].
A fejezet elején egy egyszerű kernel gép származtatásánál láttuk, hogy a négyzetes hiba minimalizálását célzó lineáris gép értelmezhető kernel gépként is. A megoldást a tanítópontok bemeneti vektoraiból képezett mátrix pszeudo-inverze segítségével tudtuk meghatározni (ld. (6.8) összefüggés) A könnyebb követhetőség miatt ezt az összefüggést itt megismételjük.
. (6.110)
Azt is megmutattuk, hogy az így származtatott súlyvektorral kapott háló kernel gépként is értelmezhető, ahol a választ az alábbi formában is felírhatjuk:
. (6.111)
Amennyiben az
mátrix rangja nem teljes, vagy bármilyen pl. numerikus instabilitás miatt nem invertálható, a következőképp módosított összefüggés alapján nyerhető a megoldás:
, (6.112)
ahol I az
mátrixnak megfelelő méretű egységmátrix, λ pedig egy kis pozitív konstans. Ez az összefüggés valójában a rosszul kondicionált mátrixok invertálásánál alkalmazott regularizációs eljárás, ami a matematikában Tyihonov regularizációnéven is ismert. Erre az összefüggésre azonban több úton is eljuthatunk. A fenti megoldás a Tyihonov regularizációtól függetlenül az ún. ridge regresszió (ridge regression) [Hoe70] útján is származtatható.
A következőkben röviden bemutatjuk a ridge regresszió származtatását és azt, hogy a ridge regresszió és az LS-SVM probléma-megfogalmazása, és így a megoldás is lényegében azonos. Mivel ez a tárgyalás főként a neurális modellekhez, illetve a szupport vektor gépekhez kapcsolódik, a ridge regressziós eljárásra csak röviden térünk ki. A ridge regressziót többnyire eltolásérték (bias) nélkül alkalmazzák, a következőkben itt is ezt a változatot mutatjuk be.
Lineáris ridge regresszió
A korábban bemutatott osztályozási problémának megfelelően itt is az
tanító mintakészlet alapján keressük az
lineáris modellt. A ridge regresszió is a négyzetes hibát minimalizálja, de az LS-SVM-hez hasonlóan közben a súlyvektor hosszának minimumát is biztosítani szeretné, ami regressziós feladatoknál a minél laposabb megoldást biztosítja [Sch02]. Ennek megfelelően a
súlyvektort ridge regresszióval a következőképpen határozzuk meg. Jelölje J(w) most is a minimalizálandó kritériumfüggvényt (az 1/2-es szorzó a deriválás utáni eredmény egyszerűsítése miatt szerepel):
(6.113)
A
parciális deriválás eredményéből az optimális w az alábbiak szerint számítható:
(6.114)
(6.115)
Mátrix alakban felírva (ahol
a tanítópontok kívánt válaszaiból képezett vektor és X az
tanítóminta-bemenetekből, mint sorvektorokból képezett mátrix):
, (6.116)
a megoldás súlyvektor:
. (6.117)
Az
(6.118)
jelölés bevezetésével
(6.119)
így a végeredmény:
(6.120)
Vegyük észre, hogy ez a felírás egy kis különbséggel megegyezik a 6.1 részben bevezetett egyszerű kernel gép összefüggéseivel. A kis különbség abból adódik, hogy itt a kiinduló kritériumfüggvény a súlyvektor hosszának négyzetét, mint minimalizálandó mennyiséget, is tartalmazza. Ennek következménye a w illetve az
vektorok összefüggéseiben ((6.117), illetve (6.118) összefüggések) a
regularizációs tag megjelenése. A ridge regresszió tehát az egyszerű kernel gép regularizált változata. Azt is észrevehetjük, hogy ez az eredmény megegyezik az eltolás-érték nélküli lineáris LS-SVM-re kapott összefüggéssel.
Természetesen a ridge regresszió is kiterjeszthető nemlineáris esetre a szokásos
transzformáció, és a kernel trükk alkalmazásával.
Nemlineáris kernel ridge regresszió
A nemlineáris ridge regresszió esetén – csakúgy, mint az SVM vagy az LS-SVM kiterjesztésénél – a lineáris regressziós modellt egy magasabb dimenziós térben, a jellemző térben alkalmazzuk, ami a szokásos módon egy nemlineáris transzformáció eredménye.
A ϕ(.) leképezés segítségével a lineáris esetben megismert célfüggvény a következőképpen módosul:
(6.121)
ahol:
,
. (6.122)
Az LS-SVM regressziónál bemutatott lépéseknek megfelelően az
Lagrange-függvény írható fel az
(
) Lagrange együtthatókkal. A deriválások után a kernel trükk alkalmazásával az alábbi megoldás nyerhető (mátrix alakban):
, (6.123)
ahol az
a tanítómintákból képzett kernel mátrix. Látható, hogy a nemlineáris eset itt is a kernel térben kerül megoldásra. A megoldás ugyanakkor megfelel egy regularizált kernel térbeli megoldásnak. Ez annyit tesz, hogy a
jellemzőtérbeli minimalizálása az
kernel térbeli minimalizálására vezet.
A kernel ridge regressziós modell:
, (6.124)
ami a regularizációtól eltekintve ismét megegyezik az egyszerű nemlineáris kernel gép válaszával (ld. (6.14) összefüggés).
Csökkentett rangú kernel ridge regresszió
Az eredeti ridge regressziós megoldásokban a kernel mátrix négyzetes, ami azt jelenti, hogy a modell a tanító pontoknak megfelelő számú szupport vektort tartalmaz, azaz nem ritka. A csökkentett rangú kernel ridge regresszió (Reduced Rank Kernel Ridge Regression - RRKRR) [Caw02] eljárás a ritka megoldást a kernel mátrix redukciójával éri el. Az RRKRR eljárás tehát hasonló célt tűz ki, mint az LS2-SVM, a célhoz azonban más úton jut el.
Az eljárást eltolásérték (bias) alkalmazása mellett mutatjuk be, hogy az eredmény összevethető legyen az LS-SVM eredményével.
A ritka megoldáshoz az approximációban felhasznált kernel függvények – azaz a kernel középpon-toknak megfelelő szupport vektorok – számát kell csökkenteni. Az eredeti ridge regresszió (és természetesen az LS-SVM is) olyan kernel mátrixot használ fel, ahol mind az oszlopok, mind a sorok számát a tanítópontok száma határozza meg, hiszen minden tanítópont egy kernel középpont – ezek felelnek meg az oszlopoknak – és ugyanakkor minden tanítópont a jellemzőtérben egy lineáris egyenletet is jelent – ezek felelnek meg a soroknak. Az RRKRR eljárás az oszlopok számát redukálja úgy, hogy a tanítópontokból kiválaszt egy részhalmazt – ezek fogják képezni a kernel középpontokat –, és megtartja az összes tanítópontot, tehát megtartja a sorok számát. Az RRKRR eljárás tehát az LS2-SVM-hez hasonlóan részleges redukciót alkalmaz.
Az oszlopok kiválogatásához az alábbiakból indulhatunk ki. Az LS-SVM (6.83) és (6.91) összefüggései a w súlyvektort, mint a
jellemzőtérbeli vektorok súlyozott összegét fejezik ki.:
(6.125)
Ez azt jelenti, hogy a súlyvektorok terét a
vektorok meghatározzák; mint bázisvektorok kifeszítik a teret. Kérdés azonban, hogy az összes
, i=1,…,P jellemzőtérbeli vektorra szükség van-e a súlyvektor (adott pontosságú) reprezentációjához. Tételezzük fel, hogy ehhez a tanítópontok egy S részhalmaza elegendő. Ekkor a w súlyvektor felírható az S részhalmazba tartozó jellemzővektorok súlyozott összegeként:
. (6.126)
Ha ez a megadás pontos, akkor az S-be tartozó
vektorok is kifeszítik a súlyvektorok terét, tehát bázist alkotnak ebben a térben. Ha S elemeinek száma kisebb, mint P, eredményként ritka megoldást kapunk. Természetesen itt a βi súlyok különbözni fognak az (6.125) szerinti megadás
α i súlyaitól.
Ha az S részhalmazba tartozó jellemzővektorok bázist alkotnak a jellemzőtérben, akkor bármely x bemenet jellemzőtérbeli képe is kifejezhető, mint az S-beli
vektorok lineáris kombinációja.
. (6.127)
Ha a bázisvektorok
-nek csak közelítő reprezentációját,
-et adják, akkor olyan bázisfüggvényeket kell kiválasztanunk, melyek mellett ez a közelítés a legkisebb hibájú. A hibát most mint a két vektor normalizált euklideszi távolságát definiálhatjuk:
. (6.128)
Megmutatható [Bau01], hogy ez a hiba a kernel trükk felhasználásával a kernel mátrix segítségével is felírható:
. (6.129)
ahol
a K kernel mátrix almátrixa:
,
pedig egy belső szorzatokból képezett oszlopvektor, míg kjj = Kjj, a kernel mátrix j-edik főátlóbeli eleme.
A jellemzőtér bázisának meghatározásához az így definiált hiba átlagát kell minimalizálni a tanítókészlet összes pontját tekintetbe véve. Vagyis maximalizálni kell a
(6.130)
mennyiséget. Az eljárást az üres halmazzal, vagyis
-val indítjuk, és mohó stratégiát alkalmazunk. Minden egyes lépésben azt a tanítóvektort adjuk S–hez, mely a (6.130) kifejezést maximálja. Az eljárás magától leáll, ha
már nem invertálható, jelezve, hogy a megfeleleő bázist megtaláltuk, illetve leállítható, ha a hiba adott korlát alá csökken vagy egy előre meghatározott számú bázisvektort már kiválasztottunk.
Mivel a súlyvektor (6.126) szerint kifejezhető S-be tartozó bázisvektorok lineáris kombinációjaként, a következő duális egyenletet kapjuk, melyet
és b szerint kell minimalizálnunk.
. (6.131)
A
és
szerinti parciális deriváltak alapján megkeresve a minimumhelyeket, valamint ezt C-vel leosztva az alábbi egyenletet kapjuk:
(6.132)
és
(6.133)
A fenti egyenletek az alábbi
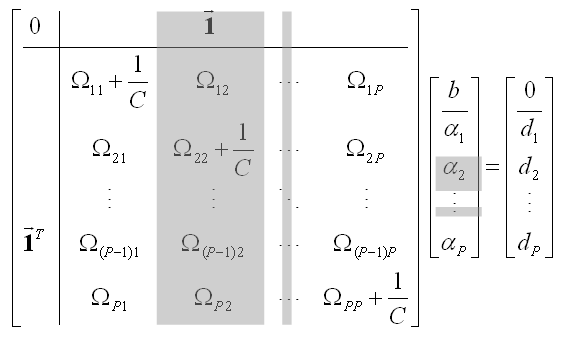
méretű lineáris egyenletrendszerre vezetnek (
az S halmaz elemeinek a száma):
, (6.134)
ahol
,
,
c pedig egy olyan
-dimenziós vektor, melynek r-edik eleme:
Az egyenletrendszer megoldása egy csökkentett rangú (bázisú) ritka megoldásra vezet, mivel az csak
számú kernelt és az eltolást tartalmazza.