22.5. Szemantikai értelmezés
Eddig csak a nyelv szintaktikai analízisét vizsgáltuk. Ebben a fejezetben rátérünk a szemantikára (semantics) – a megnyilatkozás (utterance) jelentésének kinyerésére. Ebben a fejezetben az elsőrendű logikát használjuk reprezentációs nyelvként, így a szemantikai értelmezés egy FOL kifejezés és egy nyelvi kifejezés összerendelésének a folyamata. Intuitív módon közelítve, a „the wumpus” kifejezés jelentése az a nagy, szőrös szörnyeteg, amit a logikában a Wumpus1 logikai kifejezéssel jelzünk, és a „the wumpus is dead” jelentése a Dead(Wumpus1) logikai állítás. Ez a fejezet ezt az intuíciót pontosítja. Egy egyszerű példával kezdünk: a négyzetháló helyszíneit leíró szabállyal:
NP → Digit Digit
Kiterjesztjük a szabályt úgy, hogy minden összetevőhöz egy argumentumot illesztünk, amely az összetevő szemantikáját reprezentálja. A következőt kapjuk:
NP([x, y]) → Digit(x) Digit(y)
E szerint egy karaktersorozat, amely egy x szemantikájú számjegyből és egy azt követő y szemantikájú számjegyből áll, egy [x, y] szemantikával rendelkező NP-t formál, amely a háló egy négyzetére alkalmazott jelölésünk.
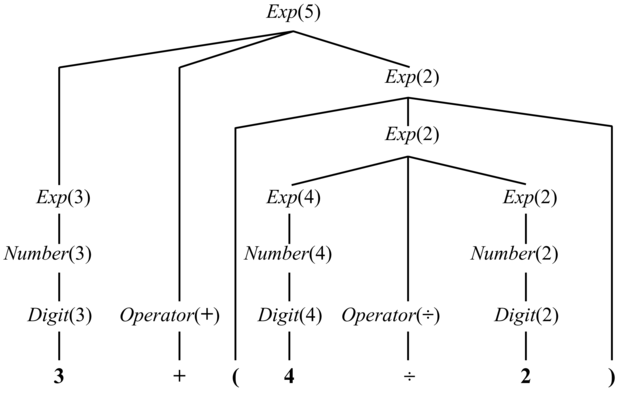
Vegyük észre, hogy a teljes NP szemantikája nagymértékben az összetevőinek szemantikáján alapszik. Már láttuk a kompozíciós szemantika (compositional semantics) ezen ötletét korábban: a logikában a P ∧ Q jelentését P, Q és ∧ határozzák meg; az aritmetikában az x + y jelentését x, y és a + határozzák meg. A 22.14. ábra megmutatja, hogy a DCG jelölésrendszer hogyan használható egy aritmetikai kifejezéseket leíró nyelvtan szemantikával történő kiterjesztésére, és a 22.15. ábra mutatja a 3 + (4 ÷ 2) ezen nyelvtan alapján kapott elemzési fáját. Az elemzési fa gyökere Exp(5), egy kifejezés, melynek szemantikai értelmezése 5.
22.14. ábra - Szemantikával kibővített nyelvtan az aritmetikai kifejezésekre. Minden xi változó egy öszszetevő szemantikáját reprezentálja. Vegye észre, hogy a {teszt} jelölést használjuk olyan logikai predikátumok definiálására, amelyeket ki kell elégíteni, de nem összetevők!

Most már készen állunk arra, hogy az angol nyelv egy kis részhalmazára megírjuk a szemantikai kibővítést. Első lépésként azzal kezdünk, hogy melyik kifejezéshez milyen szemantikai értelmezéseket akarunk rendelni. A „John loves Mary” egyszerű mondatot fogjuk vizsgálni. A „John” NP szemantikus értelmezése a John logikai term kell legyen, és a mondatnak, mint egésznek, a Loves(John, Mary) logikai állítás kell a szemantikai értelmezése legyen. Ennyi világosnak látszik. A bonyolultabb rész a „loves Mary” VP. Ezen kifejezés szemantikai értelmezése se nem logikai term, se nem teljes logikai mondat. Intuitív módon kezelhetjük úgy, hogy a „loves Mary” egy leírás, ami lehet, hogy egy adott személyre vonatkozik, de lehet, hogy nem. (Jelen esetben Johnra vonatkozik.) Ez azt jelenti, hogy a „loves Mary” egy predikátum (predicate), amit ha egy személyt reprezentáló termmel kombinálunk (a személy, aki szeret), akkor egy teljes logikai mondatot állít elő. A λ jelölésrendszert használva (lásd 7.2. alfejezet) a „loves Mary”-t a következő predikátumként reprezentálhatjuk:
λx Loves(x, Mary)
Ezután szükségünk van egy szabályra, amely szerint „egy obj szemantikájú NP, melyet egy rel szemantikájú VP követ, együtt egy olyan mondatot eredményez, amelynek szemantikája a rel alkalmazása az obj-ra:
S(rel(obj)) → NP(obj) VP(rel)
A szabály szerint a „John loves Mary” szemantikai értelmezése
(λx Loves(x, Mary))(John)
ami megfelel a Loves(John, Mary)-nek.
22.16. ábra - Egy nyelvtan, amely képes egy elemzési fa és szemantikai értelmezés levezetésére a „John loves Mary” (és három másik) mondat számára

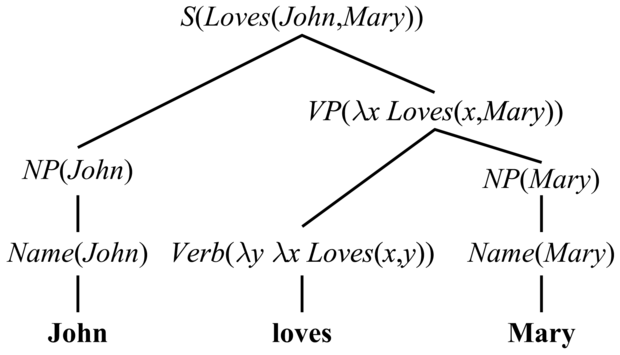
A szemantika hátralevő része az eddigi választásainkból egyenesen következik. Mivel a VP-ket predikátumként reprezentáljuk, jó ötlet konzisztens módon az igéket is predikátumként ábrázolni. A „loves” ige reprezentációja λy λx Loves(x, y) predikátum, ami például egy Mary argumentum esetén λx Loves(x, Mary) predikátummal tér vissza.
A VP → Verb NP szabály alkalmazza az ige szemantikai értelmezéséből kapott predikátumot az NP (szemantikai) értelmezéséből kapott objektumra a teljes VP szemantikai értelmezésének kinyerésére. Végül a 22.16. ábrán látható nyelvtant és a 22.17. ábrán található elemzési fát kapjuk.
Most tegyük fel, hogy a „John loves Mary” és a „John loved Mary” közötti különbséget szeretnénk reprezentálni. Az angol igeidőket (past [múlt], present [jelen] és future [jövő]) használ egy esemény relatív idejének jelzésére. Egy jó választás az események idejének reprezentálására a 10.3. alfejezet eseménykalkulus jelölésrendszere. Az eseménykalkulussal a két mondatunk a következőképpen értelmezhető:
e ∈ Loves(John, Mary) ∧ During(Now, e)
e ∈ Loves(John, Mary) ∧ After(Now, e)
Eszerint a „loves” és „loved” szavakra vonatkozó két lexikai szabályunk a következő lehet:
Verb(λy λx e ∈ Loves(John, Mary) ∧ During(Now, e)) → loves
Verb(λy λx e ∈ Loves(x, y) ∧ After(Now, e)) → loved
E változástól eltekintve a nyelvtannal kapcsolatban minden más változatlan marad, ami ösztönző hír; azt sugallja, hogy helyes úton járunk, ha ilyen könnyedén bonyolíthatjuk például az igeidővel (bár csak érintettük az időre és igeidőre vonatkozó teljes nyelvtan felszínét). E bemelegítésként elért sikerrel készen állunk egy sokkal nehezebb reprezentációs probléma kezelésére.
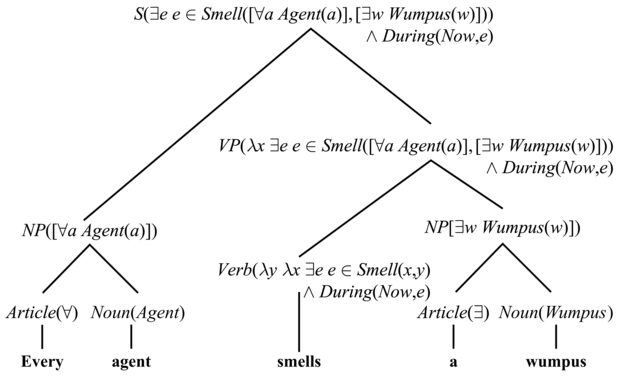
Nézzük a következő példát: „Every agent smells a wumpus.” A mondat valójában többértelmű: a javasolt értelmezés szerint az ágensek különböző wumpusokat észlelhetnek, de egy alternatív jelentés szerint csak egy wumpus van, akit mindenki érez.[231] A két interpretációt a következő módon ábrázolhatjuk:
∀a a ∈ Agents ⇒ ∃w w ∈ Wumpuses ∧ ∃e e ∈ Smell(a, w) ∧ During(Now, e)
∃w w ∈ Wumpuses ∀a a ∈ Agents ⇒ ∃e e ∈ Smell(a, w) ∧ During(Now, e)
A többértelműség problémáját elhalasztjuk későbbre, most csak az első értelmezést vizsgáljuk. Megpróbáljuk az összetevői szerint elemezni, NP és VP komponensekre bontva:
Every agent NP(∀a a ∈ Agents ⇒ P)
smells a wumpus VP(∃w w ∈Wumpuses ∧ ∃e (e ∈ Smell(a, w) ∧ During(Now, e))
Máris két nehézség támadt. Először is, a teljes mondat szemantikája, úgy tűnik, megegyezik az NP szemantikájával, melyben a VP tölti ki a P rész szemantikáját. Ez azt jelenti, hogy a mondat szemantikáját nem formálhatjuk rel(obj) segítségével. Megtehetjük obj(rel) által, ami (legalábbis első ránézésre) kicsit különösnek tűnik. A második probléma az, hogy az a változót a Smell reláció argumentumaként kell megkapnunk. Más szavakkal, a mondat szemantikája a VP szemantikájának megfelelő NP argumentumrekeszbe való illesztésével adódik, miközben az NP-ben található a változót is betesszük a VP szemantika megfelelő argumentumrekeszébe. Úgy tűnik, mintha két funkcionális kompozíciónk lenne, és ez azt sugallja, hogy meglehetősen könnyű lesz összezavarodni. A bonyolultság abból a tényből ered, hogy a szemantikai struktúra nagyon különböző a szintaktikaitól.
Hogy elkerüljék ezt a zűrzavart, sok modern nyelvtan más módszert választ. Definiálnak egy közbülső formát (intermediate form) a szintaxis és a szemantika közötti közvetítésre. A közbülső formának két kulcstulajdonsága van. Egyrészt strukturálisan hasonló a mondat szintaxisához, így könnyen előállítható kompozíciós eszközökkel. Másrészt elég információt tartalmaz, és így lefordítható egy reguláris elsőrendű logikai mondattá. Mivel a szintaktikai és a logikai alak között helyezkedik el, néha kvázilogikai formának (quasi-logical form)[232] nevezik. A fejezetben egy kvázilogikai formát használunk, mely a teljes elsőrendű logikát tartalmazza, lambdakifejezéssekkel és egy új konstrukcióval kiegészítve, amit kvantifikált termnek (quantified term) nevezünk. Az „every agent” szemantikai értelmezését jelentő kvantifikált term a következőképpen írható:
[∀a a ∈ Agents]
Ez olyan, mint egy logikai mondat, de ugyanolyan módon használjuk, mint a logikai termeket. Az „Every agent smells a wumpus” kvázilogikai értelmezése:
∃e (e ∈ Smell([∀a a ∈ Agents], [∃w w ∈Wumpuses]) ∧ During(Now, e))
A kvázilogikai alak generálásához szabályaink közül sok változatlan marad. Az S-re vonatkozó szabály S szemantikáját még mindig rel(obj) segítségével adja meg. Bizonyos szabályok változnak; az „a” szóra vonatkozó lexikai szabály a következő:
Article(∃) → a
míg a névelő és főnév kombinációjának szabálya:
NP([q x sem(x)]) → Article(q) Noun(sem)
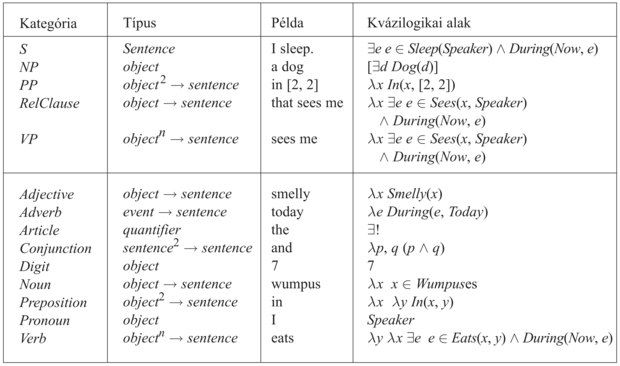
E szerint az NP szemantikája egy kvantifikált term – ahol a kvantifikálást a névelő határozza meg – egy új x változóval és egy propozícióval, amely a főnév szemantikáját az x változóra alkalmazza. Az NP-re vonatkozó további szabályok hasonlók. A 22.18. ábra mutatja be a szemantikai típusokat, és példát ad minden egyes szintaktikai kategóriára a kvázilogikai ábrázolás szerint. A 22.19. ábra az „Every agent smells a wumpus” e megközelítés szerinti elemzését mutatja, a 22.20. pedig a teljes nyelvtant.
Ezek után át kell alakítanunk a kvázilogikai formát valódi elsőrendű logikaivá a kvantifikált termek igazi term-mé alakításával. Ezt egy egyszerű szabállyal tesszük meg: minden egyes QLF kvázilogika formán belüli [q x P(x)] kvantifikált termet a cseréljük ki x-re, és cseréljük a QLF-et q x P(x) op QLF formára, ahol az op operátor ⇒ akkor, ha a q ∀, és ∧, amennyiben a q ∃ vagy ∃!. Például az „Every dog has a day (Minden kutyának van egy napja)” mondat a következő kvázilogikai formával rendelkezik:
∃e (e ∈ Has([∀d d ∈ Dogs], [∃a a ∈ Days], Now))
Nem specifikáltuk, hogy a két kvantifikált term melyikét kell elsőként elővenni, így valójában két lehetséges értelmezés van:
∀d d ∈ Dogs ⇒ ∃a a ∈ Days ∧ ∃e e ∈ Has(d, a, Now)
∃a a ∈ Days ∧ ∀d d ∈ Dogs ⇒ ∃e e ∈ Has(d, a, Now)
22.18. ábra - Minden szintaktikai kategória kvázilogikai formájú kifejezésének típusát mutató tábla. A t → r jelölés egy függvényt takar, amely egy t típusú argumentumot fogad, és r típusú eredménnyel tér vissza. Például a Preposition szemantikai típusa object2 → sentence, ami azt jelenti, hogy az elöljárószó szemantikája egy függvény, amelyet ha két logikai objektumra alkalmazunk, akkor egy logikai mondatot eredményez.
22.19. ábra - Az „Every agent smells a wumpus” mondat elemzési fája, amely mind a szintaktikai struktúrát, mind a szemantikai értelmezéseket mutatja

Az első szerint minden kutyának megvan a maga napja, míg a második szerint van egy különleges nap, ami minden kutyára ugyanaz. A kettő közötti választás a többértelműség feloldásának feladata. A kvantifikált termek balról jobbra sorrendje gyakran illeszkedik a kvantifikálók balról jobbra sorrendjére, de más tényezők is számítanak. A kvázilogikai alak előnye az, hogy tömören reprezentálja az összes lehetőséget. A hátránya pedig az, hogy nem segíti a választást közöttük; amihez szükségünk van a többértelműség feloldásának teljes erejére az összes tényt felhasználva.
Megmutattuk, hogy egy ágens hogyan képes észlelni egy szófüzért, és hogyan képes egy nyelvtant használni a lehetséges szemantikai értelmezések halmazának előállítására. Most annak a problémáját vizsgáljuk, hogy az értelmezés hogyan tehető teljessé az egyes jelöltek értelmezéshez az adott szituációt leíró kontextusfüggő információk hozzáadásával.
A gyakorlati információra legnyilvánvalóbban a referenciális indexek (indexicals) feloldásához van szükség, amelyek közvetlenül az adott szituációra utaló kifejezések. Például az „I am in Boston today (Ma Bostonban vagyok)” mondatban az „I” és „today” referenciális indexek értelmezése attól függ, hogy ki és mikor ejtette ki a mondatot. A referenciális indexeket „konstansokkal” (mint például a Speaker) reprezentáljuk, amelyek valójában változó dolgok (fluents) – azaz a szituációtól függnek. A hallgatónak, aki észleli a szólásaktust, azt is észlelnie kell, hogy ki a beszélő, és felhasználja ezt az információt a referenciális indexek feloldására. Például a hallgató tudhatja, hogy T((Speaker = AgentB), Now).
Egy felszólítás, mint például a „go to 2, 2” implicit módon a hallgatóra vonatkozik. Eddig az S nyelvtanunk csak deklaratív mondatokat írt le. Könnyen kiterjeszthetjük felszólítások kezelésére.[233]
A felszólítást olyan VP segítségével formálhatjuk, ahol az alany implicit módon a hallgató. Meg kell különböztetnünk a felszólításokat az állításoktól, ezért megváltoztatjuk az S-re vonatkozó szabályokat a szólásaktus típusának beillesztésével a kvázilogikai formába:
S(Statementl(Speaker, rel(obj))) → NP(obj) VP(rel)
S(Command(Speaker, rel(Hearer))) → VP(rel)
Így a „go to 2, 2” kvázilogikai alakja:[234]
Command(∃e e ∈ Go(Hearer, [2, 2]))
Eddig egy nyelv elemzésével foglalkoztunk, nem a generálásával. A generálás hasonlóan gazdag téma. A megfelelő megnyilatkozás kiválasztása egy állítás kifejezésére sok hasonló választást von maga után, mint egy megnyilatkozás elemzése.
Emlékezzünk vissza, hogy a DCG egy logikai programozási rendszer, amely kényszereket határoz meg egy karaktersorozat és annak elemzése között. Tudjuk, hogy az Append predikátum logikai programozási definíciója felhasználható annak közlésére is, hogy az Append([1, 2], [3], x) esetében x = [1, 2, 3], és arra is, hogy felsoroljuk azon x és y értékeket, melyek az Append(x, y, [1, 2, 3]) kifejezést igazzá teszik. Hasonlóképpen írhatunk egy definíciót S-re, amely kétféleképpen használható: az elemzéshez megkérdezzük, hogy S(sem, [John, Loves, Mary]), és azt kapjuk vissza, hogy sem = Loves(John, Mary); a generáláshoz azt kérdezzük, hogy S(Loves(John, Mary), words), és azt kapjuk vissza, hogy words = [John, Loves, Mary]. Tesztelhetünk egy nyelvtant az S(sem, words) kérdéssel, visszakapva azokat a [sem, words] párok sorozatát válaszként, melyeket a nyelvtan generált.
Ez a módszer a fejezetben bemutatott egyszerű nyelvtanokra működik, de nagyobb nyelvtanokra történő felskálázás során lehetnek problémák. A logikai következtető gép által használt keresési stratégia nagyon fontos; a mélységi keresési stratégiák végtelen ciklusokhoz vezethetnek. Figyelmet kell fordítani a szemantikai alak pontos részleteire is. Előfordulhat, hogy egy adott nyelvtan nem tudja kifejezni az X ∧ Y logikai alakot az X és Y bizonyos értékeire, de ki tudja fejezni Y ∧ X-et; ez azt sugallja, hogy szükségünk lesz valamilyen módszerre a szemantikai alakok kanonizálására, vagy ki kell terjesztenünk az egyesítő eljárást úgy, hogy az X ∧ Y és az Y ∧ X egyesíthető legyen.
Komolyabb generálási feladatok bonyolultabb modelleket használnak, melyek különböznek az elemzés nyelvtanától, és pontosabban szabályozzák, hogy a szemantikai komponenseket pontosan hogyan fejezzük ki. A szisztematikus nyelvtan egy olyan megközelítés, amely könnyűvé teszi, hogy a szemantikai alak legfontosabb részeire nagyobb hangsúlyt helyezzünk.
[231] Ha ez az értelmezés valószínűtlennek tűnik, akkor vizsgálja meg az „Every Protestant believes in a just God” mondatot.
[232] Egyes kvázilogikai formákra jellemző az is, hogy olyan többértelműségek tömör kifejezésére is alkalmasak, amelyeket logikai formában csak hosszú diszjunkciók segítségével lehetne kifejezni.
[233] Egy teljes kommunikáló ágens megvalósításához szükségünk lenne a kérdések nyelvtanára is. A kérdések kezelése kívül esik e könyv területén, mivel összetevők közötti hosszú távú függőségeket (long-distance dependecies) vonzanak magukkal. Például a „Whom did the agent tell you to give the gold to?” mondatban a záró „to” elemzésének hiányzó NP-jű PP-nek kell lennie; a hiányzó NP-t a mondat első szava, a „who” helyettesíti. Kiterjesztések egy komplex rendszere biztosítja, hogy a hiányzó NP-k összeillesztődjenek a helyettesítő szavakkal.
[234] Vegyük észre, hogy egy felszólítás kvázilogikai formája nem foglalja magában az esemény idejét (azaz a During(Now, e)-t)! Ez azért van, mert a „go” valójában a szó igeidő nélküli változata, nem a jelen idejű. Nem lehet megállapítani a különbséget a „go” esetében, de figyelje meg a „Be good!” felszólítás helyes alakját (a „be” igeidő nélküli alakját használva), amely nem „Are good!”. Annak biztosítására, hogy a helyes igeidőt használjuk, kiegészíthetnénk a VP-ket egy igeidő kiterjesztéssel, és a felszólítások szabályának jobb oldalára ezt írhatnánk: VP(rel, untensed).
