8.4. Tudástervezés az elsőrendű logikában
A megelőző alfejezet bemutatta az elsőrendű logika használatát a tudás reprezentálására három egyszerű tárgyterületben. Ez az alfejezet a tudásbázis felépítésének általános folyamatát írja le – egy folyamatot, amit tudástervezésnek (knowledge engineering) nevezünk. A tudásmérnök egy olyan személy, aki egy bizonyos tárgyterületet vizsgál, megismeri, hogy mely koncepciók fontosak abban a tárgyterületben, és megalkot egy formális reprezentációt a tárgyterületben található objektumokra és relációkra. A tudástervezés folyamatát az elektronikus áramkör tárgyterületében fogjuk illusztrálni, amely már valószínűleg ismerős, így koncentrálhatunk az ezzel járó reprezentációs problémákra. Az általunk alkalmazott megközelítés speciális célú tudásbázisok kialakításához megfelelő, amelyek tárgyterülete alaposan körülhatárolt, és amelyek lekérdezéseinek az egész sorozatát előre ismerjük. Általános célú tudásbázisokat, amelyeket arra használunk, hogy lekérdezéseket tegyenek lehetővé az emberi tudás teljes területére vonatkozóan, a 10. fejezetben tárgyaljuk majd meg.
A tudástervezési projektek különbözők tárgyukat, tárgykörüket és nehézségüket tekintve, de minden ilyen projekt tartalmazza a következő lépéseket:
-
A feladat beazonosítása. A tudásmérnöknek fel kell vázolnia a kérdések sorát, amelyekkel a tudásbázis foglalkozni fog, és a tényeknek azokat a csoportjait, amelyek minden egyes problémaspecifikus példányban megtalálhatók lesznek. El kell döntenie például, hogy a wumpus tudásbázisnak képesnek kell-e lennie a cselekvések kiválasztására, vagy hogy csak az várható el, hogy a környezet elemeivel kapcsolatos kérdéseket válaszolja meg. Tudnia kell, hogy az érzékelőktől származó tények leírják-e a jelenlegi helyzetet. A feladat határozza meg, hogy mely tudást kell tárolni, hogy a problémapéldányokban a válaszokat megadhassuk az adott esetre vonatkozóan. Ez a lépés analóg az ágensek tervezésénél látott TKBÉ-folyamattal, amelyről a 2. fejezetben írtunk.
-
A releváns tudás összegyűjtése. A tudásmérnök vagy már szakértője a tárgyterületnek, vagy együtt kell működnie igazi szakértőkkel, hogy megismerje az ő tudásukat – ezt a folyamatot tudásmegszerzésnek (knowledge acquisition) nevezzük. Ezen a szinten a tudást formálisan nem reprezentáljuk. A cél az, hogy megértsük a tudásbázis tárgykörét, amit a feladat határol be, és meg kell érteni azt is, hogy a tárgyterület hogyan működik a gyakorlatban.
A wumpus világban, amelyet mesterségesen létrehozott szabályrendszer határoz meg, könnyű az idevonatkozó tudásbázist azonosítani. (Vegyük észre azonban, hogy a szomszédosság definíciója nem volt explicit megadva a wumpus világ szabályaiban.) A valódi tárgyterületekben a relevancia problémája meglehetősen bonyolult lehet – például egy VLSI tervező szimulációs rendszernek figyelembe kell vennie a szórt kapacitásokat és a felületi hatásokat.
-
Meg kell határozni a predikátumok, függvények és konstansok szótárát. Ez azt jelenti, hogy a fontos tárgyterület szintű koncepciókat le kell fordítani logikai szintű nevekre. Ez számos, a megközelítés jellegét tárgyaló kérdést érint. Hasonlóan, mint a programozási stílusnak, ennek is jelentős hatása lehet a projekt végső sikerére. Például ilyen kérdés, hogy a csapdákat vajon objektumok jelenítsék-e meg vagy egy a négyzetekre vonatkozó unáris predikátum? Az ágens iránya függvény legyen-e vagy predikátum? A wumpus helyzete az időtől függjön-e? Mihelyt a választás megtörtént, az eredmény egy szótár, amit a tárgyterület ontológiájának (ontology) nevezzünk. Az ontológia fogalma egy olyan elméletet takar, ami a létezés természetét írja le. Meghatározza, hogy milyen dolgok léteznek, de nem határozza meg a rájuk jellemző tulajdonságokat, sem a köztük fennálló kapcsolatokat.
-
A tárgyterületről szóló általános tudás kódolása. A tudásmérnök leírja a szótár öszszes termjéhez tartozó axiómákat. Ez lerögzíti (amennyire lehetséges) a termek jelentését, és lehetővé teszi a szakértő számára a tartalom ellenőrzését. Ez a lépés gyakran feltárja a félreértelmezéseket vagy a hiányosságokat a szótárban, amelyeket a 3. lépéshez újra és újra visszatérve, iteratív eljárással javíthatunk.
-
Az adott probléma példány leírásának kódolása. Ha az ontológia jól átgondolt, ez a lépés már könnyű lesz. Egyszerű atomi mondatokat kell az ontológiában már leírt fogalmak példányaira megfogalmazni. Egy logikai ágens számára a problémapéldányokat az érzékelők biztosítják, amikor a „különálló” tudásbázist kiegészítik mondatokkal ugyanúgy, ahogy a hagyományos programoknak bemeneti adatokat adunk meg.
-
Lekérdezéseket fogalmazunk meg a következtetési folyamat számára és válaszokat vezetünk le. Itt kapjuk meg az eddigi munkánk jutalmát: működtethetjük a következtetési folyamatot az axiómákon és a problémaspecifikus tényeken, hogy megkapjuk a minket érdeklő tényeket.
-
Szűrjük ki a hibákat a tudásbázisból. Sajnos az első próbálkozásra a kérdésekre kapott válaszok nagyon ritkán lesznek helyesek. Pontosabban, a válaszok helyesek lesznek a megadott tudásbázis szempontjából, feltételezve, hogy a következtetési folyamat megfelelő, de a válaszok nem azok lesznek, amiket a felhasználó vár. Például ha hiányzik egy axióma, akkor bizonyos kérdések megválaszolhatatlanok lesznek a tudásbázis alapján. Ilyenkor egy hibajavítási folyamatra van szükség. A hiányzó vagy túl gyenge axiómák könnyen megtalálhatók úgy, hogy felfedezzük azokat a helyeket, ahol a következtetés lánca váratlanul megszakad. Például ha a tudásbázis tartalmazza az egyik, csapdákra vonatkozó diagnosztikus axiómát,
∀s Szellős(s) ⇒ ∃r Szomszédos(r, s) ∧ Csapda(r)
de nem tartalmazza a másikat, akkor az ágens soha nem lesz képes bizonyítani a csapdák hiányát. A helytelen axiómák azonosíthatók, mivel ezek hamis állítások a világról. Például az a mondat, hogy:
∀x LábakSzáma(x, 4) ⇒ Emlős(x)
hamis a hüllőkre, kétéltűekre vagy ami még fontosabb, az asztalokra nézve.
Fontos
Ennek a mondatnak a hamissága a tudásbázis többi részétől függetlenül meghatározható. Ezzel szemben egy tipikus programhiba ilyen:
eltolás = pozíció + 1
Nem lehet ez alapján megmondani, hogy a mondat helyes-e anélkül, hogy megnéznénk a program többi részét. Például azt, hogy az eltolás-t a jelenlegi pozícióra vonatkozóan használjuk-e, vagy arra, amely eggyel a jelenlegi pozíció mögött van, vagy arra, hogy a pozíció értéke megváltozott egy másik állítás által, és így az eltolás-t is meg kell változtatni.
Hogy jobban megértsük ezt a hétlépéses folyamatot, alkalmazzuk most egy kiterjesztett példára – az elektronikus áramkörök tárgyterületére.
8.4.2. Az elektronikus áramkörök tárgyterülete[84]
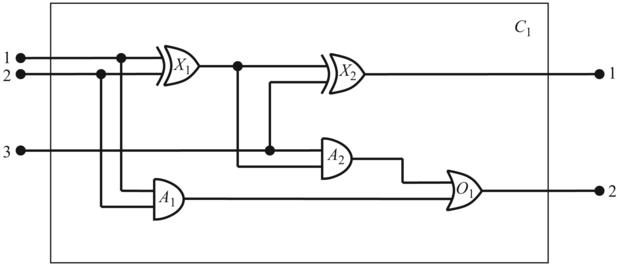
Létrehozunk egy ontológiát és egy tudásbázist, amelynek felhasználásával képesek leszünk következtetéseket végezni olyan típusú digitális áramkörökről, mint amilyet a 8.4. ábra mutat. A tudástervezés hétlépéses folyamatát fogjuk követni.
Számos következtetési feladatot lehet a digitális áramkörökkel kapcsolatban elvégezni. A legmagasabb szinten az áramkör funkcionalitását vizsgálhatjuk. Például szabályosan ad-e össze a 8.4. ábrán látható áramkör? Ha minden bemenet magas, akkor mi az A2 kapu kimenetének állapota? Az áramkör szerkezetéről feltett kérdések is érdekesek. Például melyek azok a kapuk, amelyek az első bemeneti ponthoz vannak kapcsolva? Tartalmaz-e az áramkör visszacsatolásokat? Ebben az alfejezetben ezeket a feladatokat vizsgáljuk meg. Léteznek az elemzésnek részletesebb szintjei is, például amelyek az időzítés késleltetésével, az áramkör területével, áramfogyasztásával, működtetési költségeivel és így tovább kapcsolatosak. Minden egyes ilyen szint vizsgálata további ismereteket igényel.
Mit tudunk a digitális áramkörökről? A céljainknak megfelelően azt, hogy vezetékekből és kapukból állnak. A jelek a vezetékeken keresztül áramlanak a kapuk bemeneti termináljához, és minden kapu egy jelet hoz létre a kimeneti terminálon, ami aztán egy másik vezetéken áramlik. Ahhoz, hogy meghatározzuk, melyek is ezek a jelek, ismernünk kell, hogy a kapuk hogyan alakítják át bemeneti jeleiket. Négyféle kaput használunk: az AND, az OR és a XOR kapuknak két bemenetük van, míg a NOT kapuknak csak egy. Minden kapunak egy kimenete van. Az áramköröknek, hasonlóan a kapukhoz, bemeneteik és kimeneteik is vannak.
Ahhoz, hogy következtetéseket végezhessünk a funkcionalitásról és az összeköttetésekről, nem szükséges magukról a vezetékekről vagy ezek útvonalairól, két vezeték találkozásánál levő kereszteződéseiről tudást megfogalmazni. Csak a be- és kimenetek közötti összeköttetések számítanak – tehát csak azt kell kimondani, hogy egy kimenet össze van-e kapcsolva egy másik bemenettel, anélkül hogy meg kellene említeni a vezetékeket, amik valójában összekötik őket. A tárgyterületnek sok más tényezője van, ami a mi vizsgálatunkban nem releváns. Ilyen például a különböző elemek mérete, formája, színe vagy ára.
8.4. ábra - Egy C1-es digitális áramkör, amelynek az a célja, hogy egy egybites teljes összeadást végezzen. Az első két bemenet az a két bit, amit össze kell adni, míg a harmadik bemenet az átvitel. Az első kimenet az összeg, míg a második kimenet az átvitel a következő összeadó felé. Az áramkör két XOR, két AND és egy OR kaput tartalmaz.
Ha a célunk valami más lenne, és nem a kapuszintű tervezés helyességének ellenőrzése, akkor az ontológiánk is más lenne. Például ha az érdekelne minket, hogyan lehetne a hibákat a hibás áramkörökben megtalálni, akkor valószínűleg jó ötlet lenne a vezetékekkel is foglalkozni az ontológiában, mivel egy hibás vezeték meghamisíthatja a rajta keresztülhaladó jelet. Az időzítési hibák megtalálásához a kapuk késleltetésével kapcsolatos fogalmakat kellene leírni. Ha az érdekelne minket, hogy hogyan lehet egy nyereséges terméket tervezni, akkor az áramkörök költségének és sebességének a piacon jelen lévő egyéb termékekkel történő összehasonlíthatósága lenne fontos.
Tudjuk, hogy áramkörökről, be- és kimenetekről, jelekről és kapukról akarunk beszélni. A következő lépés az ezeket reprezentáló függvények, predikátumok és konstansok kiválasztása. Az egyes kaputípusoktól fogunk indulni, és végül eljutunk az áramkörökig.
Először is meg kell tudnunk különböztetni egy kaput a többi kaputól. Ezt úgy érjük el, hogy konstansokat használunk a kapuk megnevezésére: X1, X2 és így tovább. Habár minden kapu a maga egyedi módján kapcsolódik az áramkörhöz, a viselkedése – vagyis az a mód, ahogyan átalakítja a bemeneti jeleket kimeneti jelekké – csakis a típusától függ. Egy kapu típusának jelölésére[85] egy függvényt használhatunk. Például írhatjuk, hogy Típus(X1) = XOR. Ez hozzárendeli az XOR konstanst egy bizonyos kaputípushoz. A többi konstans nevei: OR, AND és NOT lesznek. A Típus függvény nem az egyetlen lehetséges módja annak, hogy kódoljuk az ontológiai megkülönböztetést. Használhattunk volna egy bináris predikátumot is, mint a Típus(X1, XOR), vagy több egyargumentumú predikátumot, mint például az XOR(X1). Ezeknek a megoldásoknak bármelyike jól működne, de a Típus függvény választásával kiküszöböltük, hogy szükség legyen egy olyan axiómára, amely azt mondja ki, hogy minden egyes kapunak csak egyetlen típusa lehet.
Ezután megvizsgáljuk a végpontokat (be- és kimeneteket). Egy kapunak vagy áramkörnek egy vagy több bemenete, és egy vagy több kimenete lehet. Mindegyiket elnevezhetnénk egyszerűen egy konstanssal, mint ahogy azt a kapukkal tettük. Így az X1 kapunak olyan végpontjai lennének, mint az X1Be1, az X1Be2 és az X1Ki1. A hosszú, összetett elnevezéseket azonban célszerű kerülni. Az, hogy valamit X1Be1-nek nevezünk, nem jelenti azt, hogy ez az X1 első bemenete; még ekkor is hozzá kell tennünk valamit egy explicit állítást használva. Valószínűleg szerencsésebb egy függvénnyel leírni egy kaput, hasonlóan mint, ahogy János király bal lábát elneveztük BalLáb(János)-nak. Így tehát jelöljük az X1 kapu első bemenetét úgy, hogy: Be(1, X1). Egy hasonló Ki függvényt használunk a kimenetekre.
A kapuk közötti összeköttetést reprezentálhatjuk az Összekapcsolt predikátummal, ami két végpontot vesz argumentumként, például így: Összekapcsolt(Ki(1, X1), Be(1, X2)).
Végül, ismernünk kell, hogy egy jel magas vagy alacsony állapotban van-e. Erre egy lehetőség egy On bináris predikátum használata, és akkor igaz, ha a jel egy végponton magas értékű. Ez azonban egy kissé megnehezíti az olyan kérdések feltevését, mint például: „Mik a lehetséges értékei a C1 áramkör kimenetein lévő jeleknek?” Ezért be fogunk vezetni objektumokként két „jelértéket”, az 1-et és a 0-t, valamint egy Jel függvényt, aminek egy végpont az argumentuma, és ami kijelöli ennek a végpontnak a jelértékét.
Az egyik jele annak, hogy megfelelő ontológiát használunk az, hogy kevés olyan általános szabály van, amit később a példányokra specifikussá kellene tennünk. A helyes szótár jellemzője az, hogy minden egyes szabályt világosan és tömören meg tudunk fogalmazni. A mi példánkban csak hét egyszerű szabályra van szükségünk, hogy leírjunk mindent, amit tudnunk kell az áramkörökről.
-
Ha két végpont össze van kapcsolva, akkor ugyanaz lesz a jelértékük:
∀t1, t2 Összekapcsolt(t1, t2) ⇒ Jel(t1) = Jel(t2)
-
A jel minden végpontnál vagy 1, vagy 0 (de soha nem mindkettő):
∀t1 Jel(t) = 1 ∨ Jel(t) = 0
1 ≠ 0
-
Az Összekapcsolt egy felcserélhető (kommutatív) predikátum:
∀t1, t2 Összekapcsolt(t1, t2) ⇔ Összekapcsolt(t1, t2)
-
Egy OR kapu kimenete akkor és csak akkor 1, ha bármelyik bemenete 1:
∀g Típus(g) = OR ⇒
Jel(Ki(1, g)) = 1 ⇔ ∃n Jel(Be(n, g)) = 1
-
Egy AND kapu kimenete akkor és csakis akkor 0, ha bármelyik bemenete 0:
∀g Típus(g) = AND ⇒
Jel(Ki(1, g)) = 0 ⇔ ∃n Jel(Be(n, g)) = 0
-
Egy XOR kapu kimenete akkor és csakis akkor 1, ha a bemenetei különbözők:
∀g Típus(g) = XOR ⇒
Jel(Ki(1, g)) = 1 ⇔ Jel(Be(1, g) ≠ Jel(Be(2, g))
-
Egy NOT kapu kimenete különbözik a bemenetétől:
∀g (Típus(g) = NOT) ⇒ Jel(Ki(1, g)) ≠ Jel(Be(1, g))
A 8.4. ábrán bemutatott áramkör neve C1 és az itt következő leírással adjuk meg. Először kategorizáljuk a kapukat:
Típus(X1) = XOR Típus(X2) = XOR
Típus(A1) = AND Típus(A2) = AND
Típus(O1) = OR
Ezután leírjuk a köztük fennálló kapcsolatokat:
Összekapcsolt(Ki(1, X1), Be(1, X2)) Összekapcsolt(Be(1, C1), Be(1, X1))
Összekapcsolt(Ki(1, X1), Be(2, A2)) Összekapcsolt(Be(1, C1), Be(1, A1))
Összekapcsolt(Ki(1, A2), Be(1, O1)) Összekapcsolt(Be(2, C1), Be(2, X1))
Összekapcsolt(Ki(1, A1), Be(2, O1)) Összekapcsolt(Be(2, C1), Be(2, A1))
Összekapcsolt(Ki(1, X2), Ki(1, C1)) Összekapcsolt(Be(3, C1), Be(2, X2))
Összekapcsolt(Ki(1, O1), Ki(2, C1)) Összekapcsolt(Be(3, C1), Be(1, A2))
Milyen bemeneti kombinációk esetében lenne a C1 első kimenete (az összegelem) 0 és a C1 második kimenete (a maradék elem) 1?
∃i1, i2, i3 Jel(Be(1, C1)) = i1 ∧ Jel(Be(2, C1)) = i2 ∧ Jel(Be(3, C1)) = i3
∧ Jel(Ki(1, C1)) = 0 ∧ Jel(Ki(2, C1)) = 1
A válaszok az i1, i2 és i3 változók behelyettesítései úgy, hogy a keletkezett mondat következzen a tudásbázisból. Három ilyen behelyettesítés létezik:
{i1/1, i2/1, i3/0} {i1/1, i2/0, i3/1} {i1/0, i2/1, i3/1}
Melyek a az összeadó áramkör összes végpontjának lehetséges értékhalmazai?
∃i1, i2, i3, o1, o2 Jel(Be(1, C1)) = i1 ∧ Jel(Be(2, C1)) = i2
∧ Jel(Be(3, C1)) = i3 ∧ Jel(Ki(1, C1)) = o1 ∧ Jel(Ki(2, C1)) = o2
Ez az utolsó lekérdezés egy teljes bemenet-kimenet táblázatot ad meg az eszközre, amelyet aztán ellenőrizhetünk, hogy valóban helyesen adja-e össze a bemeneteket. Ez egy egyszerű példa az áramkör ellenőrzésére (circuit verification). Az áramkör bemutatott definícióját nagyobb digitális rendszerek építésére is felhasználhatjuk, amelyekre aztán ugyanez a fajta ellenőrzési folyamat alkalmazható (lásd 8.17. feladat). Sok tárgyterület kezelhető egy ehhez hasonló strukturált tudásbázis-fejlesztéssel, amelyekben összetettebb koncepciókat határozunk meg egyszerűbb koncepciókra építve.
Sokféleképpen perturbálhatjuk a tudásbázist, hogy meglássuk, milyen fajta hibás viselkedések fordulhatnak elő. Például tételezzük fel, hogy kihagyjuk az 1 ≠ 0[86] állítást. A rendszer ebben a pillanatban már nem lesz képes semmilyen kimenetet sem produkálni az áramkörben, kivéve, ha a bemenet a 000 vagy az 110. Rábukkanhatunk a problémára, ha minden egyes kapu kimenetére rákérdezünk. Például, megkérdezhetjük:
∃i1, i2, o Jel(Be(1, C1)) = i1 ∧ Jel(Be(2, C1)) = i2 ∧ Jel(Ki(1, X1))
ami felfedi, hogy az X1-nél nem ismerjük a kimenetet az 10 és a 01 bemenetek esetén. Ezután megnézzük az XOR kapu axiómáit az X1-re alkalmazva:
Jel(Ki(1, X1)) = 1 ⇔ Jel(Be(1, X1)) ≠ Jel(Be(2, X1))
Ha tudjuk, hogy a bemenetek, mondjuk, 1 és 0 voltak, akkor ezt lerövidíthetjük így:
Jel(Ki(1, X1)) = 1 ⇔ 1 ≠ 0
Most már látható, hogy mi a probléma oka: a rendszer nem képes kikövetkeztetni azt, hogy Jel(Ki(1, X1)) = 1, így meg kell neki mondanunk, hogy 1 ≠ 0.
[84] Ez az alfejezet a digitális áramkörök meglehetősen sajátos bemutatására vállalkozik. Miközben nem javasoljuk, hogy valaki ez alapján ismerkedjen meg a digitális áramkörökkel, és esetleg az itt bemutatottak alapján próbáljon digitális áramköröket tervezni, az itt leírtak mindenképpen érdekes nézőpontot tükröznek, és érdekes kísérletet jelentenek arra, hogy az elsőrendű logika fogalomkészletével mutassák be a digitális áramköröket. (A szerk.)
[85] Vegyük észre, hogy megfelelő betűkkel kezdődő neveket használtunk – A1, X1 és így tovább – pusztán azért, hogy könnyebben olvashatóvá tegyük a példát. A tudásbázisnak még így is tartalmaznia kell a kapuk típusára vonatkozó információkat.
[86] Ez a fajta kihagyás eléggé gyakori, mert az emberek általában feltételezik, hogy a különböző nevek különböző dolgokat takarnak. A logikai programozási rendszerek, amelyeket bővebben a 9. fejezetben mutatunk be, szintén megteszik ezt a feltételezést.
