19.1. A tanulás logikai megfogalmazása
A 18. fejezetben a tisztán induktív tanulást olyan folyamatnak tekintettük, amely egy, az adatokkal konzisztens hipotézist keresett. Most ezt a definíciót olyan esetre pontosítjuk, amikor a hipotézist logikai állítások halmazával reprezentáljuk. A példaleírások és besorolások szintén logikai állítások, egy új példát pedig úgy tudunk osztályozni, hogy egy osztályozó állítást a hipotézisből és a példa leírásából kikövetkeztetünk. Ezzel a megközelítéssel a hipotéziseket inkrementálisan, állításonként építhetjük. A megközelítés lehetővé teszi az a priori tudás használatát is, mivel a már megismert állításokat bevethetjük új példák osztályozásába. A tanulás logikai megfogalmazásában először látszólag sok a munka, ez azonban a tanulás számos aspektusát segíti tisztázni. Ez lehetővé teszi, hogy a 18. fejezetben megismert egyszerű tanulási módszereket jócskán túlszárnyaljuk azáltal, hogy a logikai következtetés teljes erejét tanulási célokra használjuk.
Emlékezzünk a 18. fejezetben a tanulási problémára bemutatott étterem példára: egy olyan döntési szabály megtanulására, hogy vajon érdemes-e egy asztalra várni. A példákat olyan attribútumokkal (attributes) írtuk le, mint az Alternatíva, Bár, Péntek/Szombat stb. Logikai megközelítésben egy példa egy logikai állítással leírt objektum; az attribútumok pedig unáris predikátumok. Nevezzük általánosságban az i-edik példát Xi-nek. A 18.3. ábra első példáját az alábbi állítások írják le:
Alternatíva(X1) ∧ ¬Bár(X1) ∧ ¬PéntekSzombat(X1) ∧ Éhes(X1) ∧ …
A Di(Xi) jelöléssel az Xi leírására fogunk hivatkozni, ahol Di tetszőleges, egyargumentumú logikai kifejezés lehet. Az objektumok osztályozását a
VárjunkE(X1)
állítás végzi. Pozitív példák esetén a Q(Xi), negatív példák esetén a ¬Q(Xi) általános jelölést fogjuk használni. A teljes tanító halmaz az összes leíró és besoroló állítás konjunkciója.
Logikai megközelítésben az induktív tanulás célja a Q célpredikátummal ekvivalens logikai kifejezés megtalálása, amivel korrektül tudjuk a példákat osztályozni. Mindegyik hipotézis egy-egy javaslat a keresett logikai kifejezésre, amit mi a célpredikátum definíciójelöltjének (candidate definition) nevezünk. Jelöljük Ci-vel a definíciójelöltet, ekkor mindegyik Hi hipotézis egy ∀x Q(x) ⇔ Ci(x) formájú kifejezés. Például a döntési fa azt fejezi ki, hogy a célpredikátum egy objektum esetében csak akkor igaz, ha az igaz-hoz vezető egyik ága teljesül. Így a 18.6. ábrán látható döntési fa a következő logikai definíciót fejezi ki (amelyre a jövőben Hr-rel fogunk hivatkozni):
∀r VárjunkE(r) ⇔ Vendégek(r, Néhány)
∨ Vendégek(r, Tele) ∧ Éhes(r) ∧ Konyha(r, Francia)
∨ Vendégek(r, Tele) ∧ Éhes(r) ∧ Konyha(r, Thai)
∧ Péntek/Szombat(r)
∨ Vendégek(r, Tele) ∧ Éhes(r) ∧ Konyha(r, Burger) (19.1)
Mindegyik hipotézis azt jósolja meg, hogy példák egy bizonyos halmaza, nevezetesen azok, amelyek kielégítik a hipotézisdefiníció jelöltjét, a célpredikátumnak megfelelő példák lesznek. Ezt a halmazt a predikátum kiterjedésének (extension) nevezzük. Két különböző kiterjedéssel rendelkező hipotézis így logikailag ellentmondásban van egymással, hiszen legalább egy példa esetén eltérő eredményt jósolnak. Ha viszont azonos a kiterjedésük, akkor logikailag ekvivalensek.
A H hipotézistér ezek után az összes olyan hipotézis {H1, …, Hn} halmaza, amelyek kezelésére a tanuló algoritmust tervezték. Például DÖNTÉSI-FA-TANULÁS algoritmus az adott attribútumokkal kialakítható összes döntési fa hipotézissel képes foglalkozni; így hipotézistere az összes döntési fát tartalmazza. Feltehetően a tanuló algoritmus hisz abban, hogy az egyik hipotézis korrekt, azaz hisz a
H1 ∨ H2 ∨ H3 ∨ … ∨ Hn (19.2)
logikai kifejezésben. Ahogy a példák érkeznek, a példákkal nem konzisztens (consistent) hipotéziseket ki lehet zárni. Vizsgáljuk meg alaposabban a konzisztencia ezen fogalmát. Nyilvánvaló, hogy ha a Hi hipotézis a teljes tanító halmazzal konzisztens, akkor mindegyik példával konzisztensnek kell lennie. Mit jelent viszont az, hogy valamelyik példával ellentmondásban van? Ez kétféle módon történhet meg:
-
A hipotézis szempontjából egy példa hamis negatív (false negative), ha a valóságban pozitív, de a hipotézis szerint negatív. Például a következő leírással rendelkező X13 új példa:
Vendégek(X13, Tele) ∧ BecsültVárakozásE(X13, 0-10) ∧ ¬Éhes(X13) ∧ … ∧ ∧VárjunkE(X13)
a korábban definiált Hr hipotézis számára hamis negatív példa lesz. Hr-ből, illetve a példa leírásából kikövetkeztethető mind a VárjunkE(X13) – ezt állítja a példa, mind a ¬VárjunkE(X13) – ezt állítja a hipotézis. Tehát a hipotézis és a példa logikailag ellentmondásban van.
-
A hipotézis szempontjából egy példa hamis pozitív (false positive), ha a valóságban negatív, de a hipotézis szerint pozitív.[189]
Ha egy példa hamis negatív vagy hamis pozitív egy hipotézis szempontjából, akkor a példa és a hipotézis logikailag ellentmondásban van egymással. Feltéve, hogy a példa a tények korrekt megfigyelésén alapul, a hipotézist kizárhatjuk. Logikailag ez a következtetés a rezolúciós szabállyal pontos analógiában van (lásd 9. fejezet). Hipotézisek diszjunkciója felel meg egy klóznak, a példa pedig megfelel annak a literálisnak, amely a klózban levő egyik literálissal rezolvál. Egy szokásos logikai következtető rendszer tehát elméletileg tud példákból tanulni oly módon, hogy egy vagy több hipotézist kizár. Tegyük fel például, hogy a példát az I1 állítással jelöljük, és a hipotézistér H1 ∨ H2 ∨ H3 ∨ H4. Ha I1 ellentmondásban van H2-vel és H3-mal, akkor a logikai következtető rendszer származtatni tudja az új H1 ∨ H4 hipotézisteret.
Tehát az induktív tanulást logikai leírással olyan folyamatként jellemezhetjük, mint amelyik fokozatosan kizárja a példáknak ellentmondó hipotéziseket, leszűkítve a lehetőségek körét. Mivel a hipotézistér rendszerint nagy (vagy elsőrendű logika esetén egyenesen végtelen), nem javasoljuk egy rezolúcióalapú tételbizonyító rendszer építését és a hipotézistér teljes számbavételét. Ehelyett két megközelítést tárgyalunk, amelyek sokkal kisebb erőfeszítéssel logikailag ellentmondásmentes hipotéziseket képesek találni.
A pillanatnyilag legjobb hipotézis (current-best-hypothesis) keresési eljárás alapgondolata az, hogy egyetlen hipotézist vegyünk figyelembe, és ha új példa érkezik, akkor ennek figyelembevételével alakítsuk át a hipotézist annak érdekében, hogy az ellentmondás-mentességet fenntartsuk. Az algoritmus alapját John Stuart Mill írta le (Mill, 1843), de könnyen lehet, hogy már korábban megalkották.
Tegyük fel, hogy van valamilyen hipotézisünk, például Hr, amit már meglehetősen megkedveltünk. Amíg egy új példával sincs ellentmondásban, semmit sem kell tennünk. Aztán egyszer csak egy hamis negatív példa (X13) érkezik. Mit csináljunk? A 19.1. (a) ábra sematikusan úgy mutatja be Hr-t, mint egy területet, a négyszögön belül minden Hr kiterjedésébe tartozik. Az eddig látott példákat „+” vagy „–” jelöli, és látható, hogy Hr jól sorolja be az összes példát, mint VárjunkE pozitív vagy negatív példáit. A 19.1. (b) ábrán egy új – hamis negatív – példa jelenik meg (bekarikázva): a hipotézis azt állítja, hogy negatív, pedig valójában pozitív példa. A hipotézis kiterjedését növelni kell ahhoz, hogy tartalmazza ezt a példát is. Ezt a lépést általánosításnak (generalization) nevezzük: egy lehetséges általánosítás a 19.1. (c) ábrán látható. Ezután a 19.1. (d) ábrán egy hamis pozitív példát látunk: a hipotézis azt állítja, hogy pozitív, pedig valójában negatív. A hipotézis kiterjedését csökkenteni kell ahhoz, hogy kizárjuk ezt a példát. Ezt szűkítésnek (specialization) nevezzük; a 19.1. (e) ábrán a hipotézis egy lehetséges szűkítését látjuk.
19.1. ábra - (a) Egy konzisztens hipotézis. (b) Egy hamis negatív példa. (c) A hipotézist általánosítottuk. (d) Egy hamis pozitív példa. (e) A hipotézist szűkítettük.
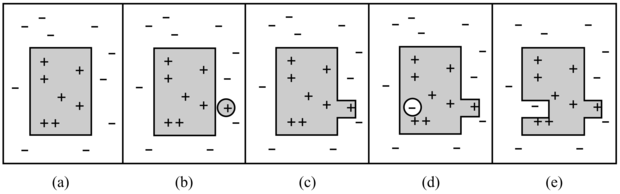
Most már specifikálni tudjuk a 19.2. ábrán látható PILLANATNYILAG-LEGJOBB-TANULÁS algoritmusát. Vegyük észre, hogy valahányszor általánosítjuk vagy szűkítjük a hipotézist, ellenőriznünk kell az összes többi példára, hiszen nincs garancia arra, hogy a kiterjedés önkényes növelése/csökkentése elkerüli bármelyik másik negatív/pozitív példa befoglalását/kirekesztését.
19.2. ábra - A pillanatnyilag-legjobb-hipotézis tanuló algoritmus. Konzisztens hipotézist keres és viszszalép, ha nem található konzisztens szűkítés/általánosítás.

Az általánosítást és a szűkítést úgy definiáltuk, mint olyan műveleteket, amelyek a hipotézis kiterjedését változtatják meg. Most pontosan meg kell határoznunk azt, hogy ezek a műveletek hogyan implementálhatók olyan szintaktikus műveletekként, amelyek a hipotézishoz rendelt definíciójelöltet úgy változtatják meg, hogy azt egy program végre tudja hajtani. Ehhez először is vegyük észre, hogy az általánosítás és a szűkítés egyben hipotézisek közötti logikai relációk. Ha a C1 definíciónak megfelelő H1 hipotézis a C2 definíciónak megfelelő H2 hipotézis általánosítása, akkor fenn kell állnia annak, hogy:
∀x C2(x) ⇒ C1(x)
Tehát ahhoz, hogy a H2 hipotézis általánosítását létrehozzuk, egyszerűen egy olyan C1 definíciót kell találnunk, amelyik logikailag következik C2-ből. Ezt könnyen megtehetjük. Ha például C2(x) Alternatíva(x) ∧ Vendégek(x, Néhány), akkor egy általánosítási lehetőség a C1(x) ≡ Vendégek(x, Néhány). Ezt feltételek törlésének (dropping conditions) nevezzük. Felfoghatjuk úgy, hogy egy gyengébb definíció jön létre, így a pozitív példák nagyobb halmazát teszi lehetővé. Számos egyéb általánosítási eljárás is létezik, azon nyelvtől függően, amelyen a műveleteket végezzük. Hasonlóképpen, egy hipotézist szűkíteni tudunk, ha további feltételeket adunk a hozzá tartozó definíciójelölthöz, illetve ha eltávolítunk tagokat egy diszjunktív definícióból. Lássuk, hogyan működik ez az éttermi feladatban, 18.3. ábra adatait használva:
-
Az első példa – X1 – pozitív. Alternatíva(X1) igaz, tehát vegyük fel a következő kiinduló hipotézist:
H1: ∀x VárjunkE(x) ⇔ Alternatíva(x)
-
A második példa – X2 – negatív. H1 alapján pozitív lenne, így hamis pozitív. Ezért szűkítenünk kell H1-et. Ezt megtehetjük például úgy, hogy egy olyan további feltételt adunk hozzá, amely feltétel kizárja X2-t. Egy lehetőség:
H2: ∀x VárjunkE(x) ⇔ Alternatíva(x) ∧ Vendégek(x, Néhány)
-
A harmadik példa – X3 – pozitív. H2 alapján negatív lenne, így hamis negatív. Tehát általánosítanunk kell H2-t. Ezt elérhetjük, ha töröljük Alternatíva feltételt, amely a következő hipotézisre vezet:
H3: ∀x VárjunkE(x) ⇔ Vendégek(x, Néhány)
-
A negyedik példa – X4 – pozitív. H3 alapján negatív lenne, így hamis negatív. Így általánosítanunk kell H3-at. Nem törölhetjük Vendégek feltételt, mert ez egy mindent tartalmazó hipotézishez vezetne, ami ellentmondásban van X2-vel. Egyik lehetőség a következő diszjunkció bevezetése:
H4: ∀x VárjunkE(x) ⇔ Vendégek(x, Néhány)
∨ (Vendégek(x, Tele) ∧ Péntek/Szombat(x))
A hipotézis ezek után már kezd ésszerűnek tűnni. Nyilvánvaló, hogy más lehetőségek is vannak, amelyek konzisztensek az első négy példával, kettő ezek közül:
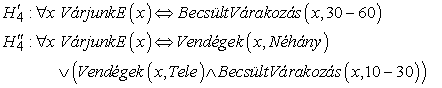
A PILLANATNYILAG-LEGJOBB-TANULÁS algoritmusát nem determinisztikusan írjuk le, mivel bármely ponton számos olyan szűkítési vagy általánosítási lehetőség lehet, melyek bármelyikét alkalmazhatjuk. A már meghozott döntések nem szükségszerűen vezetnek a legegyszerűbb hipotézishez, sőt olyan megoldhatatlan szituációhoz is vezethetnek, amelyben nincs a hipotézisnek olyan egyszerű módosítása, amely minden adattal konzisztens hipotézist állít elő. Ilyen esetekben a programnak egy előző választási ponthoz kell visszalépnie.
A PILLANATNYILAG-LEGJOBB-TANULÁS algoritmusát – és különböző változatait – számos gépi tanulást felhasználó rendszerben alkalmazták, először Patrick Winston (Winston, 1970) „ív-tanuló” programjában. Azonban ha a tér nagy, és nagyszámú példával dolgozunk, akkor bizonyos nehézségek merülnek fel:
-
Az összes előző példa újraellenőrzése minden egyes módosításnál nagyon munkaigényes.
-
Nehéz jó keresési heurisztikát találni, és a visszalépések örökké tarthatnak. Mint a 18. fejezetben már láttuk, a hipotézistér kétszeresen exponenciálisan nagy tér lehet.
A visszalépésre azért van szükség, mert a „pillanatnyilag-legjobb-hipotézis” eljárásban választani kell egy legjobb becslést, egy partikuláris hipotézist, akkor is, ha még nincs elég adatunk ahhoz, hogy biztosak legyünk a választásunk helyességében. Ehelyett azt tehetjük, hogy az összes olyan és csak olyan hipotézist megtartjuk, amelyek az eddigi adatainkkal konzisztensek. Ezek után mindegyik új eset vagy nincs hatással, vagy kizár néhányat a hipotéziseink közül. Emlékezzünk arra, hogy a hipotézistér egy diszjunktív állításnak tekinthető:
H1 ∨ H2 ∨ H3 ∨ … ∨ Hn
Ahogy egyre több hipotézis bizonyul a példákkal inkonzisztensnek, ez a diszjunktív állítás zsugorodik, csak azokat a hipotéziseket tartva meg, amelyeket nem szűrtünk ki. Feltéve, hogy az eredeti hipotézistér tartalmazza a helyes választ, a redukált diszjunktív állításnak is szükségszerűen tartalmaznia kell azt, hiszen csak inkorrekt hipotéziseket szűrtünk ki. A megmaradt hipotézisek halmazát nevezzük verziótérnek (version space). Az ilyen elven működő tanulási algoritmust (amelyet a 19.3. ábrán vázoltunk fel) verziótér tanulási algoritmusnak (más néven jelölteltávolítási – candidate elimination – algoritmusnak) nevezzük.
19.3. ábra - Verziótér tanuló algoritmus. V-nek olyan részhalmazát tanulja meg, amelynek elemei a példákkal konzisztensek.

Fontos tulajdonsága ennek a megközelítésnek, hogy inkrementális: soha nem kell visszalépnünk és újravizsgálnunk a régi példákat. Az összes megmaradt hipotézis garantáltan konzisztens az összes példával. Másrészt legkisebb megkötés elvű (least commitment) algoritmusnak is nevezhetjük, ugyanis nem tesz önkényes választásokat (vö. a 11. fejezetben található részben rendezett tervkészítő algoritmussal). Van viszont egy nyilvánvaló probléma. Már leszögeztük, hogy a hipotézistér óriási, hogyan tudjuk akkor leírni ezt az óriási diszjunktív állítást?
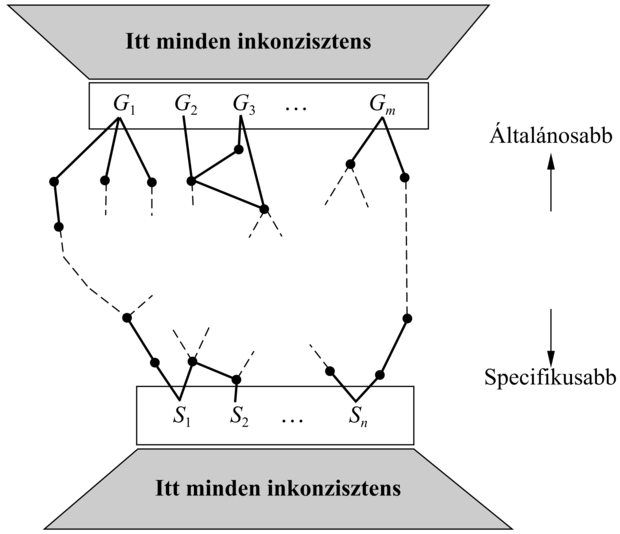
A következő egyszerű analógia sokat segít a megértésben. Hogyan ábrázoljuk az öszszes 1 és 2 közé eső valós számot? Végül is végtelen sok ilyen van! A megoldás az intervallumábrázolás, amelyik csak a halmaz határait specifikálja: [1, 2]. Ez azért működik, mert a valós számok felett értelmezett egy rendezés.
A hipotézistér felett is rendelkezünk rendezéssel, nevezetesen az általánosítás/szűkítés alapján. Ez egy részleges rendezés, ami azt jelenti, hogy a határ nem egy pont, hanem a hipotézisek egy halmaza: a határhalmaz (boundary set). A nagyszerű a dologban az, hogy a teljes verziótér reprezentálható csupán két határhalmaz: egy legáltalánosabb határhalmaz (a G halmaz) és egy legszűkebb határhalmaz (az S halmaz) segítségével. E kettő közé eső bármely hipotézis garantáltan konzisztens az összes példával. Mielőtt ezt bizonyítjuk, röviden foglaljuk össze az eddigieket:
-
A jelenlegi verziótér azon hipotézisek halmaza, amelyek az összes eddigi példával konzisztensek. Ezt az S halmaz és a G halmaz segítségével ábrázoljuk, mindkettő a hipotézisek valamilyen halmaza.
-
Az S halmaz összes eleme konzisztens az összes eddigi megfigyeléssel, és nincs ennél szűkebb konzisztens hipotézis.
-
A G halmaz összes eleme konzisztens az összes eddigi megfigyeléssel, és nincs ennél általánosabb konzisztens hipotézis.
Azt kívánjuk meg, hogy a kezdeti tér (mielőtt bármelyik példát megvizsgáltuk volna), az összes elképzelhető hipotézist tartalmazza. Ezt úgy biztosítjuk, hogy a G halmazt egyszerűen az Igaz értékre állítjuk (az a hipotézis, amely mindent tartalmaz), az S halmazt pedig egyszerűen a Hamis értékre állítjuk (az a hipotézis, amelynek kiterjedése üres).
A 19.4. ábra a verziótér határhalmazokkal való ábrázolásának általános struktúráját mutatja. Ahhoz, hogy megmutassuk, hogy ez az ábrázolás elégséges, két tulajdonságra van szükségünk:
-
Mindegyik konzisztens hipotézis (amelyik nem valamelyik határhalmaz eleme) szűkebb, mint a G halmaz valamelyik eleme, és általánosabb, mint az S halmaz valamelyik eleme. (Azaz nincsenek kívül „kóbor” elemek.) Ez közvetlenül következik az S és G definíciójából. Ha lenne egy kóbor h, akkor az vagy nem lehetne szűkebb G valamely eleménél, tehát G-hez kellene tartoznia, vagy nem lehetne általánosabb S valamely eleménél, ebben az esetben viszont S-hez tartozna.
-
Mindegyik hipotézis, amelyik szűkebb a G halmaz valamely eleménél, és általánosabb az S halmaz valamely eleménél, konzisztens hipotézis (azaz a határok között nincsenek „lyukak”). Bármely – az S és G közé eső – h-nak az összes olyan negatív példát vissza kell utasítania, amelyet G minden egyes tagja visszautasít (mivel szűkebb), ugyanakkor el kell fogadnia az összes pozitív példát, amelyet az S akármelyik tagja elfogad (mivel általánosabb). Így h az összes példát jól kezeli, tehát nem lehet inkonzisztens. A 19.5. ábra mutatja be a helyzetet: nincs ismert példa, amely S-en kívül, de G-n belül helyezkedik el, így a kettő közt elhelyezkedő összes hipotézisnek konzisztensnek kell lennie.
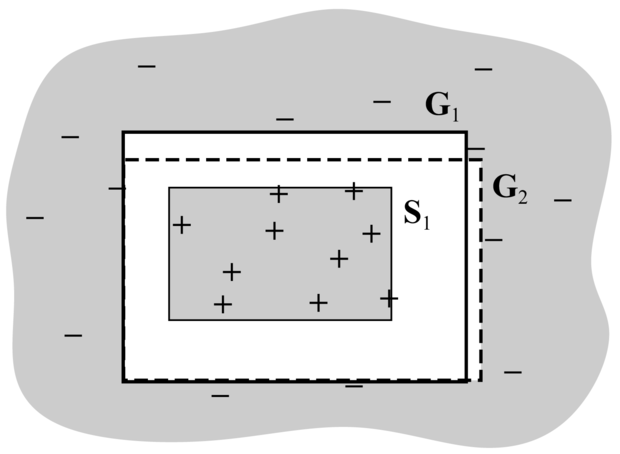
Bemutattuk tehát, hogy ha S-t és G-t definíciójuknak megfelelően kezeljük, akkor a verziótér kielégítő leírását adják. Az egyetlen hátralévő probléma, hogy hogyan módosítsuk S-t és G-t egy új példa esetén (a VERZIÓ-TÉR-MÓDOSÍTÁS függvény feladata). Elsőre ez meglehetősen bonyolultnak tűnik, de a definíciók és a 19.4. ábra alapján nem túl nehéz az algoritmus előállítása.
Az S és G halmazok Si és Gi elemeivel kell foglalkoznunk. Az új példa bármelyik esetén lehet hamis pozitív vagy hamis negatív.
-
Si-re hamis pozitív. Azt jelenti, hogy Si túl általános, de mivel Si-nek (a definíciója értelmében) nincs konzisztens szűkítése, így Si-t eltávolítjuk az S halmazból.
-
Si-re hamis negatív. Azt jelenti, hogy Si túl szűk, így Si-t az összes közvetlen általánosításával helyettesítjük, feltéve, hogy ezek szűkebbek, mint G egyes elemei.
-
Gi-re hamis pozitív. Azt jelenti, hogy Gi túl általános, így az összes közvetlen szűkítésével helyettesítjük, feltéve, hogy ezek általánosabbak, mint S egyes elemei.
-
Gi-re hamis negatív. Azt jelenti, hogy Gi túl szűk, de mivel nincs konzisztens általánosítása (definíciója értelmében), így Gi-t eltávolítjuk a G halmazból.
Ezeket a műveleteket minden új példára elvégezzük addig, amíg az alábbi három eset valamelyike fel nem lép:
-
Pontosan egy hipotézis marad a verziótérben, ebben az esetben ezt adjuk vissza mint az egyetlen hipotézist.
-
A verziótér összeomlik – vagy S, vagy G üressé válik, azt jelezve, hogy nincs a tanító halmazra nézve konzisztens hipotézis. Ez megegyezik az egyszerű döntési fa algoritmus sikertelen kimenetelével.
-
Kifogyunk a példákból, miközben számos hipotézis maradt a verziótérben. Ez azt jelenti, hogy a verziótér a hipotézisek diszjunkcióját reprezentálja. Ha egy új példa esetén a diszjunkció összes tagjában azonos eredményt kapunk, akkor ezt adhatjuk vissza mint a példa besorolását. Ha az eredmények nem egyeznek meg, akkor egyik lehetőségként alkalmazhatjuk a többségi szavazást.
Gyakorlás céljára hagyjuk a VERZIÓ-TÉR-TANULÁS algoritmusnak az éttermi adatokra való alkalmazását.
A verziótér megközelítésnek két alapvető hátránya van:
-
Ha a problématerület adatai zajt tartalmaznak, vagy ha az attribútumok a pontos besoroláshoz nem elégségesek, akkor a verziótér mindig összeomlik.
-
Ha korlátlan méretű diszjunkciót megengedünk a hipotézistérben, akkor az S halmaz mindig tartalmazni fog egy egyedi legszűkebb hipotézist, nevezetesen az összes eddig látott pozitív példa diszjunkcióját. Hasonlóképpen a G halmaz tartalmazni fogja a negatív példák diszjunkciójának negáltját.
-
Egyes hipotézistereknél az S- és a G-beli elemek száma az attribútumok számában exponenciálisan növekedhet annak ellenére, hogy az ilyen hipotézisterekhez ismertek hatékony tanuló algoritmusok.
A zaj problémájára napjainkig nem ismert teljes, sikeres megoldás. A diszjunktív kapcsolatok problémája kezelhető oly módon, hogy csak korlátozott méretű diszjunktív formákat engedünk meg, vagy az általánosabb predikátumokra egy általánosítási hierarchiát (generalization hierarchy) vezetünk be. Például a BecsültVárakozás(x, 30-60) ∨ BecsültVárakozás(x, >60) helyett használhatjuk a HosszúVárakozás(x) literált. Az általánosítási és a szűkítési műveletek egyszerűen kiterjeszthetők ennek kezelésére.
A verziótér algoritmus tiszta változatát először a Meta-DENDRAL rendszerben alkalmazták. Ezt a rendszert olyan szabályok megtanulására tervezték, amelyek azt írják le, hogy egy tömegspektrométerben a molekulák hogyan esnek szét darabokra (Buchanan és Mitchell, 1978). A Meta-DENDRAL képes volt olyan szabályok generálására, amelyek elég újak voltak egy analitikus kémiával foglalkozó újságban való publikálhatósághoz. Ezek voltak az első – egy számítógépes program által felfedezett – valós tudományos eredmények. Az algoritmust az elegáns LEX rendszerben (Mitchell és társai, 1983) szintén használták, ez a rendszer saját sikereinek és kudarcainak tanulmányozása alapján szimbolikus integrálási problémák megoldásának megtanulására volt képes. Bár a verziótér-módszerek valószínűleg a legtöbb valós probléma tanulása esetén – főleg a zaj miatt – nem praktikusak, jó betekintést adnak a hipotézistér logikai szerkezetébe.
[189] „Hamis pozitív” és „hamis negatív” kifejezéseket először a gyógyításban használták arra, hogy a téves laboratóriumi eredményeket jellemezzék. Egy eredmény akkor hamis pozitív, ha azt jelzi, hogy a páciens az adott betegségben szenved, míg valójában nem ez a helyzet.
