20.5. Neurális hálók
A neuron egy olyan agysejt, amelynek alapfeladata elektromos jelek összegyűjtése, feldolgozása és szétterjesztése. A 1.2.4. szakasz - Neurális tudományok (1861-től napjainkig) részben az 1.2. ábra egy tipikus neuron sematikus rajzát mutatja. Azt gondoljuk, hogy az agy információfeldolgozó kapacitása elsősorban ilyen neuronok hálózatából alakul ki. Ezért a korai MI néhány kutatása mesterséges neurális hálók (neural networks) létrehozására irányult. (A terület más, szintén használt elnevezései: konnekcionizmus [connectionism], párhuzamos elosztott feldolgozás [parallel distributed processing] és neurális számítástechnika [neural computation].) A 20.15. ábra a neuron egyszerű matematikai modelljét mutatja, ahogy McCulloch és Pitts (McCulloch és Pitts, 1943) megalkották. Elnagyolva az mondható, hogy a neuron akkor „tüzel”, amikor a bemeneti értékek súlyozott összege meghalad egy küszöböt. 1943 óta sokkal részletesebb és valósághűbb modelleket alkottak mind a neuronra, mind az agy nagyobb rendszereire, ez vezetett a számítógépes idegháló-modellezés (computational neuroscience) modern tudományterületének megjelenéséhez. Másrészt az MI és a statisztika kutatóinak érdeklődését felkeltették a neurális hálózatok absztraktabb tulajdonságai, mint például az elosztott számítás elvégzésére, a bemeneti zajjal szembeni érzéketlenségre és a tanulásra való képesség. Bár ma már tudjuk, hogy más rendszerek, például a Bayes-hálók is rendelkeznek ezekkel a tulajdonságokkal, de a neurális háló maradt a tanuló rendszerek egyik leghatékonyabb és legnépszerűbb formája, ezért megéri külön tárgyalni.
20.15. ábra - A neuron egyszerű matematikai modellje. Az egység kimeneti aktivációja  ahol aj a j-edik egység kimeneti aktivációja és Wj,i a j-től i-ig vezető összeköttetés súlya.
ahol aj a j-edik egység kimeneti aktivációja és Wj,i a j-től i-ig vezető összeköttetés súlya.
ahol aj a j-edik egység kimeneti aktivációja és Wj,i a j-től i-ig vezető összeköttetés súlya.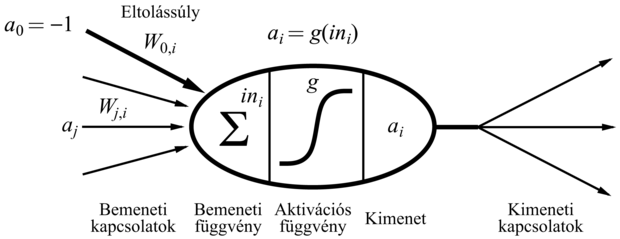
A neurális hálók irányított kapcsolatokkal (link) összekötött csomópontokból vagy egységekből (unit) állnak. A j-edik egységtől az i-edik felé vezető kapcsolat hivatott az aj aktivációt j-től az i-ig terjeszteni. Minden egyes kapcsolat rendelkezik egy hozzá aszszociált Wj,i numerikus súllyal (weight), ami meghatározza a kapcsolat erősségét és előjelét. Minden egyes i egység először a bemeneteinek egy súlyozott összegét számítja ki:
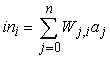
A kimenetét úgy kapja, hogy ezek után egy g aktivációs függvényt (activation function) alkalmaz a kapott összegre:

Figyeljük meg, hogy használtunk egy eltolássúlyt (bias weight) W0,i-t, amelyet egy rögzített értékű a0 = –1 bemenetre kapcsolunk. Rövidesen megmagyarázzuk, hogy mi a jelentősége.
Az aktivációs függvénnyel szemben két elvárásunk van. Először az, hogy az egység legyen „aktív” (+1 körüli kimenet), ha a „helyes” bemeneteket kapja, és „inaktív” (0 körüli kimenet), ha „rossz” bemeneteket kap. Másodszor az, hogy az aktiváció legyen nemlineáris, különben az egész neurális háló egy egyszerű lineáris függvénnyé fajul (lásd 20.17. feladat). A 20.16. ábra kétféle aktivációs függvényt mutat be: a küszöbfüggvényt (threshold function), illetve a szigmoid függvényt (sigmoid function) (mely utóbbi logisztikus függvényként [logistic function] is ismert). A szigmoid függvény előnye, hogy differenciálható, ami – mint később látni fogjuk – fontos a súlytanulási algoritmus szempontjából. Vegyük észre, hogy mindkét függvénynek van egy küszöbpontja (akár kemény, akár lágy) a nullánál; az eltolássúly állítja be az egység aktuális küszöbpontját. Ez azt jelenti, hogy az egység akkor aktiválódik, ha a „valódi” bemenetek súlyozott összege 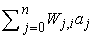 meghaladja W0,i-t.
meghaladja W0,i-t.
20.16. ábra - (a) A küszöb aktivációs függvény, amely 1-et ad a kimeneten, ha a bemenete pozitív, különben pedig 0-t. (Néha az előjelfüggvényt is használják ehelyett, amely ±1-et ad a bemenet előjelétől függően.) (b) A szigmoid függvény 1/(1+e–x).
20.17. ábra - Megfelelő bemeneti és eltolássúlyokkal rendelkező, küszöbaktivációjú egységek képesek logikai kapuként működni
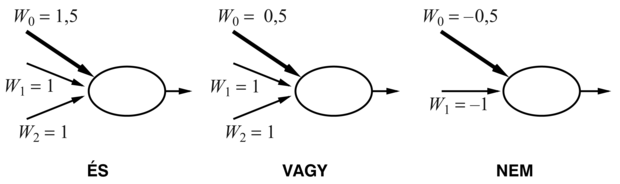
Némi fogalmunk alakulhat ki az egyes egységek működéséről, ha összehasonlítjuk őket a logikai kapukkal. Az egyes egységek tervezésének eredeti motivációi között (McCulloch és Pitts, 1943) szerepelt az, hogy képesek az alapvető logikai függvények reprezentálására. A 20.17. ábra bemutatja, hogy az és, vagy és nem logikai függvények hogyan reprezentálhatók egy megfelelő súlyokkal rendelkező küszöbegység segítségével. Ez azért fontos, mert azt jelenti, hogy ezen egységek felhasználásával tetszőleges logikai függvény kiszámítására tudunk hálózatot építeni.
A neurális hálóstruktúrák két fő csoportja: a hurokmentes vagy előrecsatolt hálók (feed-forward network) és a visszacsatolt vagy rekurrens hálók (recurrent network). Az előrecsatolt háló a pillanatnyi bemenet függvényét reprezentálja, azaz nincs semmilyen más belső állapota, csak maguk a súlyok. A rekurrens háló viszont a kimeneteit visszacsatolja a bemeneteire. Ez azt jelenti, hogy a háló aktivációs szintjei dinamikus rendszert alkotnak, elérhetnek stabil állapotot, de mutathatnak oszcillációt, sőt kaotikus viselkedést is. Ezenfelül a háló egy adott bemenetre adott válasza a kezdeti állapotától függ, amely a korábbi bemenetektől függhet. Ennélfogva a rekurrens hálók (ellentétben az előrecsatolt hálókkal) rövid távú memóriát is biztosíthatnak. Ezáltal érdekesebbé válnak mint agymodellek, de egyben nehezebben is érthetők. Ez a rész az előrecsatolt hálókra koncentrál, a fejezet végén néhány hivatkozást adunk, segítve a rekurrens hálók további tanulmányozását.
Nézzük meg közelebbről azt az állítást, hogy az előrecsatolt háló a bemeneteinek függvényét reprezentálja. Vizsgáljuk a 20.18. ábra egyszerű hálózatát, amelynek két bemeneti egysége, két rejtett egysége (hidden unit) és egy kimeneti egysége van. (Az egyszerűség kedvéért ebben a példában elhagytuk az eltolásegységeket.) Adott x = (x1, x2) bemeneti vektor esetén a bemeneti egységek aktivációja (a1, a2) = (x1, x2), és a hálózat a következő számítást végzi:
a5 = g(W3,5a3 + W4,5a4)
= g(W3,5g(W1,3a1 + W2,3a2) + W4,5g(W1,4a1 + W2,4a2)) (20.11)
Azaz kifejezve a rejtett egységek kimenetét, mint a saját bemeneteik függvényét, megmutattuk, hogy az egész háló a5 végső kimenete a háló bemeneteinek függvénye. Továbbá azt látjuk, hogy a háló súlyai ennek a függvénynek a paramétereiként szolgálnak; ha W-vel jelöljük a paramétereket, akkor a háló a hW(x) függvényt számítja ki. Ha változtatjuk a súlyokat, akkor változik a háló által reprezentált függvény. Ez a módja a neurális hálók tanulásának.
A neurális hálót osztályozásra vagy regresszióra használhatjuk. Ha folytonos kimenete van a hálónak (pl. szigmoid egységekkel), akkor logikai osztályozás esetén hagyományosan egy kimeneti egységet használunk, és ha ennek aktivációs értéke 0,5 feletti, azt az egyik, ha 0,5 alatti, akkor a másik osztályba tartozásként interpretáljuk. Egy k osztályos osztályozási feladatnál feloszthatjuk az egyetlen kimeneti egység értéktartományát k részre, de megszokottabb, hogy ehelyett k elkülönült kimeneti egységet használjunk, ahol mindegyiknek az aktivációs értéke a bemenet adott osztályba tartozásának valószínűségét reprezentálja.
Az előrecsatolt hálókat rendszerint rétegekbe (layer) szervezzük oly módon, hogy minden egyes egység csak a közvetlenül megelőző réteg egységeitől kap bemeneti jelet. A következő két alfejezetben egyrészt az egyrétegű hálózatokkal foglalkozunk, amelyeknek nincsenek rejtett egységei, másrészt a többrétegű hálókkal, amelyek egy vagy több rejtett réteggel rendelkeznek.
20.18. ábra - Egy nagyon egyszerű, két bemeneti egységgel, egyetlen – két egységből álló – rejtett réteggel és egy kimeneti egységgel rendelkező háló

Azt a hálót, amelyben az összes bemenet közvetlenül a kimenetekre kapcsolódik egyrétegű neurális hálónak (single layer neural network) vagy perceptron (perceptron) hálónak nevezzük. Mivel mindegyik kimeneti egység független a többitől – mindegyik súly csak egyetlen kimenetre van hatással – vizsgálatainkat korlátozhatjuk az egykimenetű perceptronra, mint azt a 20.19. (a) ábra magyarázza.
Kezdjük annak a hipotézistérnek a tanulmányozásával, amelyet egyetlen perceptron reprezentálhat. Küszöbaktivációs függvény esetén úgy tekinthetjük a perceptront, mint ami logikai függvényt reprezentál. Az elemi logikai függvényeken (és, vagy és nem, lásd 20.17. ábra) túl a perceptron képes néhány egészen „bonyolult” logikai függvényt is nagyon tömören reprezentálni. Például a többségfüggvényt (majority function), amely csak akkor ad ki 1-et, ha n bemeneteinek több mint fele 1, egy olyan perceptron reprezentál, amelynek minden súlya Wj = 1 és a küszöb W0 = n/2. Egy döntési fának O(2n) csomópontra lenne szüksége ennek a függvénynek a reprezentálásához.
Sajnos számos olyan logikai függvény van, amelyet a küszöbfüggvényt használó perceptron nem tud reprezentálni. A (20.10) egyenletet vizsgálva látjuk, hogy a küszöbérték-perceptron akkor és csak akkor ad 1-et, ha bemeneteinek (beleértve az eltolás- bemenetet is) súlyozott összege pozitív:
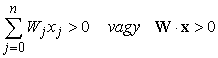
20.19. ábra - (a) Egy perceptronhálózat három kimeneti egységből, amelyeknek öt közös bemenete van. Ha kiválasztunk egy kimeneti egységet (mondjuk a másodikat, vastag vonallal kiemelve), akkor azt látjuk, hogy bemeneti összeköttetései nincsenek semmilyen hatással a többi kimeneti egységre. (b) Egy kétbemenetű szigmoid aktivációs függvényű perceptronegység kimenetének ábrázolása.
Fontos
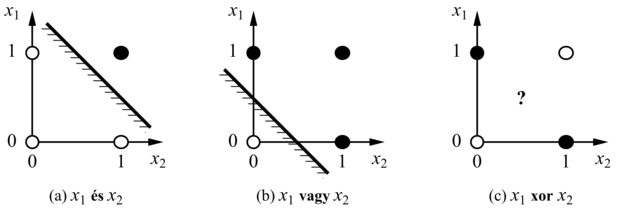
A W · x = 0 egyenlet egy hipersíkot határoz meg a bemeneti térben, tehát a perceptron akkor és csak akkor ad 1-et, ha a bemenet ennek a hipersíknak az egyik oldalán van. Ezért a küszöbperceptront lineáris szeparátornak (linear separator) is nevezik. A 20.20. (a) és (b) ábra mutatja a szeparáló hipersíkot (ami két dimenzióban egy egyenes) a kétbemenetű és, illetve vagy függvények perceptronreprezentációja esetén. Fekete pötty jelzi a bemeneti tér olyan pontjait, amelyekre a függvény értéke 1, fehér pötty pedig az olyan pontokat, amelyre 0 ez az érték. A perceptron azért képes reprezentálni ezt a függvényt, mert létezik olyan egyenes, ami az összes fehér pontot az összes feketétől elválasztja. Az ilyen függvényeket lineárisan szeparálhatónak (linearly separable) nevezzük. A 20.20. (c) ábra egy olyan függvényre mutat példát, amely nem szeparálható lineárisan – ez az xor függvény. Nyilvánvalóan nincs lehetőség arra, hogy egy küszöbperceptron megtanulja ezt a függvényt. Általánosságban elmondható, hogy egy küszöbperceptron csak lineárisan szeparálható függvények reprezentációjára képes. Ez a függvényeknek csak kis töredékét jelenti; a 20.14. feladat azt kéri, hogy fejezze ki számszerűen, mekkora is ez a töredék. A szigmoiddal felépített perceptronok hasonlóképpen korlátozott képességűek abban az értelemben, hogy csupán „lágy” lineáris szeparátorokat reprezentálnak. (Lásd 20.19. (b) ábra.)
20.20. ábra - Lineáris szeparálhatóság küszöbperceptronok esetén. Fekete pötty jelzi a bemeneti tér olyan pontjait, amelyekre a függvény értéke 1, fehér pötty pedig az olyan pontokat, amelyre 0 ez az érték. A perceptronkimenet az egyenes nem árnyékolt oldalán 1. A (c) esetben nincs olyan egyenes, amely jól osztályozná a bemeneteket.
Fontos
Korlátozott kifejezőképessége ellenére a küszöbperceptronnak vannak előnyei is. Különösen is fontos, hogy létezik olyan egyszerű tanuló algoritmus, amely a küszöbperceptront tetszőleges lineárisan szeparálható adathalmazra képes illeszteni. Mégsem mutatjuk most be ezt, inkább levezetünk egy ehhez közel álló tanuló algoritmust a szigmoid perceptronokra.
Ennek az algoritmusnak az az alapgondolata (valójában a neuronháló tanuló algoritmusok legtöbbjének is ez), hogy a tanító mintahalmazon mért hiba valamilyen mértékének minimalizálása érdekében módosítjuk a neuronháló súlyait. Tehát a tanulást formálisan a súlytérben (weight space) végzett optimalizálási keresésként fogalmazzuk meg.[202] A hiba „klasszikus” mértéke a négyzetes hibaösszeg, amit a lineáris regressziónál a 20.2.3. szakasz - Maximum-likelihood paramétertanulás: folytonos eset részben is használtunk. Egyetlen, x bemenettel és y kívánt kimenettel megadott példa négyzetes hibája a következőképpen írható fel:
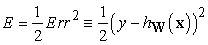
ahol hW(x) a perceptron kimeneti értéke.
A négyzetes hiba csökkentésére gradiensalapú optimalizálási eljárást használhatunk, ehhez az E minden egyes súlyra vonatkozó parciális deriváltját meg kell határoznunk. Tehát:
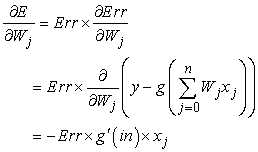
ahol g' az aktivációs függvény deriváltja.[203] Amikor a gradiensalapú algoritmusban csökkenteni akarjuk E-t, a súlyfrissítés összefüggése a következő:
Wj ← Wj + α × Err × g'(in) × xj (20.12)
ahol α a bátorsági faktor (vagy tanulási faktor, learning rate). Intuitíve ez nagyon ésszerű. Ha a hiba Err = y – hW(x) pozitív, akkor a háló kimenete túl kicsi, tehát a pozitív bemenetekhez tartozó súlyokat növeljük, a negatívakhoz tartozókat pedig csökkentjük. Ha a hiba negatív, akkor éppen ennek ellenkezője történik.[204]
A teljes algoritmus a 20.21. ábrán látható. Egyesével sorban végigfuttatja a mintákat a hálón, és minden egyes példa után a hiba csökkentése érdekében kissé módosítja a súlyokat. A mintahalmaz egyszeri végigfuttatását epochnak (epoch) nevezzük. Az epochokat addig ismételjük, amíg valamilyen leállási feltétel nem teljesül – tipikus, hogy akkor állunk le, amikor a súlyváltozások már nagyon kicsivé válnak. Más módszerek esetén eredő gradienst számítunk az egész tanító halmazra, egyszerűen összeadva az egyes példáknál a (20.12) származó gradienseket, és az eredő gradiens alapján frissítjük a súlyokat. A sztochasztikus gradiens (stochastic gradient) módszer nem ciklikusan veszi a tanító halmaz mintáit, hanem inkább véletlenszerűen választ mintákat a tanító halmazból.
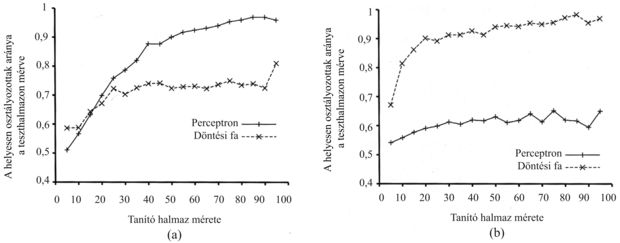
A 20.22. ábra két különböző problémára bemutatja a perceptron tanulási görbéjét. A bal oldali ábrán a 11 logikai bemenetre vonatkozó többségfüggvény (tehát a kimenet akkor 1, ha 6 vagy több bemenet 1) tanulási görbéje látható. Várakozásunknak megfelelően a perceptron meglehetősen gyorsan tanulja a függvényt, mivel a többségfüggvény lineárisan szeparálható. Másrészről viszont a döntési fa tanuló nem nagyon halad a tanulással, mert a többségfüggvényt nagyon nehéz (bár nem lehetetlen) döntési fában reprezentálni. A jobb oldali ábrán az étterem példa látható. A probléma megoldása könnyen ábrázolható döntési fával, de lineárisan nem szeparálható. Az adatokra felvett legjobb szeparáló sík csak 65%-ot osztályoz helyesen.
20.21. ábra - A gradiensalapú perceptron tanulási algoritmus, feltételezve, hogy a g aktivációs függvény differenciálható. Küszöbperceptronokra elhagyjuk a g'(in) faktort a súlyfrissítésből. A
NEURÁLIS-HÁLÓ-HIPOTÉZIS függvény egy olyan hipotézist ad vissza, amely bármely bemenetre kiszámítja a háló válaszát.
Az eddigiekben úgy tekintettük a perceptronokat, mint olyan determinisztikus függvényeket, amelyeknek valószínűleg hibával terhelt a kimenete. Lehetőségünk van, hogy a szigmoid perceptron kimenetét valószínűségként interpretáljuk – annak valószínűségeként, hogy adott bemenetek esetén a valós kimenet 1. Ezzel az interpretációval úgy használhatjuk a szigmoidot, mint a Bayes-hálók feltételes eloszlásainak kanonikus reprezentációját (lásd 14.3. alfejezet). Levezethetünk egy tanuló algoritmust is, a standard módszernek megfelelően maximalizálva az adatok (feltételes) log likelihood értékét, amint ezt a fejezet korábbi részében ismertettük. Lássuk, hogyan is működik ez.
20.22. ábra - A perceptronok és döntési fák teljesítményének összehasonlítása. (a) A perceptronok jobbak a 11 bemenetű többségfüggvény tanulásában. (b) A döntési fák jobbak az étterem példában a VárjunkE predikátum tanulásában.
Vegyünk egyetlen tanító példát, amelynek kívánt kimeneti értéke T, és legyen erre a példára a perceptron válasza p. Ha T = 1, akkor az adat feltételes valószínűsége p, ha T = 0, akkor a feltételes valószínűség (1 – p). Egy egyszerű trükk alkalmazásával a log likelihoodot differenciálható formában írhatjuk fel. A trükk az, hogy ha a 0/1 változót egy kifejezés kitevőjébe írjuk, akkor indikátorváltozóként (indicator variable) viselkedik: pTakkor p, ha T = 1, egyébként 1; hasonlóképpen (1 – p)(1–T) akkor (1 – p), ha T = 0, különben 1. Ezek szerint az adat log likelihood értékét felírhatjuk, mint:
L = log pT(1 – p)(1 – T) = T log p + (1 – T) log(1 – p) (20.13)
A szigmoid függvény tulajdonságainak hála, a gradiens rendkívül egyszerű formára hozható (20.16. feladat):
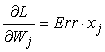
Fontos
Vegyük észre, hogy szigmoid perceptronok esetén a maximum-likelihood tanulás súlyfrissítési vektorát megadó egyenlete alapvetően azonos a négyzetes hiba minimalizálásán alapuló frissítés vektorával. Tehát azt mondhatjuk, hogy a perceptronnak még akkor is van valószínűségi interpretációja, ha a tanulási szabályt determinisztikus megközelítéssel származtattuk.
Vizsgáljuk most a rejtett neuronokkal rendelkező hálókat. A legelterjedtebb esetben egy rejtett réteget[205] szoktak használni, ezt mutatja 20.24. ábra. A rejtett réteg hozzáadásának az az előnye, hogy kiterjeszti a háló által reprezentálható hipotézisek terét. Gondoljunk minden egyes rejtett neuronra úgy, mint ami egy lágy küszöbfüggvényt reprezentál a bemeneti térben – lásd a 20.19. (b) ábrát. Ezek után gondoljunk úgy egy kimeneti neuronra, mint ami számos ilyen függvény lineáris kombinációjának lágy küszöbfüggvénye. Például összeadva két – egymással szemben álló – lágy küszöbfüggvényt, és küszöbözve az eredményt, a 20.23. (a) ábrán látható „hegygerinc” függvényt kapjuk. Egymásra derékszögben álló két ilyen hegygerinc kombinálásával (tehát 4 rejtett neuron kimenetének kombinálásával) a 20.23. (b) ábrán látható „dudort” kapjuk.
Több rejtett neuronnal különböző helyeken több, eltérő méretű dudort tudunk létrehozni. Valójában egyetlen, megfelelően nagy rejtett réteggel a bemenetek tetszőleges folytonos függvénye tetszőleges pontossággal reprezentálható, sőt két réteggel még nemfolytonos függvények is reprezentálhatók.[206] Sajnos egy egyedi neurális struktúra esetén nemigen lehet megmondani, hogy milyen függvények reprezentálhatók, és milyenek nem.
Tegyük fel, hogy az étterem problémára akarunk konstruálni egy egy-rejtett-réteggel rendelkező hálót. Minden példát 10 attribútum ír le, tehát egy 10 bemenetű hálóra lesz szükség. Hány rejtett neuron kell? A 20.24. ábrán bemutatunk egy négy rejtett neuronnal felépített hálót. Az derült ki, hogy ez nagyjából megfelelő ehhez a problémához. A rejtett neuronok számának előzetes meghatározása még napjainkban sem jól megoldott probléma. (Lásd 20.5.5. szakasz - Neurális hálóstruktúrák tanulása részben.)
20.23. ábra - (a) Két – egymással szemben álló – lágy küszöbfüggvény kombinációjának eredménye: egy hegygerinc. (b) Két hegygerinc kombinációjának eredménye a dudor.

A többrétegű háló tanuló algoritmusa hasonló a 20.21. ábrán bemutatott perceptrontanulási algoritmushoz. Egy kisebb különbség, hogy több kimenet is lehet, így nem egy skalár kimeneti értékünk, hanem egy hW(x) kimeneti vektorunk van, és minden egyes példához is egy y kívánt kimeneti vektor tartozik. Fontosabb különbség, hogy míg a kimeneti rétegben a hiba nyilvánvalóan y – hW, addig a rejtett rétegben a hiba misztikusnak tűnik, hiszen a tanító minták nem mutatják, hogy mimnek kellene lennie a rejtett csomópontok értékének. Kiderül, hogy a hibát viszszaterjeszthetjük (back-propagate) a kimeneti rétegről a rejtett rétegekre. A hiba-visszaterjesztési eljárás (back-propagation) közvetlenül kiadódik a teljes hibagradiens levezetéséből. Először egy intuitív bizonyítással mutatjuk be az eljárást, majd megmutatjuk a levezetést is.
20.24. ábra - Többrétegű neurális háló egy rejtett réteggel és 10 bemeneti egységgel, alkalmas az étterem problémához
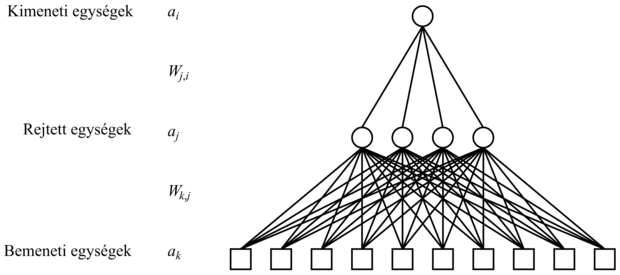
A kimeneti rétegre a súlyfrissítési szabály azonos a (20.12) egyenlettel. Több kimenetünk van, legyen Erri az y – hW hibavektor i-edik komponense. Hasznos lesz, ha bevezetjük a módosított hibát, Δi = Erri × g'(ini)-t, így a súlyfrissítési szabály:
Wj,i ← Wj,i + α × aj · Δi (20.14)
Ahhoz, hogy a bemeneti neuronok és a rejtett neuronok közti összeköttetések frissítését megoldjuk, a kimeneti csomópontok hibájához hasonló mennyiséget kell definiálnunk. Ez az a pont, ahol a hiba-visszaterjesztést végezzük. A gondolat az, hogy a j rejtett csomópont valamilyen arányban „felelős” minden egyes – vele összeköttetésben lévő – kimeneti csomópont Δi hibájáért. Így a Δi értékeket a rejtett csomópont és a kimeneti csomópont közötti összeköttetés erőssége alapján osztjuk és visszaterjesztjük, hogy megkapjuk a rejtett réteg Δj értékeit. A Δ értékek terjesztési szabálya a következő:

Ezek után a bemenetek és a rejtett réteg közötti súlyok frissítési szabálya szinte azonos a kimeneti réteg frissítési szabályával:
Wk,j ← Wk,j + α × ak × Δj
A hiba-visszaterjesztési algoritmus a következő módon foglalható össze:
-
Számítsuk ki a kimeneti neuronokra a Δ értékeket a megfigyelt hiba alapján.
-
A kimeneti réteggel kezdve ismételjük a következő lépéseket minden rétegre, amíg a legelső rejtett réteget el nem érjük:
-
Terjesszük vissza a Δ értékeket a megelőző rétegre.
-
Frissítsük a két réteg közötti súlyokat.
-
Az algoritmust a 20.25. ábra mutatja be részleteiben.

A matematika iránt vonzalmat érzők kedvéért most az alapegyenletekből levezetjük a hiba-visszaterjesztési algoritmust. Egyetlen mintára a négyzetes hiba definíciója:
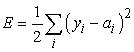
ahol az összegzés a kimeneti réteg csomópontjaira vonatkozik. Egy bizonyos Wj,i súlyra vett gradiens kiszámításához csak az ai aktivációt kell deriválnunk, mivel az összeg összes többi tagja független Wj,i-től:
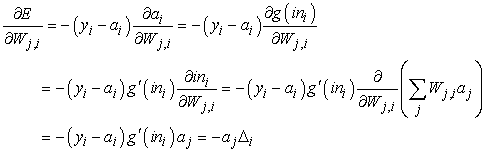
ahol Δi-t az előzőkkel megegyezően definiáltuk. Ahhoz, hogy a bemeneti réteget és a rejtett réteget összekötő Wk,j súlyokra vonatkozó gradienst megkapjuk, meg kell tartanunk az i feletti teljes összegzést, hiszen az összes kimeneti ai értékre hatással lehetnek Wk,j változásai. Az aj aktivációkat szintén mind ki kell fejtenünk. Aprólékosan bemutatjuk a levezetést, mivel érdekes megfigyelni, ahogy a differenciáló operátor visszaterjed hálón keresztül:
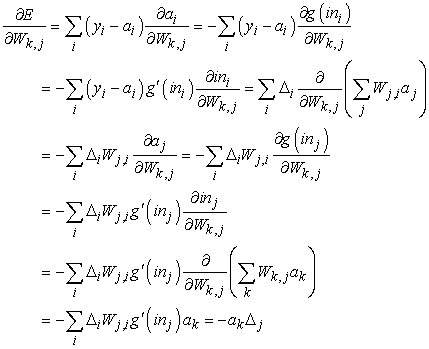
ahol a Δj-t az előzőkkel megegyezően definiáltuk. Tehát megkaptuk azt a frissítési szabályt, amelyet már korábban megkaptunk intuitív úton is. Az is nyilvánvaló, hogy az eljárás folytatható több mint egy rejtett rétegű hálókra is, ami igazolja a 20.25. ábrán bemutatott általános algoritmust.
Keresztülverekedvén magunkat (vagy átugorva) a matematikai levezetésen lássuk most, hogy milyen teljesítményt nyújt egy egy-rejtett-rétegű háló az étterem problémán. A 20.26. ábrán két görbét mutatunk be. Az első a tanítási görbe (training curve), amely a súlyfrissítés során az átlagos négyzetes hiba alakulását mutatja egy adott 100 elemű étterem példahalmazon mérve. Ez jól demonstrálja, hogy a háló valóban konvergál a tanító mintákra való tökéletes illeszkedéshez. A második görbe az étteremadatok standard tanulási görbéje. A neurális háló jól tanul, bár nem annyira gyorsan, mint a döntési fa tanulás. Ez talán nem meglepő, hiszen az adatokat egy egyszerű döntési fával generáltuk.
20.26. ábra - (a) Az étterem probléma egy adott példahalmazán felvett tanulási görbe, ami a súlyok számos epoch során történő módosításával elért fokozatos hibacsökkenést mutatja. (b) Összehasonlító tanulási görbék, amelyek azt mutatják, hogy a döntési fa tanulás valamivel jobb teljesítményt ad, mint a többrétegű háló hiba-visszaterjesztéses tanulása.

A neurális hálók természetesen messze bonyolultabb tanulási feladatokra képesek, bár meg kell jegyeznünk, hogy szükség van némi babrálásra ahhoz, hogy megfelelő hálóstruktúrát kapjunk, és a súlytérben valahol a globális optimum közelébe konvergáljunk. A szó szoros értelmében tízezerszám vannak publikált neurális háló alkalmazások. A 20.7. alfejezet alaposabban bemutat egyet.
Az eddigiekben adott hálóstruktúra mellett történő súlytanulással foglalkoztunk. A Bayes-hálókhoz hasonlóan azt is meg kell értenünk, hogy hogyan találhatjuk meg a legjobb hálóstruktúrát. Ha túl nagy hálót használunk, akkor az egy nagy táblázatot kialakítva képes lesz memorizálni az összes példát, de nem feltétlenül lesz képes olyan bemenetekre jól általánosítani, amelyeket nem látott korábban.[207] Más szavakkal a neurális háló – éppúgy, mint az összes statisztikus modell – hajlamos a túlilleszkedésre (overfitting), ha túl sok modellparaméter van. Ezt bemutattuk a 18.1. ábrán (18.2. szakasz - Induktív tanulás rész), ahol a (b) és (c) sokparaméteres modell jól illeszkedett az adatokra, de nem volt képes olyan jó általánosításra, mint a kevés paraméterrel rendelkező (a) és (d) modellek.
Ha ragaszkodunk a teljesen összekötött hálókhoz, akkor egyedül a rejtett rétegek számára és méretére korlátozódnak a választási lehetőségeink. A szokásos megközelítés, hogy sok struktúrát kipróbálunk, és megtartjuk a legjobbat. A 18. fejezetben ismertetett keresztvalidációs (cross-validation) technikára van szükségünk, ha el akarjuk kerülni a teszthalmazra való kukucskálást (peeking). Azaz azt a hálóarchitektúrát választjuk, amely a validációs halmazon a legnagyobb jóslási pontosságot adja.
Ha figyelembe akarunk venni nem teljesen összekötött hálókat is, akkor szükségünk van egy hatékony módszerre, amely a lehetséges összeköttetési topológiák nagyon nagy terében keres. Az optimális agykárosodás (optimal brain damage) módszere egy teljesen összekötött hálóból indul ki, és összeköttetéseket távolít el belőle. Miután a hálót első menetben tanítottuk, egy információelméleti megközelítés segítségével meghatározzuk az eltávolítható összeköttetések optimális készletét. A hálót ezek után újratanítjuk, és ha teljesítménye nem csökkent, az eljárást megismételjük. Az összeköttetések eltávolításán felül olyan neuronokat is eltávolíthatunk, amelyek nem sokkal járulnak hozzá a megoldáshoz.
Rengeteg algoritmust javasoltak arra, hogy egy kisebb hálóból nagyobbat növesszenek. Egyikük, a csempézés (tiling), a döntési fa tanulásra emlékeztet. Az ötlet az, hogy kezdjünk egyetlen neuronnal, amely a legjobbját nyújtja, hogy annyi tanító mintára adjon helyes választ, ahányra csak lehet. További neuronokat adunk hozzá, hogy megoldjuk azokat a példákat, amelyekre az első neuron rossz választ adott. Az algoritmus csak annyi neuront ad hozzá, amennyi az összes minta megoldásához szükséges.
[202] A folytonos terekben használható általános optimalizálási technikákat lásd a 4.4. alfejezetben.
[203] Szigmoid függvény esetén ez a derivált g' = g(1 – g).
[204] Küszöbperceptronokra, ahol g'(in) nem definiált, a Rosenblatt (Rosenblatt, 1957) által kidolgozott eredeti perceptron tanulási szabály (perceptron learning rule) megegyezik a (20.12) egyenlettel, leszámítva, hogy a g'(in) kimarad. Mivel g'(in) minden súlyra azonos, elhagyása az egyes mintáknál összességében csak a súlyfrissítés nagyságát változtatja meg, az irányát nem.
[205] Egyesek ezt háromrétegű hálózatnak nevezik, mások kétrétegűnek (mivel a bemenetek nem „igazi” neuronok). A zűrzavar elkerülése érdekében mi „egy-rejtett-rétegű háló”-nak nevezzük.
[206] A bizonyítás bonyolult, de legfőbb pontja az, hogy a bemenetek számával exponenciálisan nő a szükséges rejtett neuronok száma. Például n bemenetű logikai függvények kódolására 2n/n rejtett neuron kell.
[207] Azt figyelték meg, hogy a nagyon nagy hálók mindaddig jól általánosítanak, amíg a súlyaikat kis értéken tartjuk. Ez a megszorítás az aktivációs értékeket a g(x) szigmoid függvény lineáris tartományában tartja, ahol x közel nulla. Ez viszont azt jelenti, hogy a háló úgy viselkedik, mint egy sokkal kevesebb paraméterrel rendelkező lineáris függvény (lásd 20.17. feladat).
