3.3. Egy processzáló elem szigmoid kimeneti nemlinearitással
Az előzőekben bemutatott két elemi neuron ugrásfüggvényt alkalmazott kimeneti nemlinearitásként. Az ugrásfüggvény következménye, hogy a kimenet nemlineáris függvénye a súlyvektornak, vagyis ha az elemi neuron kimeneténél értelmezzük a négyzetes kritériumfüggvényt, akkor nem kapunk kvadratikus hibafelületet. Sőt az ugrásfüggvény miatt a kritériumfüggvény nem is lesz mindenhol differenciálható. A differenciálhatóság és a négyzetes hibafelület hiánya a perceptronnál nem okozott gondot, hiszen ott nem gradiens alapú tanuló eljárást alkalmaztunk. Az adaline-nál a nem folytonos nemlinearitás hatását úgy védtük ki, hogy a hibát nem az igazi kimeneten, hanem a lineáris összegző kimenetén értelmeztük. A későbbiekben látni fogjuk, hogy egyik megoldás sem kedvező, ha ezeket az elemi neuronokat összetett neuronhálóknál szeretnénk használni, ahol a neuronhálók több, rétegekbe szervezett neuronokból állnak. Ilyen esetekben a perceptron tanulást azért nem alkalmazhatjuk, mert az csak olyan neuronok tanítására jó, ahol a neuron kimenetén tudjuk értelmezni a hibát. A pillanatnyi gradiens alapú LMS algoritmus alkalmazásának pedig a rejtett réteg neuronjainak kimenetén található nem differenciálható nemlinearitás az akadálya.
3.5. ábra - Szigmoid kimeneti nemlinearitással felépülő elemi neuron a hibaképzéssel és a paramétermódosítással
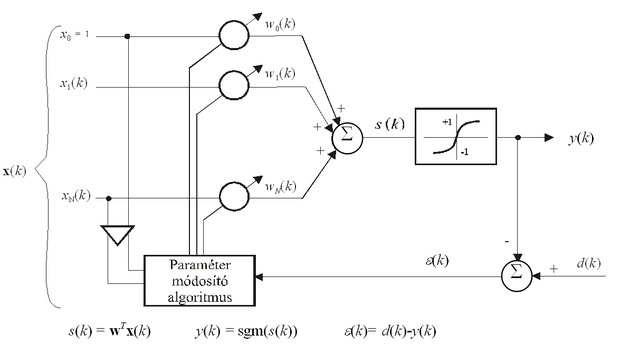
A probléma megoldását jelentheti, ha az ugrásfüggvényt helyettesítjük egy olyan függvénnyel, amely folytonos, differenciálható és az ugrásfüggvény közelítésének tekinthető. A folytonos, differenciálható nemlinearitással felépített elemi neuron biztosítja, hogy a kimenet a neuron szabad paramétereinek folytonos, differenciálható függvénye legyen, és így a paraméterek meghatározásánál − a neuron tanításánál − a gradiens eljárások alkalmazhatók legyenek.
Az így, az előzőekben bemutatott elemi neuron kismértékű módosításával létrejött neuront a 3.5 ábra mutatja. A neuron most is egy súlyozott összegzőből és az azt követő nemlinearitásból áll, a nemlinearitás azonban az előzőekben alkalmazott szignum függvény helyett a szigmoid függvény lesz. A szigmoid függvény folytonos, differenciálható, monoton növekvő, korlátos, telítődő függvény. Szigmoid függvénynek sokféle konkrét függvény alkalmazható. A két leggyakrabban alkalmazott szigmoid függvényt − a tangens hiperbolikusz függvényt és a logisztikus függvényt − az 1. fejezetben, az 1.3 (c) és (d) ábrákon mutattuk be.
A folytonos, differenciálható be-kimeneti leképezés miatt erre a neuronra már alkalmazhatók a gradiens eljárások, akkor is, ha a hibát nem a lineáris rész, hanem a teljes hálózat kimenetén értelmezzük.
, (3.24)
Ha a négyzetes hiba pillanatnyi gradiense
, (3.25)
alapján módosítjuk a súlyokat, akkor az LMS eljárás megfelelőjére jutunk. Itt a kimeneti nemlinearitás deriváltját jelöli.
A súlymódosítás a gradiens eljárásnak megfelelően a következőre adódik:
(3.26)
A kapott összefüggés annyiban különbözik az LMS algoritmustól, hogy itt az ε kimeneti hiba helyett egy δ =ε sgm'(s) "származtatott hiba" szerepel. (Megjegyezzük, hogy ezt a tanítási szabályt szokás ezért delta szabálynak (delta rule)is nevezni.)
A logisztikus illetve a tangens hiperbolikusz függvények nemlineáris transzfer függvényként (aktivációs függvényként)való alkalmazása azzal az előnnyel is jár, hogy a deriváltjuk könnyen számítható. Ugyanis:
-
a logisztikus függvény és a deriváltja:
(3.27)
-
míg a tangens hiperbolikusz függvény és a deriváltja:
. (3.28)
Az ugrásfüggvény nemlinearitás szigmoid függvényre való kicserélése − bármennyire is kismértékű módosításnak tűnik − fontos következményekkel jár. Ez biztosítja, hogy a tanítás gradiens eljárással lehetséges legyen, akkor is, ha a hibát az elemi neuron nemlineáris kimenetén értelmezzük, és ez teszi lehetővé, hogy az így létrejött elemei neuronból, mint építőelemből létrehozott összetett, többrétegű neuronháló szintén tanítható legyen gradiens alapú eljárással. A szigmoid függvény alkalmazása a neuron számítási képességét is megváltoztatja, azonban annak önmagában nincs jelentősége hogy egy neuron milyen leképezést tud megvalósítani. Ennél sokkal fontosabb, hogy a felhasználásával felépített többrétegű neuronhálók milyen képességekkel rendelkeznek. Ebben a tekintetben a legfontosabb eredményeket az 1. fejezetben mutattuk be: egy szigmoid nemlinearitást alkalmazó neuronokból felépített többrétegű, előrecsatolt háló univerzális osztályozó, illetve univerzális approximátor. Az ebben a fejezetben bemutatott elemi neuronok közül ezért a neuronhálók konstrukciójában a legfontosabb szerepet ez az elemi neuron játssza.
