20.2. Teljes adattal történő tanulás
A statisztikai tanulási módszerek tárgyalását a legegyszerűbb feladattal kezdjük: paramétertanulás (parameter learning) teljes adat (complete data) alapján. A paramétertanulás egy rögzített struktúrájú valószínűségi modell paramétereinek megtalálását foglalja magában. Például meg akarjuk tanulni egy adott struktúrájú Bayes-háló feltételes valószínűségeit. Az adatokat akkor nevezzük teljesnek, ha mindegyik adatpont értékeket hordoz a megtanulandó valószínűségi modell mindegyik paraméterére. A teljes adatok nagyban egyszerűsítik a komplex modellek paramétereinek tanulását. Nagy vonalakban áttekintjük majd a struktúratanulás problematikáját is.
Tegyük fel, hogy új gyártótól vásárolunk egy zsák citrom- és meggycukorkát, a meggyarány teljesen ismeretlen, bárhol lehet 0 és 1 között. Ez esetben kontinuum számosságú hipotézisünk van. A paraméter (parameter), amelyet θ-val jelölünk, most a meggycukorkák aránya, a hipotézis pedig hθ. (A citromízűek aránya egyszerűen 1 – θ.) Ha feltételezzük, hogy a priori minden arány egyformán valószínű, akkor a maximum-likelihood megközelítés az ésszerű. Ha Bayes-hálóval modellezzük a helyzetet, akkor csupán egyetlen véletlen változóra van szükségünk. Legyen ez az Íz nevű változó (a zacskóból véletlenszerűen választott cukorka íze). Lehetséges értékei a meggy és a citrom, ahol a meggy valószínűsége θ (lásd 20.2. (a) ábra). Tegyük fel, hogy kibontunk N cukorkát, amelyek közül c meggyízű és ℓ = N – c citromízű. A (20.3) egyenlet alapján ennek a speciális adathalmaznak a valószínűsége:
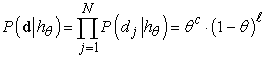
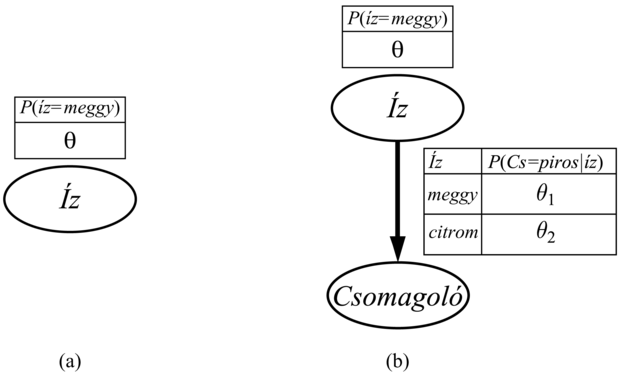
20.2. ábra - (a) Bayes-háló modell az ismeretlen arányban citrom-, illetve meggyízű cukorkák esetére. (b) Annak a modellje, amikor a csomagolópapír színe függ (valószínűségi alapon) a cukorka ízétől.
A maximum-likelihood hipotézist az a θ érték adja, amely maximálja ezt a kifejezést. Ugyanezt az értéket kapjuk, ha a log likelihood függvényt maximáljuk.
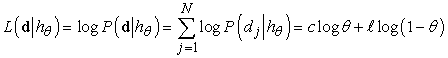
(A kifejezés logaritmusát képezve a szorzatot szummává redukáltuk, amit rendszerint egyszerűbb maximálni.) A maximum-likelihood θ érték megtalálása érdekében differenciáljuk L-et θ szerint, a kapott kifejezést pedig tegyük egyenlővé nullával:
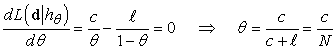
Magyarán a hML maximum-likelihood hipotézis azt állítja, hogy a zacskóban a meggyízű cukorkák valós aránya megegyezik az eddig kibontott cukorkáknál megfigyelt aránnyal!
Úgy tűnik, rengeteget dolgoztunk, hogy felfedezzünk egy nyilvánvaló eredményt. Valójában lefektettünk egy standard módszert a maximum-likelihood paramétertanulásra:
-
Írjunk fel egy – a paraméter(ek)től függő – kifejezést az adatok együttes valószínűségére (írjuk fel a likelihood függvényt).
-
Írjuk fel minden egyes paraméter szerint a log likelihood függvény deriváltját.
-
Keressük meg azokat a paraméterértékeket, amelyek mellett a deriváltak nulla értéket vesznek fel.
Fontos
A legtrükkösebb lépés általában az utolsó. Az előző példánkban triviálisan megoldható volt, de látni fogjuk, hogy sokszor iteratív megoldásokhoz vagy más numerikus optimalizálási technikákhoz kell folyamodnunk, mint ahogy a 4. fejezetben tárgyaltuk. A példa a maximum-likelihood tanulás egy általános problémáját is illusztrálja: ha az adathalmaz elég kicsi ahhoz, hogy néhány eseményt még nem figyeltünk meg – például nem találtunk még meggyízű cukorkát –, akkor a maximum-likelihood hipotézis nulla valószínűséget rendel ezekhez az eseményekhez. Számos trükköt használnak, hogy elkerüljék ezt a problémát, mint például minden esemény kezdeti valószínűségét 1-re állítják nulla helyett.
Nézzünk egy másik példát. Tegyük fel, hogy a cukorka gyártója némi információt akar adni a fogyasztónak, ezért piros és zöld csomagolópapírt használ. A Csomagoló mindegyik cukorkához véletlenszerűen kerül kiválasztásra, valamilyen ismeretlen – az íztől függő – feltételes valószínűség-eloszlás szerint. Az ehhez tartozó valószínűségi modellt a 20.2. (b) ábra mutatja. Vegyük észre, hogy három paramétere van: θ, θ1 és θ2. Ezekkel a parméterekkel a Bayes-hálók standard szemantikáját használva megadható annak a valószínűsége, hogy – mondjuk – egy meggyízű cukorkát találunk egy zöld csomagolóban (14.2.1. szakasz - Az együttes valószínűség-eloszlás függvény leírása rész):
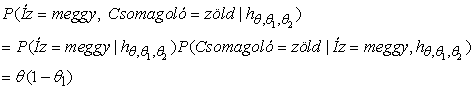
Most kibontunk N cukorkát, amelyek közül c meggyízű és ℓ citromízű. A csomagolásfajták számai a következők: rc meggyízű volt pirosba csomagolva és gc zöldbe, míg rℓ citromízű volt pirosba csomagolva, míg gℓ zöldbe. Ezen adatok együttes valószínűsége:
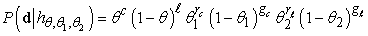
Ez meglehetősen ijesztőnek tűnik, de segít, ha a logaritmusát vesszük:
L = [clogθ + ℓlog(1 – θ)] + [rc logθ1 + gc log(1 – θ1)] + [rℓ logθ2 + gℓ log(1 – θ2)]
A logaritmusképzés előnye nyilvánvaló: a log likelihood függvény három tag összege, ahol mindegyik tag csupán egyetlen paramétert tartalmaz. Amikor sorban mindegyik paraméter szerint vesszük az összefüggés deriváltját, majd nullává tesszük a deriváltakat, három független egyenlethez jutunk, és mindegyik csupán egyetlen paramétert tartalmaz:
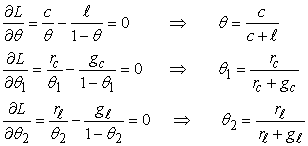
A θ-ra kapott megoldás ugyanaz, mint az előbb. A θ1-re kapott megoldás, tehát annak valószínűsége, hogy egy meggyízű cukorka piros papírba csomagolt, nem más, mint a megfigyelt meggyízű cukorka – piros papír arány, hasonló a helyzet θ2-vel.
Fontos
Ezek az eredmények nagyon kényelmesek, és könnyen belátható, hogy kiterjeszthetők bármely Bayes-hálóra, amelynek feltételes valószínűségeit táblázatokkal adjuk meg. A legfontosabb eredmény a következő: teljes adatok esetén a Bayes-háló paramétertanulási problémája elkülönülő tanulási problémákra dekomponálható, egy-egy probléma egy-egy paraméterre.[196] A második eredmény, hogy az egyes paraméterek adott szülő melletti értékei éppen a szülőértékek mellett megfigyelt gyakoriságokkal egyeznek meg. Éppúgy, mint az előző helyzetben, itt is óvatosnak kell lennünk, hogy kis adathalmazok esetén el tudjuk kerülni a nulla értékeket.
Valószínűleg a gépi tanulás területén használt legelterjedtebb Bayes-háló modell a naiv Bayes-modell (naive Bayes). Ebben a modellben a C „osztályváltozó” (amelyet meg akarunk jósolni) a gyökér, míg az Xi attribútumváltozók a levelek. A modell azért „naiv”, mert feltételezi, hogy adott osztály mellett az attribútumok feltételesen függetlenek egymástól. (A 20.2. (b) ábra modellje egy egyváltozós naiv Bayes-modell.) Logikai változókat feltételezve a paraméterek:
θ = P(C = igaz), θi1 =P(Xi = igaz|C = igaz), θi2 = P(Xi = igaz|C = hamis)
A maximum-likelihood paramétereket pontosan úgy kapjuk meg, mint a 20.2. (b) ábra esetén. Ha a modellt ezen az úton megtanítottuk, akkor felhasználható arra, hogy olyan új példákat osztályozzon, amelyekre a C osztályváltozó nem ismert. A megfigyelt x1, ..., xn attribútumértékek mellett az egyes osztályok valószínűségét a következő összefüggés adja:
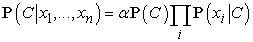
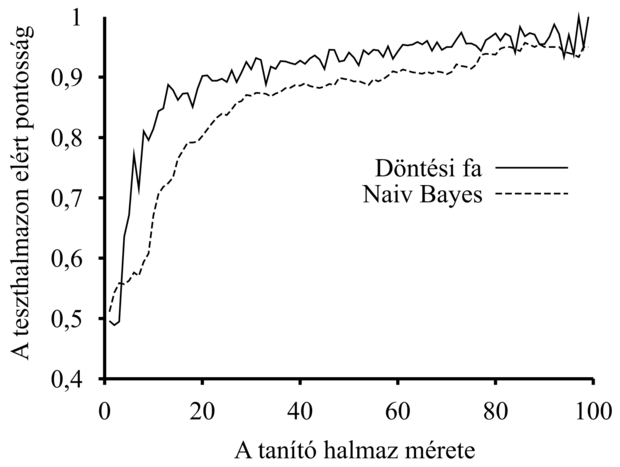
20.3. ábra - A 18. fejezet étterem problémájára alkalmazott naiv Bayes-tanulás tanulási görbéje. A döntési fa tanulás tanulási görbéjét összehasonlítás céljából ábrázoltuk.
Fontos
Ha a legvalószínűbb osztályt választjuk, determinisztikus predikció adható. A 20.3. ábra mutatja a módszer tanulási görbéjét, ha a 18. fejezet étterem problémájára alkalmazzuk. A módszer elég jól tanul, de nem olyan jól, mint egy döntési fa tanulás. Ennek oka valószínűleg az, hogy a helyes hipotézis – ami egy döntési fa – nem reprezentálható pontosan naiv Bayes-modellel. A naiv Bayes-tanulás sok alkalmazási területen meglepően jól teljesít, a fokozott teljesítményű, turbó változata (boosted version) egyike a leghatékonyabb általános célú tanuló algoritmusoknak (lásd 20.5. feladat). A módszer nagyon nagy méretű problémákhoz is jól alkalmazható, n logikai változó esetén is csak 2n + 1 paramétere lesz, és ahhoz, hogy a naiv Bayes-tanulás meghatározza hML-t, nincs szükség keresésre. Végül a naiv Bayes-tanulásnak nem jelentenek gondot a zajos adatok, továbbá ha szükséges, akkor képes valószínűségi predikciókat is adni.
A 14.3. alfejezetben vezettük be a folytonos valószínűségi modelleket, mint például a lineáris Gauss- (linear-Gaussian) modelleket. Mivel a valós alkalmazásokban mindenütt folytonos változókkal találkozunk, fontos ismernünk a folytonos modellek adatokból történő megtanulásának módszereit. A maximum-likelihood tanulás elvei azonosak a diszkrét esetre vonatkozó tanulás elveivel.
Kezdjük egy rendkívül egyszerű esettel: egyetlen skalár változó Gauss-sűrűségfüggvényének a paramétereit tanuljuk. Azaz az adatokat a következő összefüggéssel generáljuk:
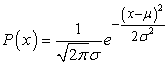
A modell paraméterei a μ átlag és a σ szórás. (Vegyük észre, hogy a normalizáló konstans is függ σ -tól, ezért nem hanyagolhatjuk el.) Legyenek a megfigyelt értékek x1,..., xN. Ekkor a log likelihood:
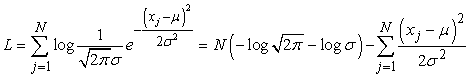
A deriváltakat szokásos módon nullává téve a következőket kapjuk:
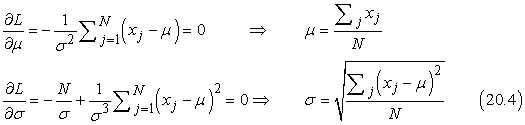
Tehát az átlag maximum-likelihood becslése a mintaátlag, a szórás maximum-likelihood becslése pedig a minta átlagos szórásnégyzetének négyzetgyöke. Ezek ismét kedvező eredmények, mivel megerősítik a „józan ésszel” követett gyakorlatot.
Vizsgáljunk most egy lineáris Gauss-modellt, amelyben egy X folytonos szülő és Y folytonos gyermek van. Mint az 14.3.1. szakasz - Bayes-hálók folytonos változókkal részben megmutattuk, Y Gauss-eloszlású, átlaga lineárisan függ X-től, míg varianciája rögzített. A P(X|Y) feltételes eloszlás tanulásához maximalizálhatjuk a feltételes likelihood függvényt:

20.4. ábra - (a) Egy y = (θ1 + θj + θ2) egyenlettel leírható lineáris Gauss-modell additív, rögzített varianciájú Gauss-zajjal. (b) E modell alapján generált 50 adatpontból álló halmaz.
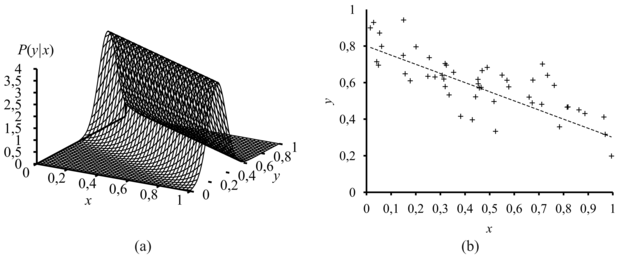
Itt a paraméterek θ1, θ2 és σ. Mint a 20.4. ábrán szemléltettük, az (xj, yj) párok gyűjteménye adja az adatokat. A szokásos módszereket használva (lásd 20.6. feladat) megkaphatjuk a paraméterek maximum-likelihood értékeit. Itt most egy másik dolgot akarunk megmutatni. Vegyük csupán a θ1 és θ2 paramétereket, amelyek az x és y közti lineáris összefüggést definiálják! Nyilvánvaló, hogy a log likelihood ezen paraméterekkel történő maximalizálása azonos azzal, mintha a (20.5) kifejezésben a kitevő számlálóját minimalizálnánk:
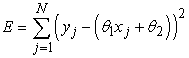
Az (yj – (θ1xj + θ2)) mennyiség valójában az (xj, yj) hibája (error) – azaz a tényleges yj érték és a becsült érték különbsége. Így E nem más, mint a jól ismert hibanégyzetek összege (sum of squared errors). Ezt a standard lineáris regresszió (linear regression) minimalizálja. Most megérthetjük, hogy miért: a hibanégyzetek összegének minimalizálása nem más, mint a maximum-likelihood lineáris (egyenessel ábrázolható) modell megadása, feltéve, hogy az adatokat rögzített varianciájú Gauss-zaj mellett generáltuk.
A maximum-likelihood tanulás alkalmat ad néhány nagyon egyszerű eljárás létrehozására, de kis adathalmazok esetén súlyos hiányosságokat mutat. Például egyetlen meggyízű cukorka észlelése után az a maximum-likelihood hipotézis, hogy a csomag 100%-a meggytípusú (azaz θ = 1,0). Ha nincs olyan hipotézis prior, hogy a csomagok mind vagy csupa meggy-, vagy csupa citromtípusúak, akkor ez nem józan következtetés. A Bayes-megközelítésű paramétertanulás egy hipotézis priort állít fel a lehetséges paraméterértékekre, és ahogy az adatok érkeznek, úgy frissíti az eloszlást.
A 20.2. (a) cukorka példának egyetlen θ paramétere van; annak valószínűsége, hogy egy véletlenszerűen kiválasztott cukorka meggyízű. Bayes-megközelítésben θ a Θ valószínűségi változó (ismeretlen) értéke, a hipotézis prior pedig nem más, mint a P(Θ) a priori eloszlás. Így P(Θ = θ) annak a priori valószínűsége, hogy a csomag θ arányban tartalmaz meggyízű cukrokat.
![Példák a béta[a,b] eloszlásra különböző [a,b] értékek esetén](/mi_almanach/sites/default/files/books/35/files/kepek/20-05.png)
Ha a θ tetszőleges értéket felvehet 0 és 1 között, akkor a P(Θ)-nek egy folytonos eloszlásnak kell lennie, amely csak 0 és 1 között nem nulla értékű, és integrálja 1. Egy lehetséges jelölt az egyenletes eloszlás P(θ) = U[0, 1] (θ). (Lásd 13. fejezet.) Az egyenletes eloszlás a béta-eloszlások (beta distributions) családjának tagja. Minden egyes béta-eloszlás két hiperparaméterrel[197] (hyperparameter) – a-val és b-vel – definiálható a következő egyenlet szerint:
béta[a,b] (θ) = αθa–1 (1–θ)b–1 (20.6)
A (20.6) megadja θ-ra a [0, 1] tartományban a sűrűségfüggvény értékét. Az α normáló konstans a-tól és b-től függ. (Lásd 20.8. feladat.) A 20.5. ábrán bemutatjuk, hogy hogyan néz ki az eloszlás különböző a-k és b-k esetén. Az eloszlás átlaga a/(a + b), tehát nagyobb a értékek arra utalnak, hogy Θ-t 1-hez közelebb hisszük, mint 0-hoz. Az a + b nagyobb értékei az eloszlást csúcsosabbá teszik, ami a Θ értéke felőli nagyobb bizonyosságunkat jelenti. Látható, hogy a béta-család a hipotézis prior lehetőségek hasznos választékát nyújtja.
Rugalmasságán túl a béta-családnak van még egy csodálatos tulajdonsága: ha a Θ priorja béta[a, b], akkor egy adatpont megfigyelése után Θ a posteriori eloszlása is béta-eloszlás. A béta-családot a logikai változók eloszlása konjugált priorjának (conjugate prior) nevezzük.[198] Lássuk, hogyan is működik ez. Tegyük fel, hogy megfigyeltünk egy meggyízű cukrot, ekkor:
P(θ|D1 = meggy) = αP(D1 = meggy|θ)P(θ)
= α'θ · beta[a,b](θ) = α'θ · θa–1(1– θ)b–1
= α'θa (1– θ)b–1 = beta[a + 1,b](θ)
Tehát egy meggyízű cukrot észlelve egyszerűen inkrementáljuk az a paramétert, hasonlóképpen, ha egy citromízűt észlelünk, akkor inkrementáljuk a b paramétert – ezzel megkapjuk az a posteriori eloszlást. Ezek szerint úgy tekinthetünk a-ra és b-re, mint virtuális számlálókra (virtual counts), abban az értelemben, hogy a béta[a, b] prior pontosan úgy viselkedik, mintha egyenletes eloszlású priorral indultunk volna, és a – 1 meggycukorkát és b – 1 citromízű cukorkát láttunk volna.
Tanulmányozva a béta-eloszlások sorozatát növekvő – de állandó arányú – a és b mentén, jól láthatjuk, hogyan változik a Θ paraméter a posteriori eloszlása az adatok beérkezése során. Tegyük fel például, hogy a vizsgált zacskó 75%-a meggytípusú. A 20.5. (b) ábra mutatja a béta[3, 1], béta[6, 2], béta[30, 10] eloszlássorozatot. Nyilvánvaló, hogy az eloszlás egy – a valós Θ körül elhelyezkedő – keskeny csúcs felé tart. Nagy adathalmazok esetén a Bayes-tanulás (legalábbis ebben az esetben) ugyanahhoz az eredményhez konvergál, mint amit a maximum-likelihood tanulás adott.
A 20.2. (b) ábrán a hálónak három paramétere volt: θ, θ1 és θ2, ahol θ1 volt annak valószínűsége, hogy piros csomagolás van egy meggycukorkán, míg θ2 az, hogy egy citromízű cukron van piros csomagolás. A Bayes hipotézis priornak mindhárom paramétert le kell fednie – azaz P(Θ, Θ1, Θ2)-t kell specifikálnunk. Rendszerint paraméterfüggetlenséget (parameter independence) tételezünk fel:
P(Θ, Θ1, Θ2) = P(Θ)P(Θ1)P(Θ2)
Ezen feltételezés esetén minden egyes paraméternek saját béta-eloszlása lehet, amelyet külön-külön frissíthetünk az adatok érkeztekor.
20.6. ábra - Egy Bayes-tanulásnak megfelelő Bayes-háló. A Θ, Θ1, Θ2 változók a posteriori eloszlásai kikövetkeztethetők az a priori eloszlásokból és az Ízi, Csomagolói változókra vonatkozó tényekből.
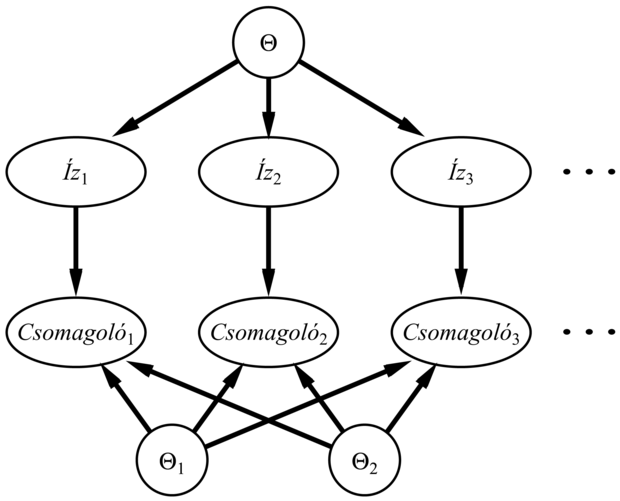
Ha már az volt az ötletünk, hogy az ismeretlen paramétereket valószínűségi változókkal reprezentáljuk – amilyen például Θ –, akkor természetes módon adódik, hogy azokat beépítsük magába a Bayes-hálóba. Ahhoz, hogy ezt megtehessük, minden egyes példa leírásához másolatot kell készítenünk a változókról. Ha például három cukorkát figyeltünk meg, akkor szükségünk van a következő változókra: Íz1, Íz2, Íz3 és Csomagoló1, Csomagoló2, Csomagoló3. A Θ paraméterváltozó határozza meg minden egyes Ízi változó valószínűségét:
P(Ízi = meggy|Θ = θ) = θ
Hasonlóképpen a csomagoló valószínűsége Θ1-től és Θ2-től függ. Például:
P(Csomagolói = piros|Ízi = meggy, Θ1 = θ1) = θ1
Fontos
Ezek után az egész Bayes-tanulási folyamat formalizálható egy megfelelően konstruált Bayes-háló következtetési problémájaként, amint a 20.6. ábrán látható. Egy új példány predikciója egyszerűen azt jelenti, hogy új példányváltozókat adunk a hálóhoz, amelyből egyesekre rákérdezünk. A tanulás és a predikció ezen formalizmusa nyilvánvalóvá teszi, hogy a Bayes-tanuláshoz nem kell semmilyen extra „tanulási elv”. Megállapíthatjuk továbbá, hogy lényegében csak egyetlen tanulási algoritmus van, ami a Bayes-háló következtetési algoritmusa.
Az eddigiekben azt feltételeztük, hogy a Bayes-háló struktúrája ismert, és csak a paramétereket próbáljuk megtanulni. A háló struktúrája a terület alapvető oksági viszonyaira vonatkozó tudást reprezentálja, amit sok esetben egy szakember, de még egy naiv felhasználó is, nagyon egyszerűen meg tud adni. Néhány esetben azonban az oksági összefüggések nem állnak rendelkezésre vagy vitatottak – például bizonyos nagyvállalatok régóta állítják, hogy a dohányzás nem okoz rákot. Ilyenkor fontos megérteni, hogy a Bayes-háló struktúrája mi módon tanulható meg az adatokból. Jelenleg a struktúratanulási algoritmusok gyerekcipőben járnak, ezért csak egy elnagyolt vázlatot adunk a legfontosabb elvekről.
A legkézenfekvőbb megközelítés, ha egy jó modell érdekében keresést folytatunk. Elindulhatunk egy kapcsolatokat nem tartalmazó modellel, majd elkezdünk szülőcsomópontot adni minden csomóponthoz, az előbbiekben bemutatott módszerekkel illesztve a paramétereket, és mérjük a modell pontosságát. Másik lehetőség, hogy egy becsült struktúrával indulunk, és hegymászó vagy szimulált lehűtést alkalmazó algoritmusokat használunk a módosításokhoz, minden egyes struktúraváltoztatás után újrahangolva a paramétereket. A módosítások közé tartozik az élek megfordítása, hozzáadása, törlése. Nem szabad ciklusokat létrehoznunk a folyamat során, ezért sok algoritmus azt feltételezi, hogy adott a változók egy rendezése, és egy csomópont szülője csak azon csomópontok közül kerülhet ki, amelyek előbb jönnek a rendezésben (éppúgy, mint a 14. fejezet konstrukciós eljárásában). A teljes általánosság kedvéért a lehetséges rendezések között is keresnünk kell.
Két alternatív módszer van arra, hogy észrevegyük, amikor egy jó megoldást találtunk. Az első annak tesztelése, hogy az aktuális adatok kielégítik-e azokat a feltételes függetlenségre vonatkozó állításokat, amelyek a struktúrában implicit módon benne vannak. Például az étterem probléma egy naiv Bayes-modellje feltételezi, hogy:
P(Péntek/Szombat, Bár|VárjunkE) P(Péntek/Szombat|VárjunkE)P(Bár|VárjunkE)
és leellenőrizhetjük az adatokon, hogy ugyanez az egyenlet fennáll-e a megfelelő feltételes gyakoriságok közt is. Viszont még akkor is, ha a struktúra a terület valós oksági természetét írja le, az adathalmaz – a statisztikai ingadozások miatt – az egyenletet soha nem elégíti ki pontosan. Ezért megfelelő statisztikai próbákat kell elvégeznünk, hogy eldöntsük: elég bizonyítékunk van-e arra, hogy a függetlenségi hipotézisek sérülnek. Az eredményül kapott háló bonyolultsága az ezen tesztekben alkalmazott küszöbtől függ majd – minél szigorúbb a függetlenségi teszt, annál több kapcsolatot adunk majd a struktúrához, és annál nagyobb lesz a túlilleszkedés veszélye.
A jelen fejezetben bemutatott gondolatoknak jobban megfelelő megközelítés annak értékelése, hogy a javasolt modell mennyire magyarázza meg az adatokat (valószínűségi értelemben). Mindamellett óvatosnak kell lennünk ennek mérésénél. Ha egyszerűen a maximum-likelihood hipotézist akarjuk megtalálni, akkor egy teljesen összekötött hálónál fogunk kikötni, mivel további szülőcsomópontok hozzáadása egy csomóponthoz nem csökkentheti a valószínűséget (lásd 20.9. feladat). Valamilyen módon büntetnünk kell a modell bonyolultságát. A MAP (vagy MLH) megközelítés egyszerűen levon egy büntetőtagot az egyes struktúrák valószínűségéből (miután hangolta paramétereiket), ezek után hasonlítja össze a különböző struktúrákat. A Bayes-megközelítés a struktúrák és paraméterek együttes priorját használja. Rendszerint túl sok – a változók számán szuperexponenciális – struktúra van ahhoz, hogy mind felett összegezzünk, így a gyakorlatban legtöbben az MCMC (Markov lánc Monte Carlo) módszert használják, hogy mintát vegyenek a struktúrákból.
A bonyolultság büntetése (akár MAP, akár Bayes-megközelítésben) fontos kapcsolatot hoz be az optimális struktúra és a feltételes valószínűségek hálóbeli reprezentációs módja között. Táblázatosan ábrázolt eloszlás esetén a bonyolultság büntetése a szülőcsomópontok számával exponenciálisan nő, míg, mondjuk, zajos-vagy eloszlások esetén csak lineárisan. Ez azt jelenti, hogy a zajos-vagy (illetve más tömören paraméterezett) modellek tanulása több szülőcsomópontot eredményez, mint a táblázatos eloszlás tanulása.
[196] Nem táblázatos formára lásd a 20.7. feladatot, amelyben mindegyik paraméter hatással van számos feltételes valószínűségre.
[197] Azért hívjuk hiperparamétereknek, mert θ eloszlásának paramétereiről van szó, ahol θ maga is egy paraméter.
[198] További konjugált priorok: a diszkrét többváltozós eloszlások paramétereire a Dirichlet család, a Gauss-eloszlások paramétereire a Normal–Wishart család. Lásd Bernardo és Smith (1994).
