13.5. Lényegkiemelés
Sokszor az előfeldolgozás egyik fontos célja a (bemeneti) adatvektorok dimenziójának csökkentése. Míg a neurális háló elvileg tetszőleges dimenziószámmal képes dolgozni, a feleslegesen nagy adatdimenzió a hálózatot elbonyolítja, a szükséges súlyok és minták számának indokolatlan növekedéséhez vezet, és rendszerint a konvergenciát is jelentősen rontja. A nagy dimenzió okozta problémákat a dimenzió átka (curse of dimensionality) névvel szokták illetni.
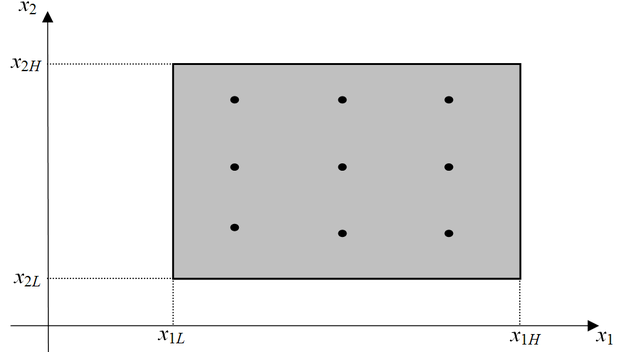
Tegyük fel, hogy egy N-bemenetű egykimenetű hálóval dolgozunk, és az bemeneti vektor komponenseinek mindegyike valamilyen határok közt vehet fel értékeket: . Akár regressziós (függvény approximációs) feladatot akarunk megoldani, akár osztályozási feladatot, rendszerint arra törekszünk, hogy azt az N-dimenziós térrészt, melyben minták előfordulhatnak egyenletesen lefedjük tanító (és teszt) mintákkal. Az egyenletes lefedés ugyanis biztosítja, hogy a tanított hálózat tényleges felhasználásakor bármilyen szituáció is fordul elő, egy ahhoz hasonló szituációt jelentő nem túl távol eső mintaponttal már tanítottuk hálózatot. Egydimenziós esetben, ha P ponttal le akarjuk fedni a használt tartományt, P mintára van szükségünk, kétdimenziós esetben ugyanolyan sűrűségű lefedettséghez már minta kell. Általánosságban N dimenzió esetén a dimenziónként P ponttal történő egyenletes lefedéshez szükséges minták száma . A 13.13 ábra N=2 esetén mutatja a dimenziónként P=3 ponttal való egyenletes lefedést, ami általában a szóba jöhető térrész elég hézagos kitöltését jelenti, de két dimenzió esetén már ehhez is 9 mintára van szükség, míg 10 dimenzió (bemenet) esetén már közel 60000 minta kell az ilyen sűrűségű lefedéshez.
A szükséges tanító minták száma a dimenzió számmal tehát exponenciálisan nő, ami gyakorlati feladatok megoldása során különösen nagy problémákat vet fel. (Szimulációs feladatoknál is gondot jelenthet a minták előállításának ideje, a szükséges tároló kapacitás, stb., de fizikai folyamatok modellezésénél, vagy gyakorlati osztályozási problémáknál további minták gyűjtése rendkívül drága, sőt, sok esetben nem is lehetséges.)
A dimenziószám-csökkentés legegyszerűbb módja, ha a mért paraméterek egy részét elhagyjuk. Kézenfekvő példákat nyújt erre a problémára és eljárásra az, amikor ipari folyamatok modellezését kívánjuk elvégezni mért adatok alapján. A mért adatok köre a megvalósított technológiában rendszerint jóval tágabb, mint ami a konkrét modellezési cél eléréséhez szükséges. (Pl. tipikusan mért és naplózott paraméter a technológiai lépések kezdeti és végidőpontja, ami legtöbbször irreleváns a modellezés szempontjából.) Elvileg persze megtehetjük azt is, hogy valamennyi mért paramétert felhasználjuk a modellezésben, a háló képes lehet a bemeneti súlyainak csökkentésével figyelmen kívül hagyni az érdektelen adatokat. Viszont lényegesen kisebb hálóméretet és jobb konvergenciát remélhetünk, ha a felesleges adatokat előzetes vizsgálatok során kiszűrjük, és csak a valóban fontosakra koncentrálunk.
Az egyszerű adatelhagyás nem, de a dimenziószám-csökkentés megvalósítható, ha a mért paraméterek valamilyen lineáris kombinációja hordozza a keresett információt, vagy legalábbis az információ jelentős részét. Pl. ha egy folyamat hőegyensúlyát kívánjuk modellezni, akkor elég lehet a különböző – de közel azonos fajhővel rendelkező – anyagok tömegének összegét figyelembe venni, ami az ehhez hasonló összevonásokkal együtt érdemi paraméterszám csökkenést eredményezhet. Az ilyen típusú dimenziócsökkentés történhet a folyamat fizikai jellemzőinek elemzésével, illetve statisztikai módszerek (pl. főkomponens analízis) segítségével.
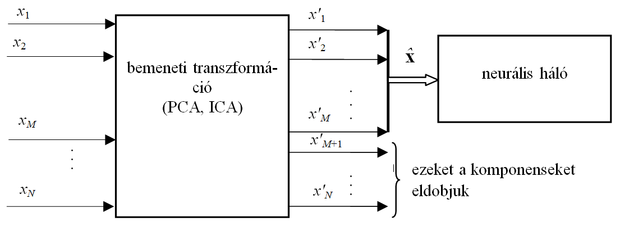
A 10. fejezetben már bemutattuk azokat a legelterjedtebb, általános, problémafüggetlen eljárásokat, amelyeket a dimenziószám-csökkentésben, lényegkiemelésben is alkalmazni szoktunk. A két leggyakrabban alkalmazott eljárás a főkomponens analízis (PCA), illetve a független komponenes analízis (ICA). Mindkét eljárással a bemeneti vektor komponeneseiből – rendszerint lineáris transzformációval – egy új (azonos méretű) vektort hozunk létre. Lényegkiemeléskor ennek a vektornak csak egyes komopnenseit őrizzük meg, a többit eldobjuk (ld. 13.14 ábra).
Mint az említett fejezetben láttuk, a PCA eljárás azt célozza, hogy az N-dimenziós bemeneti vektorokat olyan új M<N dimenziós térben ábrázoljuk, ahol négyzetes értelemben kicsi az eltérés. Tehát a bemeneti vektorokat transzformáljuk, majd elhagyjuk N-M komponensüket, vagy eleve olyan transzformációt használunk, amely létrehozza ezt a végeredményt. A transzformáció:
(13.35)
A transzformációs mátrixot úgy alakítjuk ki (a 11. fejezetben ismertetett módszerekkel), hogy -nek az első M komponenssel való közelítése várható értékben (átlagosan) a minimális négyzetes hibát adja.
Tehát:
(13.36)
A PCA közelítés eredménye a dimenziószám-csökkentés − minimális átlagos négyzetes hiba mellett.
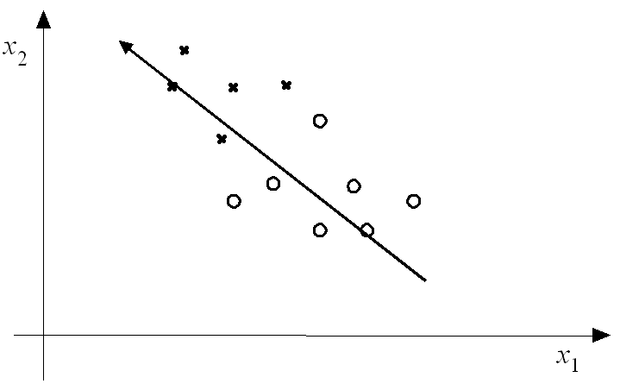
A 13.15 ábra egy egyszerű kétdimenziós osztályozási feladaton mutatja be a főkomponens analízisen alapuló dimenziószám-csökkentés lehetőségét. Az ábrán látható két osztály mintái önmagában a primer módon mért két változó egyikének használatával sem választhatók szét, de ha egy egyszerű lineáris transzformációval bevezetjük az változót, ami éppen a mintahalmaz egyik főkomponens iránya, akkor ezen egyetlen változó segítségével az osztályozás elvégezhető.
Ugyanakkor konkrét gyakorlati feladatoknál meg kell vizsgálni, hogy a legkisebb átlagos négyzetes hiba valóban kis információveszteséget jelent-e. Triviális példával élve: ha arcképeket akarunk felismerni, akkor a kis eltérések (pl. egy-egy anyajegy, forradás) viszonylag kis négyzetes hibát jelenthetnek a mintahalmazból kinyerhető "átlagos arcképhez" képest. Mégis éppen azt veszítjük el ezek elhanyagolása esetén, ami az arcképet könnyebben felismerhetővé teszi. Az összes képben nagy súllyal jelenlévő "átlagos arc" elhanyagolása a felismerhetőség szempontjából sokkal kevésbé lenne problematikus, mint a négyzetes értelemben kis súlyú részleteké.
Az ICA eljárással történő lényegkiemelés csak annyiban különbözik a PCA módszerrel történőtől, hogy más előfeldolgozási tarnszformációt alkalmazunk. Ugyanakkor jelentős különbség, hogy itt nem a vektor közelítő ábrázolásának minimális négyzetes hibája a cél, hanem a transzformációs mátrix vektorainak függetlensége, amelyet az ICA alkalmazásakor az eloszlások magasabbrendű momentumaival mérünk. Itt is elmondható, hogy önmagában minden feladatnál meg kell vizsgálni, hogy ez a függetlenség valóban a hasznos információk kiemelését jelenti-e.
A fentiekhez még két megjegyzést kell tennünk. A PCA/ICA/egyéb transzformációk előtt legtöbbször célszerű a normalizálást végrehajtani, különben a transzformáció a viszonylag nagy értékű és változékonyságú eredeti komponenseket fogja kiemelni. A transzformáció elvégzése után a kapott komponenseket a kívánt kimeneti értékkel célszerű lehet korreláltani. Valószínűleg a korreláció abszolútértékének nagysága alapján jobban el lehet dönteni, hogy mely komponenseket őrizzünk meg és melyeket hanyagoljunk el, mint pl. PCA-nál a legkisebb négyzetes hibakritérium alapján.
Természetesen a dimenziócsökkentés akkor egyszerűbb, ha a paraméterek között lineáris a kapcsolat, de elérhető az esetben is, ha az adatok közötti összefüggés nemlineáris, ilyenkor az összevonandó paraméterek kiválasztása és az összevonás elvégzése tipikusan nagyságrendekkel nehezebb feladat. Ez esetben neurális módszerek használata is felmerül a dimenziócsökkentésre. Példaként az autoasszociatív hálóval való adattömörítési módszereket vagy a kernel PCA eljárást említhetjük (ld. 10. fejezet).
A 13.16 ábrán látható folyamatábra azt a kettős iterációs ciklust mutatja, melyben a neurális háló tanításán túl az adatbázis átalakítása: dimenziószám módosítás, hihetőség vizsgálat is folyik a fejlesztés során.
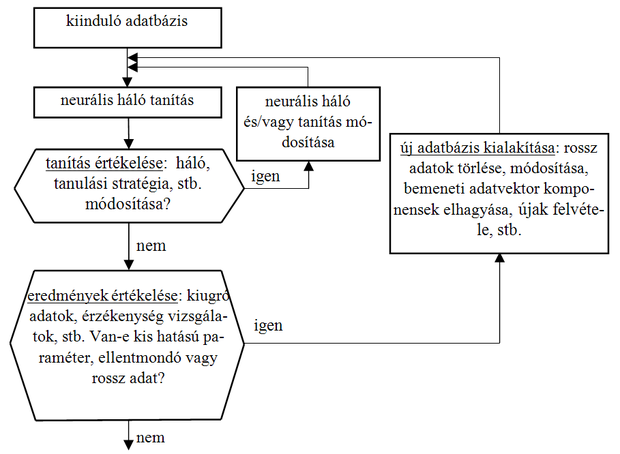
Az ábrán bemutatott alapgondolat a következő: amennyiben a neurális modellt megtanítottuk, akkor az elért teszt eredmények elemzését felhasználhatjuk az adatbázis, illetve az egyes adatok minősítésére is. A bemeneti vektor egyes komponenseit a modellen érzékenységvizsgálattal tesztelhetjük, tehát azt vizsgáljuk, hogy az adott bemenet változtatása, mekkora kimeneti változást idéz elő. Ha olyan bemeneteket találunk, melyek hatása a kimenetre elhanyagolható, akkor ezen bemenetek törlésével dimenziószám-csökkenést érhetünk el. Ez az eljárás rokon a hálózat méretének csökkentésével (pruning, ld. 4. fejezet), amikor felesleges súlyok vagy neuronok elhagyása a cél. Amennyiben a kiugró adatokat vizsgáljuk (tehát azokat, melyekre a neurális modell válasza nagyon rossz), akkor két olyan szituációval is találkozhatunk, mely az adatbázis minőségének javítását lehetővé teszi. Egyrészt kiderülhet, hogy a kiugró adat hibás, ekkor az adatvektort vagy töröljük az adatbázisból, vagy hibás komponensét megpróbáljuk korrigálni a 13.4 pontban leírt módszerek valamelyikével. Másrészt kiderülhet, hogy az adatbázis ellentmondást tartalmaz, tehát azonos (vagy közel azonos) bemeneti mintákra lényegesen eltérő kimenetet ad két vagy több adatvektor esetén. Ennek gyakran az az oka, hogy elhagytunk olyan releváns paramétert (a dimenziócsökkentés során), mely ezt a két szituációt megkülönböztetné. (Például ellentmondásos adatbázishoz jutunk, ha a 13.15 ábra osztályozási feladatát az változó elhagyásával, tehát csak -re támaszkodva, akarjuk megoldani. Azonos bemeneti értékhez különböző osztályokba sorolt minták fognak tartozni ebben a csökkentett dimenziós térben.) Ekkor a dimenziószám-növelést is vállalva fel kell vegyük ezt a paramétert is a bemeneti változók közé.
Feladatok
13.1 Készítsen egy kétbemenetű egykimenetű MLP hálót, amelynek első rejtett rétegében 5 tangens hiperbolikusz aktivációs függvényűnemlineáris feldolgozó neuron, kimeneti rétegében pedig egyetlen, lineáris neuron van. Tanítsa a hálót a következő Matlab kóddal megadott bemeneti és kimeneti jellel:
|
|
|
|
|
|
|
|
|
Végezze el a tanítást
-
nem normált bemeneti és kimeneti jelekkel,
-
[-1,+1] tartományra normált bemeneti, de nem normált kimeneti jelekkel,
-
egyaránt [-1,+1] tartományra normált be- és kimeneti jelekkel,
-
egyaránt 0 átlagértékűre és egységnyi szórásúra normált be- és kimeneti jelekkel.
A kiindulásnak javasolt tanítási paraméterek (Matlab környezetben):
|
|
|
|
|
|
Hasznos lehet, ha több maximális tanítási ciklusszám és célhiba paraméterrel is kísérletezik. Egy adott beállításnál végezze el a kísérletet többször (pl. 10-szer) és az egyes esetekben kapott átlagos négyzetes hibák sorozatait hasonlítsa össze! Mit tapasztal?
Vigyázat, pl. Matlabban a kijelzett átlagos négyzetes hiba (MSE) abszolút hiba jellegű, ezért a hiba értéke – még egyformán jó approximációk esetén is – értelemszerűen függ attól, hogy mekkora a kimeneti tartomány. Az összehasonlítást ezért úgy végezze el, hogy a megtanított hálót futtassa le újra a hozzá tartozó bemeneti adatokkal (Matlab sim() függvény), a kapott kimeneti eredményt transzformálja vissza az eredeti tartományba, és ott nézze meg a kívánt kimenettől való átlagos négyzetes eltérést!
13.2 Oldja meg a 13.1 feladatot úgy, hogy néhány ponton impulzusszerű zajt ad a bemeneti és kimeneti jelhez. Pl. az alábbi Matlab kóddal módosítva a fentiekben megadott jeleket:
x1(1,23)=-40;
x1(1,52)=+42;
x1(1,88)=+35;
x2(1,2)=-50;
x2(1,47)=-600;
d(1,66)=d(1,66)+50;
13.3 Oldja meg a 13.1 feladatot RBF háló alkalmazásával is! (Matlab: ne a newrbe(), hanem a newrb() függvényt használja.) A maximális első rétegbeli neuronszám legyen 30. Vizsgálja meg az approximációt az első rétegbeli (Gauss aktivációs függvényű)neuronok σ=1 és σ=10 értéke mellett is!
13.4 Készítsen egy kétbemenetű egykimenetű MLP hálót, amelynek első rejtett rétegében 5 tangens hiperbolikusz aktivációs függvényűnemlineáris feldolgozó neuron, kimeneti rétegében pedig egyetlen, lineáris neuron van. Tanítsa a hálót a következő Matlab kóddal megadott kétfajta bemeneti adattal. A kimeneti adatok mindkét esetre legyenek ugyanazok:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A kiindulásnak javasolt tanítási paraméterek (Matlab környezetben):
|
|
|
|
|
|
Hasznos lehet, ha több maximális tanítási ciklusszám és célhiba paraméterrel is kísérletezik. A 13.1 feladathoz hasonlóan a kísérletet itt is végezze el többször (pl. 10-szer), és hasonlítsa össze az egyes esetekben kapott átlagos négyzetes hibák sorozatait! Mit tapasztal?
