17.6. Többágenses döntések: a játékelmélet
Ez a fejezet a bizonytalan környezetbeli döntéshozatalra összpontosított. De mi a helyzet akkor, ha a bizonytalanság más ágenseknek és azok döntéseinek köszönhető? És ha ezeknek az ágenseknek a döntéseit a mi döntéseink befolyásolják? Ezzel a kérdéssel egyszer már foglalkoztunk, amikor a 6. fejezetben a játékokat tanulmányoztuk. Ott azonban többfordulós, teljes információs játékokkal foglalkoztunk, amelyekre a minimax kereséssel optimális lépések találhatók. Ebben az alfejezetben a játékelmélet (game theory) azon vonatkozásait tanulmányozzuk, amelyek felhasználhatók szimultán játékok elemzésére. Egyszerűsítés céljából elsőként olyan játékokat nézünk meg, amelyek csak egy lépés hosszúak. A „játék” szó és az egyetlen lépésre való korlátozás ezt triviálisnak tüntetheti fel, de valójában a játékelméletet nagyon komoly döntéshozatali helyzetekben használják – ideértve a bankcsődeljárásokat, a távközlési frekvenciasávok aukcióját, a termékfejlesztési és ármegállapítási döntéseket, illetve a honvédelmi kérdéseket – olyan helyzetekben, amelyek dollármilliárdok és életek százezreinek a sorsát érintik. A játékelmélet legalább kétféle módon használható fel:
-
Ágenstervezés (agent design): A játékelmélet képes elemezni az ágensek döntéseit, és kiszámítani az egyes döntések várható hasznosságát (azon feltevés mellett, hogy más ágensek a játékelmélet szerint optimálisan cselekednek). Például a kétujjas snóblijátékban (two-finger Morra) két játékos, O és E egyidejűleg felmutatja egy vagy két ujját. Legyen az ujjak összes száma f. Ha f páratlan, akkor O kap f dollárt E-től, és ha f páros, akkor E kap f dollárt O-tól. A játékelmélet képes meghatározni a legjobb stratégiát egy racionális ellenféllel szemben, és az egyes játékosok várható hasznát.[175]
-
Működési mód tervezés (mechanism design): Amikor a környezetet számos ágens népesíti be, előfordulhat, hogy a környezet szabályait (azaz a játékot, amit az ágenseknek játszaniuk kell) olyannak határozhatjuk meg, hogy az összes ágens együttes haszna akkor maximális, amikor mindegyik ágens egy saját hasznát maximáló játékelméleti megoldást követ. Például a játékelmélet segíthet olyan protokollok tervezésében az internetes forgalomirányítók számára, hogy minden irányítónak olyan ösztönzői legyenek, hogy a globális átvitel maximális legyen. A működési mód tervezés arra is felhasználható, hogy olyan intelligens többágenses rendszereket (multiagent systems) hozzunk létre, amelyek komplex problémákat elosztott módon oldanak meg, anélkül, hogy az egyes ágenseknek ismerniük kellene a megoldandó teljes problémát.
Egy játékot a játékelméletben a következő alkotóelemek definiálnak:
-
Játékosok (player) vagy ágensek, akik döntéseket hoznak. A legnagyobb figyelem a kétszemélyes játékokra irányult, bár az n személyes játékok n > 2-re szintén gyakoriak. A játékosokra nagybetűs neveket használunk, mint Aliz és Bendegúz vagy O és E.
-
Cselekvések (actions), amiket a játékosok választhatnak. A cselekvéseknek kisbetűs neveket választunk, mint az egy vagy a tanúskodik. Lehet, hogy a játékosok a cselekvéseknek ugyanazt a halmazát érik el, de az is lehet, hogy különbözőt.
-
Jutalommátrix (payoff matrix), ami az összes játékos cselekvéseinek mindegyik kombinációjára, mindegyik játékos számára megadja a hasznosságot. A jutalommátrix a kétujjas snóblijátékhoz a következő:
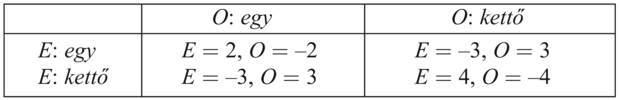
Például a jobb alsó sarokban az látható, amikor O a kettő cselekvést és E szintén a kettő cselekvést választja, a jutalom E-nek 4, O-nak pedig –4.
Minden játékosnak a játékban választania kell, és aztán végrehajtani egy stratégiát (strategy) (ami a 16. fejezetben szereplő eljárásmód elnevezése a játékelméletben). A tiszta stratégia (pure strategy) egy determinisztikus eljárásmód, ami mindegyik helyzethez előír egy végrehajtandó konkrét cselekvést; az egylépéses játékokban a tiszta stratégia csupán egyetlen cselekvés. A játékok elemzése vezetett el a kevert stratégiák (mixed strategy) gondolatához, amely eljárásmódban egy konkrét cselekvés véletlenszerűen kerül kiválasztásra egy adott eloszlásból a cselekvések felett. Azt a kevert stratégiát, ami p valószínűséggel az a cselekvést, egyébként pedig a b-t választja, úgy jelöljük, hogy [p: a; (1 – p): b]. Például a kétujjas snóblijátékban egy lehetséges kevert stratégia a [0,5: egy; 0,5: kettő]. A stratégiaprofil (strategy profil) egy hozzárendelés, ami mindegyik játékoshoz egy stratégiát rendel; adott stratégiaprofilnál a játék kimenetele (outcome) egy numerikus érték mindegyik játékoshoz.
Egy játék megoldása (solution) egy olyan stratégiaprofil, amiben minden játékos egy racionális stratégiát fogad el. Látni fogjuk, hogy a játékelméletben a legfontosabb kérdés a „racionális” jelentésének a definiálása akkor, amikor mindegyik ágens csak egy részét választja meg a kimenetelt meghatározó stratégiaprofilnak. Fontos azt felismerni, hogy a kimenetelek a játék egyes meneteinek a konkrét eredményei, míg a megoldások a játék elemzéséhez használt elméleti konstrukciók. Megmutatjuk, hogy bizonyos játékoknak csak a kevert stratégiák között van megoldása. Ez azonban nem jelenti azt, hogy egy játékosnak szó szerint egy kevert stratégiát kell elfogadnia a racionális viselkedéshez.
Gondoljuk át a következő történetet: két állítólagos betörőt, Alizt és Bendegúzt tetten érik egy betörés helyszínéhez közel, és a rendőrség külön-külön kihallgatja őket. Mindketten tudják, hogy ha mindketten beismerik a bűncselekményt, akkor 5 év börtönt kapnak betörésért, de ha mindketten tagadnak, akkor csak 1 évet kapnak lopott holmik birtoklásának enyhébb vádjával. Azonban a rendőrség külön-külön alkut ajánl mindkettőnek: ha a partneredről tanúsítod, hogy egy betörőbanda vezetője, akkor szabadon engednek, míg a partnered 10 évet kap. Ekkor Aliz és Bendegúz az úgynevezett fogolydilemmával (prisoner’s dilemma) szembesülnek: tanúskodniuk kell vagy tagadniuk? Racionális ágensként Aliz és Bendegúz is a saját várható hasznosságát akarja maximálni. Tegyük fel, hogy Alizt teljességgel hidegen hagyja partnerének a sorsa, így az ő hasznossága a saját börtönben töltött éveinek számával arányosan csökken, függetlenül attól, hogy mi történik Bendegúzzal. Bendegúz teljesen hasonlóan érez. A racionális döntés meghozatalához mindketten megalkotják a következő jutalommátrixot:
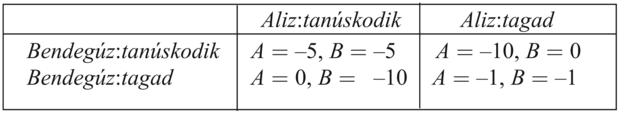
Aliz a következőképpen elemzi a jutalommátrixot: Tegyük fel, hogy Bendegúz tanúskodik. Ha tanúskodom, 5 évet kapok, és 10 évet, ha nem, ebben az esetben a tanúskodás jobb. Másrészről, ha Bendegúz tagad, akkor 0 évet kapok, ha tanúskodom, és 1 évet, ha tagadok, így a tanúskodás ebben az esetben is jobb. Így mindkét esetben számomra jobb tanúskodni, így ez az, amit tennem kell.
Aliz felfedezte, hogy a tanúskodás a játék domináns stratégiája (dominant strategy). Azt mondjuk, hogy egy p játékos egy s stratégiája erősen dominálja (strongly dominate) az s′ stratégiát, ha az s kimenetele p számára jobb, mint az s′ kimenetele, a többi játékos minden stratégiaválasztása esetén. Egy s stratégia gyengén dominálja (weakly dominates) s′-t, ha s jobb, mint s′ legalább egy stratégiaprofilnál, és nem rosszabb a többiben. Egy domináns stratégia olyan stratégia, ami az összes többit dominálja. Egy erősen dominált stratégiát irracionális követni, és ha létezik, irracionális eltérni a domináns stratégiától. Racionális volta miatt Aliz a domináns stratégiát választja. Már csak egy kevés terminológiára van szükségünk a továbbhaladáshoz: egy kimenetelt Pareto-optimálisnak (Pareto optimal) nevezünk,[176] ha nincs másik kimenetel, amit az összes játékos preferálna. Egy kimenetel Pareto-dominált (Pareto dominated) egy másik kimenetel által, ha az összes játékos a másik kimenetelt preferálná.
Ha Aliz okos és racionális, folytatni fogja az érvelést a következőképpen: Bendegúz domináns stratégiája szintén a tanúskodás. Így ő is tanúskodni fog, és mindketten 5 évet kapunk. Amikor mindegyik játékosnak van domináns stratégiája, ezek kombinációját domináns stratégiai egyensúlynak (dominant strategy equilibrium) nevezzük. Általában egy stratégiaprofil akkor van egyensúlyi helyzetben (equilibrium), ha egyik játékos sem nyer stratégiája váltásával, az összes többi játékos stratégiájának változatlansága mellett. Egy egyensúlyi helyzet lényegében egy lokális optimum (local optimum) az eljárásmódok terében: egy csúcs teteje lejtőkkel minden dimenzióban, ahol a dimenziók egy játékos stratégiai választásaihoz tartoznak.
A dilemma a fogolydilemmában az, hogy az egyensúlyi helyzet kimenetele mindkét játékosnak rosszabb, mint az a kimenetel, amit akkor érnének el, ha mindketten megtagadnák a tanúskodást. Másképpen fogalmazva, az egyensúlyi megoldás kimenete Pareto-dominált a (tagad, tagad)-nak a (–1, –1)-es kimenetelével.
Van-e módja Aliznak és Bendegúznak a (–1, –1)-es kimenetelt elérni? Az bizonyosan megengedett lehetőség mindkettőjüknek, hogy megtagadják a tanúskodást, de valószínűtlen lehetőség. Akármelyik játékos is kezdene elmélkedni azon, hogy a tagadást választja, felismeri, hogy jobban teszi, ha a tanúskodik. Az egyensúlyi helyzetnek ez a vonzereje.
Fontos
A matematikus John Nash (1928–) bebizonyította, hogy minden játéknak van egy itt definiált típusú egyensúlyi helyzete. Ezt a tiszteletére most már Nash-egyensúlynak nevezik. Nyilvánvaló, hogy egy domináns stratégiai egyensúly Nash-egyensúly (Nash equilibrium) (lásd 17.9. feladat), de nem minden játéknak vannak domináns stratégiái. Nash tétele azt mondja ki, hogy egyensúlyi stratégiák akkor is léteznek, ha nincs domináns stratégia.
A fogolydilemmánál csak a (tanúskodik, tanúskodik) stratégiaprofil Nash-egyensúlyi. Nehezen látható, hogy racionális játékosok hogyan tudják elkerülni ennek a kimenetelét, mivel bármely javasolt nem egyensúlyi megoldásnál legalább egy játékos kísértésben lenne, hogy változtasson a stratégiáján. Játékelméleti kutatók egyetértenek, hogy a Nash-egyensúly fennállása szükséges feltétel egy megoldás fennállásához – bár abban már nem értenek egyet, hogy ez elégséges feltétel-e.
A (tanúskodik, tanúskodik) megoldás könnyűszerrel elkerülhető, ha valamilyen módon megváltoztatjuk a játékot (vagy a játékosokat). Módosíthatjuk például egy olyan iterált játékra, amiben a játékosok tudják, hogy újra találkozni fognak (de az döntő, hogy bizonytalanok legyenek abban, hogy hányszor fognak még újra találkozni). Vagy ha az ágensek morális meggyőződése erősíti az együttműködést és az igazságosságot, megváltoztathatjuk a jutalommátrixot úgy, hogy tükrözze az egyes ágensek többiekkel való együttműködésének a hasznosságát. Később látni fogjuk, hogy az ágens olyatén megváltoztatása, hogy a számítási kapacitása korlátos, ahelyett hogy teljesen racionális következtetésre lenne képes, szintén befolyásolja a kimenetelt, mivel azt árulhatja el az egyik ágensnek, hogy a másik racionalitása korlátos.
Most nézzünk meg egy játékot, aminek nincs domináns stratégiája. Az Acme nevű videojáték-hardver gyártójának döntenie kell, hogy a következő játékgép DVD-ket vagy CD-ket használjon. Eközben a videojáték-szoftver gyártójának, Bestnek is döntenie kell, hogy DVD-n vagy CD-n adja ki a következő játékát. A nyereség mindkettőjüknek pozitív, ha egyetértenek, és negatív, ha eltérnek, ahogy a következő jutalommátrixból ez látható:

Fontos
Erre a játékra nincs domináns stratégiai egyensúly, de létezik két Nash-egyensúly: (dvd, dvd) és (cd, cd). Tudjuk, hogy ezek Nash-egyensúlyok, mivel akármelyik játékos is vált egyoldalúan egy különböző stratégiára, az rosszabbul fog állni. Most az ágenseknek a problémája a következő: több elfogadható megoldás is létezik, de ha az egyes ágensek különböző megoldást választanak, akkor a kiadódó stratégiaprofil egyáltalán nem lesz megoldás, és mindkét ágens veszteséget fog elszenvedni. Hogyan egyezhetnek meg egy megoldásban? Egy válasz erre, hogy mindkettőnek a Pareto-optimális megoldást kell választania (dvd, dvd); azaz leszűkíthetjük a „megoldás” definícióját az egyértelmű Pareto-optimális Nash-egyensúlyokra, feltéve, hogy létezik ilyen. Minden játéknak van legalább egy Pareto-optimális megoldása, de egy játéknak lehet több egyensúlyi pontja, de lehet, hogy ezek nem egyensúlyi pontok. Például beállíthatjuk a jutalmakat a (dvd, dvd)-nél 5-re 9 helyett. Ebben az esetben két egyenlő Pareto-optimális egyensúlyi pont létezik. A közöttük való választáshoz az ágensek vagy találgatnak, vagy kommunikálnak, ami vagy egy megállapodás kimondását jelenti, ami sorrendezi a megoldásokat a játék megkezdődése előtt, vagy tárgyalást jelent, hogy egy kölcsönösen előnyös megoldás alakuljon ki a játék folyamán (ami egy többlépéses játék részeként megjelenő kommunikációs cselekvések létét jelentené). A kommunikáció így pontosan ugyanazokból az okokból jelenik meg, mint a többágenses tervezésnél a 12. fejezetben. Az ilyen játékokat, ahol a játékosoknak szükséges kommunikálniuk, koordinációs játékoknak (coordination games) nevezzük.
Láttuk, hogy egy játéknak lehet több mint egy Nash-egyensúlya: honnan tudjuk, hogy minden játéknak van legalább egy? Az lehetséges, hogy egy játéknak nincs tiszta stratégiájú Nash-egyensúlya. Gondoljunk át például egy tetszőleges tiszta stratégiájú profilt a kétujjas snóblijátékhoz (17.6. szakasz - Többágenses döntések: a játékelmélet rész). Ha az ujjak összértéke páros, akkor O szeretne váltani; ha páratlan, akkor pedig E szeretne váltani. Így egy tiszta stratégiájú profil nem lehet egyensúlyi, és kevert stratégiákat kell megnéznünk.
De melyik kevert stratégiát? 1928-ban Neumann kifejlesztett egy módszert az optimális kevert stratégia megkeresésére kétszemélyes zérusösszegű játékokra. A zérusösszegű játék[177] (zero-sum game) olyan játék, amiben a jutalmak a jutalommátrix elemeiben nullára összegződnek. Világos, hogy a snóblijáték ilyen játék. A kétszemélyes zérusösszegű játékoknál tudjuk, hogy a jutalmak egyenlők és ellentétesek, így csak az egyik játékos jutalmait kell figyelembe vennünk, aki a maximáló lesz (ahogy a 6. fejezetben is). A snóblijátéknál az E páros játékost választjuk maximálónak, így a jutalommátrixot az UE(e, o) értékekkel definiálhatjuk – a jutalom E-nek, ha E e-t hajt végre és O o-t.
Neumann módszerét maximin technikának nevezik, és a következő módon működik:
-
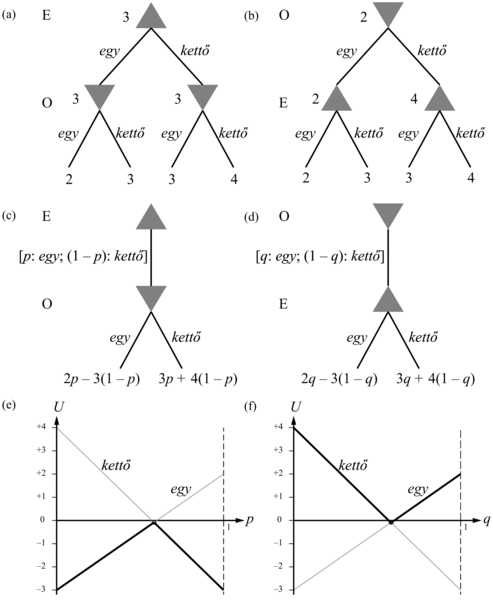
Tegyük fel, hogy úgy változtatjuk meg a szabályokat, hogy elsőként E-nek kötelező felfedni a stratégiáját, majd O következik. Így egy fordulókon alapuló játékot kapunk, amire a standard minimax algoritmust alkalmazhatjuk a 6. fejezetből. Tegyük fel, hogy ez egy UE,O kimenetelt ad. Nyilvánvaló, hogy ez a játék O-nak kedvez, így a játék igazi hasznossága (E szempontjából) legalább UE,O. Például ha csak tiszta stratégiákat nézünk, a minimax játékfának a gyökérbeli értéke –3 (lásd 17.11. (a) ábra), így tudjuk, hogy U ≥ –3.
-
Most tegyük fel, hogy a szabályokat úgy változtatjuk meg, hogy elsőként O-nak kötelező felfednie a stratégiáját, majd E következik. Ennek a játéknak a minimax értéke UE,O, és mivel ez a játék E-nek kedvez, tudjuk, hogy U legfeljebb UE,O. Tiszta stratégiáknál az érték +2 (lásd 17.11. (b) ábra), így tudjuk, hogy U ≤ +2.
Ezt a két érvelést összekapcsolva láthatjuk, hogy a megoldás valódi hasznossága (U) eleget fog tenni annak, hogy
UE,O ≤ U ≤ UO,E vagy ebben az esetben –3 ≤ U ≤ 2
Fontos
Az U értékének pontos megállapításához az elemzésünkben át kell térni a kevert stratégiákra. Elsőként vegyük észre a következőt: ha az első játékos felfedte a stratégiáját, a második nem veszthet azzal, hogy tiszta stratégiát követ. Az ok egyszerű: ha a második játékos egy [p: egy; (1 – p): kettő] kevert stratégiát játszik, akkor a várható hasznossága a tiszta stratégiák hasznosságainak, uegy-nek és ukettő-nek egy lineáris kombinációja, (p uegy + (1 – p) · ukettő). Ez a lineáris kombináció nem haladhatja meg az uegy és az ukettő közül a nagyobbat, így a második játékos is játszhat egy tiszta stratégiát.
Ezt az észrevételt emlékezetünkben tartva, a minimax fáknál képzelhetjük azt, hogy a gyökérnél végtelen sok ág van, amelyek az első játékos által választható végtelen sok kevert stratégiához tartoznak. Ezek mindegyike egy kettős elágazású csomóponthoz vezet, amelyek a második játékos tiszta stratégiáihoz tartoznak. Ezeket a végtelen fákat úgy ábrázoljuk véges módon, hogy a gyökérnél egy „parametrizált” választás van:
-
Ha E lép először, a helyzet a 17.11. (c) ábrán látható. E a gyökérnél [p: egy; (1 – p): kettő] szerint játszik, és O p értéke alapján választ egy lépést. Ha O egy-et választ, a várható jutalom (E-nek) 2p – 3(1 – p) = 5p – 3; ha O kettő-t választ, a várható jutalom –3p + 4(1 – p) = 4 – 7p. Ezeket a jutalmakat mint egyeneseket tüntethetjük fel a grafikonon, ahol p 0 és 1 között lehet az x tengelyen, ahogyan az a 17.11. (e) ábrán látható. O, a minimalizáló, mindig az alsót fogja választani a két egyenes közül, amit az ábrán a vastag egyenes jelez. Így a legjobb, amit E tehet a gyökérnél, hogy p-t a metszéspontnál választja meg, aminek értéke:
5p – 3 = 4 – 7p ⇒ p = 7/12
A hasznosság E számára ebben a pontban UE,O = –1/12.
-
Ha O lép először, a helyzet a 17.11. (d) ábrán látható. O a gyökérnél [q: egy; (1 – q): kettő] szerint játszik, és E a q értéke alapján választ egy lépést. A jutalmak 2q – 3(1 –q) = 5q – 3 és –3q + 4(1 – q) = 4 – 7q.[178] Ismét látható a 17.11. (f) ábrán, hogy a legjobb, amit O a gyökérnél tehet, hogy a metszéspontot választja:
5q – 3 = 4 – 7q ⇒ q = 7/12
A hasznosság E számára ebben a pontban UO,E = –1/12.
Most már tudjuk, hogy a játék valódi hasznossága –1/12 és –1/12 között helyezkedik el, azaz pontosan –1/12! (A tanulság az, hogy ebben a játékban jobb O-nak lenni, mint E-nek.) Továbbá, a valódi hasznosságot a [7/12: egy; 5/12: kettő] kevert stratégiával lehet elérni, amit mindkét játékosnak érdemes követnie. Ezt a stratégiát a játék maximin egyensúlyának nevezik (maximin equilibrium), és ez egy Nash-egyensúly. Vegyük észre, hogy az egyensúlyi kevert stratégia minden komponensének ugyanaz a várható hasznossága. Ebben az esetben mind az egy-nek, mind a kettő-nek ugyanaz a várható hasznossága, –1/12, mint magának a kevert stratégiának.
Fontos
A snóblijátékra vonatkozó eredményünk Neumann általános eredményének egy példája: minden kétszemélyes, zérusösszegű játéknak van egy maximin egyensúlya, amikor kevert stratégiák lehetségesek. Továbbá, egy zérusösszegű játékban minden Nash-egyensúly mindkét játékos számára egy maximin. A maximin egyensúly megtalálásának általános algoritmusa zérusösszegű játékokban kissé bonyolultabb, mint amit a 17.11. (e) és 17.11. (f) ábra sugallhatna. Ha n cselekvés lehetséges, akkor egy kevert stratégia egy pont az n dimenziós térben, és az egyenesek hipersíkok lesznek. Az is lehetséges, hogy a második játékos számára bizonyos tiszta stratégiák másokkal domináltak, így ezek nem optimálisak az első játékos egyetlen stratégiája ellen sem. Az összes ilyen stratégia eltávolítása után (amit lehet, hogy ismétlődően kell elvégezni), az optimális választás a gyökérnél a legmagasabb (vagy a legalacsonyabb) metszéspontja a megmaradt hipersíkoknak. Ennek a választásnak a megtalálása lineáris programozási feladat (linear programming): egy célfüggvény maximálása lineáris kényszerek mellett. Ilyen problémák szabványos technikákkal megoldhatók polinomiális időkomplexitással a cselekvések számában (és a jutalomfüggvény megadásához használt bitek számában, ha precízek akarunk lenni).
A kérdés továbbra is megválaszolatlan, mit kell egy racionális ágensnek konkrétan tennie ha a snóblijáték egy menetét játssza? A racionális ágens le fogja vezetni azt a tényt, hogy a [7/12: egy; 5/12: kettő] egy maximin egyensúlyi stratégia, azt fogja feltételezni, hogy egy racionális ellenfélnél ez a tudás kölcsönös. Az ágens használhat egy 12 oldalú kockát vagy egy véletlenszám generátort, hogy e szerint a kevert stratégia szerint sorsoljon, amely esetben a várható jutalom E számára –1/12. Vagy az ágens egyszerűen dönthet úgy, hogy mindig egy-et vagy kettő-t játszik. A várható jutalom bármely esetben –1/12 marad E számára. Érdekes, hogy egy konkrét cselekvés egyoldalú megválasztása nem veszélyezteti a várható jutalmat, de ha a másik ágnes számára ismertté válik egy ilyen egyoldalú döntés, az már befolyásolja a várható jutalmat, hiszen az ellenfél ennek megfelelően igazíthatja a stratégiáját.
17.11. ábra - (a) és (b): Minimax játékfák a kétujjas snóblijátékhoz, ha a játékosok a fordulókban tiszta stratégiát játszanak. (c) és (d): Parametrizált játékfák, ahol az első játékos kevert stratégiát játszik. A jutalmak függnek a kevert stratégia (p és q) valószínűségi paramétereitől. (e) és (f): A valószínűségi paraméter bármely konkrét értékénél a második játékos a két cselekvés közül a „jobbikat” fogja választani, így az első játékos kevert stratágiájának az értékét a vastag vonal jelöli. Az első játékos a kevert stratégia valószínűségi paraméterét a metszéspontnál fogja megválasztani.
A megoldások (azaz Nash-egyensúlyok) megtalálása nem zéró összegű véges játékokra kissé bonyolultabb. Az általános megközelítés kétlépéses: (1) Soroljuk fel a cselekvések összes lehetséges részhalmazát, amelyek kevert stratégiákat alkothatnak. Például elsőként próbálkozzunk az összes olyan stratégiaprofillal, amelyekben mindegyik játékos egyetlen cselekvést használ, aztán azokkal, amelyekben mindegyik játékos egy vagy két cselekvést használ és így tovább. Ez a cselekvések számában exponenciális, és így csak viszonylag kis játékoknál alkalmazható. (2) Minden (1)-ben felsorolt stratégiaprofilnál ellenőrizzük, hogy az egyensúlyi-e. Ez olyan egyenletek és egyenlőtlenségek egy rendszerének a megoldásával érhető el, amelyek hasonlók a zérusösszegű játékban használtakhoz. Két játékosra ezek az egyenletek lineárisak, és alapvető lineáris programozási technikákkal megoldhatók, de három vagy több játékosnál már nem-lineárisak, és esetleg nagyon nehezen oldhatók meg.
Eddig csak egylépéses játékokat vizsgáltunk. A legegyszerűbb többlépéses játék az ismétlődő játék (repeated game), amelyben a játékosok újra és újra ugyanazzal a választással szembesülnek, de az egyes alkalmakkor már ismert az összes játékos korábbi választásainak a története. Az ismétlődő játéknál egy stratégiaprofil egy cselekvésválasztást ad meg mindegyik játékos számára, minden időpontban és a korábbi választások minden lehetséges történetére. Ahogyan az MDF-eknél, a jutalmak az időben additívak.
Gondoljuk át a fogolydilemma ismétlődő változatát. Együtt fog-e működni Aliz és Bendegúz, visszautasítva a tanúskodást, azt tudva, hogy újra fognak találkozni? A válasz a találkozás részleteitől függ. Tegyük fel, hogy Aliz és Bendegúz tudja, hogy pontosan 100 menetben játszanak fogolydilemmásat. Ekkor mindketten tudják, hogy a 100. menet nem lesz ismételt játék – azaz, a kimenetelének nincs hatása jövőbeli menetekre –, és ezért ebben a menetben mindketten a domináns stratégiát, a tanúskodás-t választják. De a 100. menet meghatározásával a 99. menetnek nem lehet hatása következő menetekre, így ennek szintén lesz egy domináns stratégiai egyensúlya a (tanúskodik, tanúskodik)-nál. Indukcióval mindkét játékos a tanúskodást fogja választani minden menetben, fejenként összesen 500 év börtönt kapva. Eltérő megoldásokat nyerhetünk az interakció szabályainak a megváltoztatásával. Tegyük fel, hogy minden menet után 99% esélye van, hogy a játékosok újra találkoznak.
Ekkor a menetek várható száma még mindig 100, de egyik játékos sem tudja biztosan, hogy melyik menet lesz az utolsó. Ezen feltételek mellett együttműködőbb viselkedés lehetséges. Például a tagadás mindegyik játékosnak egyensúlyi stratégia mindaddig, amíg a másik játékos nem választ tanúskodás-t. Ezt a stratégiát örökös büntetésnek (perpetual punishment) nevezik. Tegyük fel, hogy mindkét játékos ezt a stratégiát fogadta el, és ez kölcsönösen ismert. Ekkor mindaddig, amíg egyik játékos sem választotta a tanúskodás-t, bármely időpontban a várható jövőbeli teljes jutalom mindegyik játékosnak
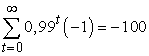
Az a játékos, aki a tanúskodás-t választja, egy 0 pontszámot nyer –1 helyett a soron következő lépésben, de a teljes várható jövőbeli jutalma a következőre változik:
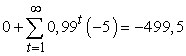
Ezért egyik lépésnél sincs indíték eltérni a (tagad, tagad)-tól. Az örökös büntetés a fogolydilemma egy „kölcsönösen biztosított megsemmisítési” stratégiája: alighogy az egyik játékos a tanúskodás mellett dönt, ez biztosítja, hogy mindkét játékos nagy veszteséget fog elszenvedni. De ez csak akkor elrettentő, ha a másik játékos elhiszi, hogy ezt a stratégiát fogadtuk el – vagy legalábbis hogy elfogadhattuk.
Vannak más stratégiák, amelyek megbocsátóbbak. A leghíresebb a „szemet szemért” (tit-for-tat), ami szerint tagadás-sal kell kezdeni, majd megismételni a másik játékos előző lépését az összes elkövetkező lépésben. Így Aliz tagadna, ameddig Bendegúz tagadna, és a Bendegúz tanúskodása utáni lépésben ő is tanúskodna, de visszatérne a tagadáshoz, ha Bendegúz visszatért. Bár nagyon egyszerű, ez a stratégia igen robusztusnak és hatékonynak bizonyult stratégiák széles köre ellen.
Különböző megoldásokat az ágensek megváltoztatásával is kaphatunk, a találkozás szabályainak változtatása helyett. Tegyük fel, hogy az ágensek véges állapotú gépek n állapottal, és egy m > n lépéses játékot játszanak. Az ágensek így nem képesek reprezentálni a hátramaradó lépések számát, így azt ismeretlenként kell kezelni. Így ők nem képesek az indukciós levezetésre, és lehetőségük van a kedvezőbb (tagad, tagad) esetet elérni. Ebben az esetben a tudatlanság áldás – vagy inkább az, hogy elhitessük az ellenféllel, hogy tudatlanok vagyunk. Ezekben az ismétlődő játékokban a sikerünk a másik játékos benyomásán múlik, hogy nyomulósok vagy mamlaszok vagyunk, és nem a valódi tulajdonságunkon.
Az ismétlődő játékok teljesen általános tárgyalása meghaladja a könyv kereteit, de számos helyzetben megjelennek. Például konstruálhatunk egy szekvenciális játékot, ha a 17.1. ábra 4 × 3-as világába két ágenst behelyezünk. Ha kikötjük, hogy nem következik be mozgás, amikor a két ágens ugyanarra a mezőre próbál lépni (ugyanaz a probléma számos forgalmi útkereszteződésben), akkor bizonyos tiszta stratégiák örökre beragadhatnak. Megoldás, ha mindegyik ágens véletlenszerűen választ az előrefelé lépés és a helyben maradás között; a holtpont gyorsan feloldódik, és mindkét ágens boldog lesz. Pontosan ezt teszik az Ethernet-hálózatokban a csomagütközés feloldására.
Az ismétlődő játékok jelenleg ismert megoldási módszerei a 6. fejezetből ismert többfordulós játékok megoldási módszereihez hasonlítanak abban, hogy egy játékfa építhető a gyökértől lefelé, és megoldható a levelektől felfelé. A fő különbség az, hogy egy gyerekcsomópont értékei feletti egyszerű maximum- vagy minimumképzés helyett az algoritmusnak minden szinten meg kell oldania egy kevert stratégiájú játékot, feltételezve, hogy a gyerekcsomópontok már megoldottak, és jól definiált értékük felhasználható.
Az ismétlődő játékokat részlegesen megfigyelhető környezetekben részleges információjú (partial information) játékoknak nevezik. A példák között találhatunk olyan kártyajátékokat, mint a póker és a bridzs, amelyekben mindegyik játékos a kártyáknak csak egy részét láthatja, de olyan komolyabb „játékokat” is, mint a nukleáris háborús modellek, ahol egyik fél sem ismeri az ellenfél összes fegyverének a helyzetét. Részleges információjú játékokat a hiedelmi állapotok fájának a vizsgálatával oldanak meg úgy, mint az RMMDF-ekben (lásd 17.4. alfejezet). Fontos különbség az, hogy míg a saját hiedelmi állapotok megfigyelhetők, addig az ellenfél hiedelmi állapotai nem. Ilyen játékokra csak mostanában fejlesztettek ki a gyakorlatban használható algoritmusokat. Megoldások születtek a póker bizonyos egyszerűbb változataira, bebizonyítva, hogy a blöffölés valóban racionális választás egy jól kiegyensúlyozott kevert stratégia részeként. Az ilyen tanulmányokból alakult ki az a lényeges meglátás, hogy a kevert stratégiák nemcsak azért hasznosak, mert valakinek a cselekvését megjósolhatatlanná teszik, hanem azért is, mert minimalizálják annak az információnak a mennyiségét, amit az ellenfél a cselekvések megfigyelésével tanulni képes. Érdekes, hogy annak ellenére, hogy a bridzs játszásához való programok tervezői nagyon is tisztában vannak az információ gyűjtésének és elrejtésének a fontosságával, senki sem javasolta véletlenszerű stratégiák használatát.
A játékelmélet felhasználásának az ágenstervezés szélesebb területén eddig számos akadálya volt. Elsőként vegyük észre, hogy egy Nash-egyensúlyban egy játékos teljes mértékben feltételezi azt, hogy az ellenfél egyensúlyi stratégiát játszik. Ez azt jelenti, hogy a játékos semmilyen elvárását sem képes felhasználni a többi játékos valószínű cselekvésével kapcsolatban, és így lehet, hogy olyan fenyegetések ellen való védekezésre vesztegeti el az értékeit, amelyek soha nem is lépnek fel. A Bayes–Nash-egyensúly (Bayes–Nash equilibrium) fogalma részben ezt a hiányosságot pótolja: ez egy olyan egyensúly, ami megfelel egy játékos a priori valószínűség-eloszlásának a többi játékos stratégiái felett – másképpen fogalmazva, kifejezi egy játékos elvárásait a többi játékos valószínű stratégiájáról. Másodszor, jelenleg nincs jó módszer a játékelméleti és az RMMDF irányítási stratégiák összekapcsolására. Ezek és más problémák miatt a játékelméletet elsődlegesen inkább olyan környezetek elemzésére használják, amelyek egyensúlyban vannak, a környezetben lévő ágensek irányítása helyett. Hamarosan látni fogjuk, hogy a játékelmélet hogyan segítheti a környezetek tervezését.
[175] A snóblijáték az ellenőrzési játék (inspection game) egy szabadidős változata. Ilyen játékokban az ellenőr megválaszt egy napot egy létesítmény (mint például egy vendéglő vagy egy biológiai fegyvergyár) ellenőrzésére, és a létesítmény működtetője szintén megválaszt egy napot, amikor az összes kellemetlen dolgot elrejti. Az ellenőr győz, ha a napok különböznek, és a létesítmény fenntartója, ha ugyanazok.
[176] A Pareto-optimalitás a közgazdász Vilfredo Paretóról (1848–1923) kapta nevét.
[177] Általánosabb az állandó összegű játékok (constant-sum games) fogalma, amelyekben a játékbeli minden elemnél az összeg egy c állandót ad. Egy n személyes állandó összegű játék egy zérusösszegű játékká konvertálható c/n kivonásával minden jutalomból. Így a sakk, a tradicionális jutalmakkal, mint 1 a győzelemért, ½ a döntetlenért és 0 a veszteségért, technikailag egy állandó összegű játék c = 1-gyel, de könnyen egy zérus- összegű játékká konvertálható, ha minden jutalomból kivonunk ½-et.
[178] Az egy egybeesés, hogy ezek az egyenletek ugyanazok, mint a p-re vonatkozók; az egybeesés amiatt lép fel, mert UE(egy, kettő) = UE(kettő, egy) = –3. Ez azt is megmagyarázza, hogy az optimális stratégia miért ugyanaz mindkét játékosnál.
