7.5. Az ítéletkalkulus következtetési mintái
Ez az alfejezet végigveszi a következtetés standard mintáit, amelyek alkalmazhatók arra, hogy következmények láncolatait vezethessük le, amelyek elvezetnek a kívánt célhoz. Ezeket a következtetési mintákat következtetési szabályoknak (inference rules) hívjuk. A legjobban ismert szabály a Modus Ponens és a következőképpen írható le:
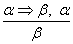
A jelölés azt jelenti, hogy ha bármikor adott egy α ⇒ β formájú mondat és adott egy α, akkor a β mondat ebből következik. Például a (WumpusElőrefelé ∧ WumpusÉl) ⇒ Lövés és a (WumpusElőrefelé ∧ WumpusÉl) adott, akkor a Lövés kikövetkeztethető.
Egy másik hasznos következtetési szabály az És-kiküszöbölés (And-Elimination), ami azt mondja ki, hogy egy konjunkcióból bármely konjunkt kikövetkeztethető:
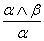
Például abból, hogy (WumpusElőrefelé ∧ WumpusÉl) a WumpusÉl kikövetkeztethető.
Tekintettel az α és β lehetséges igazságértékeire, könnyen megmutatható, hogy a Modus Ponens és az És-kiküszöbölés helyes egyszer és mindenkorra. Ezek a szabályok felhasználhatók bármely konkrét esetben, ahol alkalmazhatók, helyes következtetéseket eredményezve anélkül, hogy fel kellett volna sorolnunk a modelleket.
A 7.11. ábrán található összes logikai ekvivalencia használható következtetési szabályként. Például az ekvivalencia kiküszöbölés két következtetési szabályt eredményez:
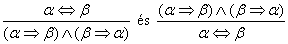
Nem minden következtetési szabály működik mindkét irányban, mint ezek. Például nem futtathatjuk a Modus Ponenst ellenkező irányban, hogy megkapjuk α ⇒ β-t és α-t a β-ból.
Nézzük meg, hogyan használhatjuk ezeket a következtetési szabályokat és ekvivalenciákat a wumpus világban. Az Sz1, ..., Sz5 szabályokból álló tudásbázisból indulunk ki, és megmutatjuk, hogy hogyan bizonyíthatjuk a ¬C1,2-t azaz, hogy nincs csapda az [1, 2]-ben. Először alkalmazzuk az ekvivalencia kiküszöbölést Sz2-re, és így kapjuk, hogy
Sz6: (S1,1 ⇒ (C1,2 ∨ C2,1)) ∧ ((C1,2 ∨ C2,1) ⇒ S1,1)
Ezután alkalmazzuk az És-kiküszöbölést az Sz6-ra, és így kapjuk, hogy
Sz7: ((C1,2 ∨ C2,1) ⇒ S1,1)
A kontrapozíció logikai ekvivalenciát alkalmazva:
Sz8: (¬S1,1 ⇒ ¬(C1,2 ∨ C2,1))
Most alkalmazhatjuk a Modus Ponenst az Sz8-ra és az Sz4 érzetre (például a ←S1,1) és így kapjuk:
Sz9: ¬(C1,2 ∨ C2,1)
Végül alkalmazzuk a De Morgan-szabályt, amely a konklúziót adja:
Sz10: ¬C1,2 ∧ ¬C2,1
Tehát sem az [1, 2], sem a [2, 1] négyzet nem tartalmaz csapdát.
Az előző levezetést – következtetési szabályok egy sorozatát – bizonyításnak (proof) nevezzük. A bizonyítás megtalálása pontosan olyan, mint megoldást találni egy keresési problémára. Valójában ha a következtetési szabályok összes lehetséges alkalmazásának generálására egy új állapotátmenet-függvényt definiálnánk, akkor minden, a 3. és 4. fejezetbeli kereső algoritmust felhasználhatnánk a bizonyítás megtalálására. A bizonyítás keresése tehát egy alternatívája a modellek felsorolásának. A keresés haladhat előrefelé a kezdeti tudásbázisból kiindulva, alkalmazva a következtetési szabályokat a célmondat levezetéséhez, vagy mehet visszafelé a célmondatból, megpróbálva megtalálni a következtetési szabályoknak olyan láncolatát, amely a kiindulási tudásbázisra alkalmazható szabályokból indul. A fejezetben később bemutatunk két olyan algoritmuscsaládot, amelyek ezeket a technikákat használják.
Fontos
Az a tény, hogy a következtetés az ítéletlogikában NP-teljes, azt sugallja, hogy a legrosszabb esetet tekintve a bizonyítások keresése sem hatékonyabb a modellek felsorolásánál. Számos gyakorlati esetben azonban, α bizonyítás megtalálása sokkal hatékonyabb lehet, egyszerűen azért, mert képes figyelmen kívül hagyni az irreleváns állításokat, függetlenül attól, hogy hány van belőlük. Például az előző bizonyítás, amely elvezetett a ¬C1,2 ∧ ¬C2,1 mondathoz, nem említi az S2,1, C1,1, C2,2 vagy a C1,2 állításokat. Ezeket azért lehet figyelmen kívül hagyni, mert a C1,2 célállítás csak az Sz2-ben jelenik meg, az Sz2-ben szereplő egyéb állítások pedig csak az Sz2-ben és az Sz4-ben, így az Sz1, Sz3 és Sz5 szabályoknak nincs kihatásuk a bizonyításra. Ugyanez maradna a helyzet, ha még millió szabályt hozzáadnánk a tudásbázishoz, miközben az igazságtábla algoritmust ezzel ellentétben elárasztaná a modellek exponenciális robbanása.
A logikai rendszereknek ez a tulajdonsága valójában egy sokkal alapvetőbb jellegzetességükből, a monotonitásból (monotonicity) következik. A monotonitás azt mondja ki, hogy a vonzatmondatok halmaza csak bővülhet, ha a tudásbázishoz információt adunk hozzá.[69]
ha TB ⊨ α akkor TB ∧ β ⊨ α
Például feltételezzük azt, hogy a tudásbázis tartalmaz egy új β állítást, amely azt mondja ki, hogy pontosan 8 csapda van a világban. Ez a tudás segítheti az ágenst további konklúziók levezetésében, de nem teheti érvénytelenné egyik korábban kikövetkeztetett α konklúziót sem – így azt a konklúziót sem, hogy nincsen csapda az [1, 2]-ben. A monotonitás azt jelenti, hogy a következtetési szabályok bármikor alkalmazhatók, ha a megfelelő premisszák megtalálhatók a tudásbázisban – a szabály konklúziójának következnie kell, függetlenül attól, hogy mi más is van még a tudásbázisban.
Megmutattuk, hogy az eddig ismertetett következtetési szabályok helyesek, de nem tárgyaltuk az ezeket használó következtetési algoritmusok teljességének kérdését. A keresési algoritmusok, mint az iteratívan mélyülő keresés 3.4.5. szakasz - Iteratívan mélyülő mélységi keresés részben teljesek abban az értelemben, hogy meg fogják találni az elérendő célt. Ha azonban a rendelkezésre álló szabályok hiányosak, akkor a cél nem érhető el – nem létezik olyan bizonyítás, amely ezeket a szabályokat használja. Például ha kivennénk az ekvivalencia kiküszöbölés szabályt, az előző fejezetbeli bizonyítás nem futna végig. Ez a fejezet egyetlen következtetési szabályt mutat be, a rezolúciót (resolution), amelynek alkalmazása, párosítva bármelyik keresési módszerrel, egy teljes következtetési algoritmust eredményez.
Először a rezolúciós szabály egy egyszerű változatát fogjuk használni a wumpus világban. Nézzük meg a 7.4. (a) ábrához vezető lépéseket: az ágens visszafordul a [2, 1]-ből az [1, 1]-be, és innen megy az [1, 2]-be, ahol szellőt érez, de bűzt nem. A következő tényeket adjuk hozzá a tudásbázishoz:
Sz11: ¬S1,2
Sz12: S1,2 ⇔ (C1,1 ∨ C2,2 ∨ C1,3)
Ugyanazzal a folyamattal, amely az Sz10-hez vezetett korábban, most le tudjuk vezetni, hogy nincs csapda a [2, 2]-ben és az [1, 3]-ban (emlékezzünk, hogy már tudjuk, hogy az [1, 1] csapdamentes):
Sz13: ¬C2,2
Sz14: ¬C1,3
Az Sz3-ra is alkalmazhatjuk az ekvivalencia kiküszöbölést, amelyet egy Modus Ponens követ az Sz5-re, hogy megkapjuk azt a tényt, hogy csapda van az [1, 1], a [2, 2] vagy a [3, 1] négyzetekben:
Sz15: C1,1 ∨ C2,2 ∨ C3,1
Most következik a rezolúció szabály első alkalmazása: a ¬C2,2 literál az Sz13-ban rezolvál a C2,2 literállal az Sz15-ben, amely ezt adja:
Sz16: C1,1 ∨ C3,1
Magyarul, ha van egy csapda az [1, 1], [2, 2], [3, 1] négyzetek egyikében, és ez a csapda nem a [2, 2]-ben van, akkor ez az [1, 1]-ben vagy a [3, 1]-ben van. Hasonlóan a ¬C1,1 literál az Sz1-ben rezolvál a C1,1 literállal az Sz16-ban, amiből adódik:
Sz17: C3,1
Tehát, ha van egy csapda az [1, 1]-ben vagy a [3, 1]-ben, és ez a csapda nem az [1, 1]-ben van, akkor ez a [3, 1]-ben van. Ez az utolsó két következtetési lépés példa az egységrezolúció (unit resolution) következtetési szabályra,
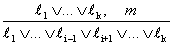
ahol ℓ egy literál, ℓi és m pedig kiegészítő literálok (complementary literals) (például az egyik negáltja a másiknak). Tehát az egységrezolúció vesz egy klózt (clause) – literálok diszjunkcióját – meg egy literált, és létrehoz egy új klózt. Vegyük észre, hogy egy egyedi literált tekinthetünk egy literál diszjunkciójának, amit szoktak egységklóznak (unit clause) is nevezni.
Az egységrezolúció szabálya általánosítható teljes rezolúciós (resolution) szabállyá,
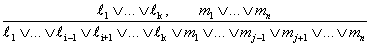
ahol ℓi és mj kiegészítő literálok. Ha csak kettő hosszúságú klózokkal foglalkozunk, akkor ezt írhatjuk:
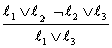
Azaz a rezolúció vesz két klózt, és létrehoz egy új klózt, amely tartalmaz minden literált az eredeti két klózból, kivéve a kiegészítő literálokat. Például:
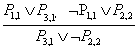
Van még egy technikai aspektusa a rezolúciós szabálynak: az eredményklóznak minden literálnak csak egy példányát kell tartalmaznia.[70] A literálok többszörös példányainak kivonását faktorálás (factoring) hívják. Például ha rezolváljuk az (A ∨ B)-t a (A ∨ ¬B)-vel, akkor (A ∨ A)-t kapunk, amelyet redukálhatunk egyszerűen A-ra.
A rezolúciós szabály helyessége egyszerűen belátható, ha megvizsgáljuk az li literált. Ha li igaz, akkor mj hamis, és így m1 ∨…∨ mj–l ∨ mj+l ∨…∨ mn-nek igaznak kell lennie, mert m1 ∨…∨ mn adott. Ha ℓi hamis, akkor ℓ1 ∨…∨ ℓi–l ∨ ℓi+l ∨…∨ ℓk igaz kell, hogy legyen, mivel ℓi ∨…∨ ℓk adott. Így ℓi akár igaz, akár hamis, az egyik vagy a másik konklúzió áll, pontosan úgy, ahogy a szabály ezt kimondja.
Fontos
Ami még meglepőbb a rezolúciós szabállyal kapcsolatban, hogy a rezolúció alapjául szolgál teljes következtetési algoritmusok egy családjának. Bármely keresési algoritmus, a rezolúciós szabályt alkalmazva, az ítéletlogikában képes levezetni bármilyen konklúziót, amely vonzata a tudásbázisnak. Egy figyelmeztetés: a rezolúció csak egy speciális értelemben teljes. Ha adott, hogy A igaz, akkor nem tudjuk a rezolúciót arra használni, hogy levezessük az A ∨ B konzekvenciát. Azonban tudjuk arra használni a rezolúciót, hogy megválaszoljuk azt a kérdést, hogy A ∨ B igaz-e. Ezt megcáfolási teljességnek (refutation completeness) nevezik, ami azt jelenti, hogy a rezolúció mindig használható arra, hogy megerősítsünk vagy megcáfoljunk egy mondatot, de nem alkalmazható az igaz mondatok felsorolására. A következő két alfejezet azt magyarázza el, hogy a rezolúció hogyan oldja ezt meg.
Fontos
A rezolúciós szabály csak literálok diszjunkcióira alkalmazható, így úgy tűnhet, hogy ez csak olyan tudásbázis és lekérdezés esetében érdekes, amelyek ilyen diszjunkciókat tartalmaznak. Akkor hogyan vezet ez egy teljes következtetési eljáráshoz az egész ítéletkalkulus számára? A válasz az, hogy minden ítéletkalkulus mondat logikailag ekvivalens literálok diszjunkcióinak konjunkcióival. Egy mondatot, amelyet literálok diszjunkcióinak konjunkcióival fejezünk ki, konjunktív normál formájúnak (conjunctive normal form) vagy CNF formájúnak nevezünk. A későbbiekben az is hasznos lesz, ha ennek egy korlátosabb családját, a k-CNF mondatokat tekintjük. Egy mondat a k-CNF-be tartozik, ha pontosan k literál van a klózokban.
(ℓ l, l ∨…∨ ℓ 1, k) ∧…∧ ( ℓ n, l ∨…∨ ℓ n, k)
Ki fog derülni, hogy minden mondat transzformálható 3-CNF mondattá úgy, hogy azonos marad a modellek halmaza.
Ahelyett hogy bizonyítanánk ezeket a kijelentéseket (lásd 7.10. feladat), leírunk egy egyszerű konvertáló eljárást. Az eljárást az Sz2 szabály, az S1,1 ⇔ (C1,2 ∨ C2,1) mondat CNF-re konvertálásával illusztráljuk. A lépések a következők:
-
Küszöböljük ki a ⇔ összekötőjelet, helyettesítve az α ⇔ β-t (α ⇒ β) ∧ (β⇒ α)-vel:
(S1,1 ⇒ (C1,2 ∨ C2,1)) ∧ ((C1,2 ∨ C2,1) ⇒ S1,1)
-
Kiküszöböljük az ⇒ összekötőjelet, kicserélve α⇒ βt ¬α ∨ β-ra:
(¬S1,1 ∨ C1,2 ∨ C2,1) ∧ (¬ (C1,2 ∨ C2,1) ∨ S1,1)
-
A CNF megkívánja, hogy a ¬ csak literálokra vonatkozzon, így most „a-t beljebb mozgatjuk” a következő 7.11. ábrán felírt ekvivalenciák ismételt alkalmazásával:
¬(¬α) ≡ β kettős negáció kiküszöbölés
¬(α ∧ β) ≡ (¬α ∨ ¬β) De Morgan
¬(α ∨ β) ≡ (¬α ∧ ¬β ) De Morgan
A példában csak az utolsó szabály alkalmazására van szükségünk:
(¬ S1,1 ∨ C1,2 ∨ C2,1) ∧ ((¬C1,2 ∧ ¬C2,1) ∨ S1,1)
-
Most van egy mondatunk, amelyben egymásba ágyazott ∧ és ∨ operátorok vannak alkalmazva a literálokra. A 7.11. ábrán bevezetett disztributivitás szabályt alkalmazzuk a ∨ operátorokra az ∧ felett mindenhol, ahol lehetséges.
(¬S1,1 ∨ C1,2 ∨ C2,1) ∧ (¬C1,2 ∨ S1,1) ∧ (¬C2,1 ∨ S1,1)
Az eredeti mondat most már CNF-ben van, három klóz konjunkciójaként. Bár sokkal nehezebb olvasni ezt a formát, de használható a rezolúciós eljárás bemeneteként.
A rezolúción alapuló következtetési eljárások az ellentmondásokra vezető bizonyítások elvén működnek, ahogy azt a 7.4. alfejezet végén tárgyaltuk. Tehát annak megmutatásához, hogy ΤΒ ⊨ α, azt mutatjuk meg, hogy a (TB ∧ ¬α) kielégíthetetlen. Ezt az ellentmondás bizonyításával végezzük el.
A rezolúció algoritmust mutatja a 7.12. ábra. Először a (TB ∧ ¬α)-t konvertáljuk CNF formára. Majd a rezolúciós szabályt alkalmazzuk a létrejövő klózokra. Minden egyes párt, amely kiegészítő literálokat tartalmaz, rezolválunk, hogy egy új klózt hozzunk létre, amelyet hozzáadunk a halmazhoz, ha még nem volt jelen. A folyamat addig folytatódik, amíg a következő két dolog közül valamelyik meg nem történik:
-
nincs több új klóz, amit hozzá lehet adni, ilyen esetben α nem vonzza maga után β-t.
-
a rezolúció alkalmazása egy üres klózra vezet, amely esetben α -nak vonzata β .
Az üres klóz – egy diszjunkt nélküli diszjunkció – ekvivalens a Hamis értékkel, mert a diszjunkció akkor igaz csak, ha legalább az egyik diszjunkt igaz. ∨gy is beláthatjuk, hogy az üres klóz ellentmondást reprezentál, hogy megfigyeljük azt, hogy az üres klóz két kiegészítő egységklóz, mint amilyen az S és ¬S, rezolválásából származik.
7.12. ábra - Egy egyszerű rezolúciós algoritmus az ítéletkalkulushoz. Az IK-
REZOLVÁLÁS a két bemenetként megkapott állítás rezolválásából származó összes lehetséges klóz halmazát adja vissza.
Alkalmazzuk a rezolúciós eljárást egy nagyon egyszerű következtetésre a wumpus világban. Amikor az ágens az [1,1]-ben van, akkor nincs szellő, tehát nincs csapda a szomszédos négyzetekben. Az ennek megfelelő tudásbázis:
TB = Sz2 ∧ Sz4 = (S1,1 ⇔ (C1,2 ∨ C2,1)) ∧ ¬S1,1
és mi bizonyítani szeretnénk α-t, ami mondjuk ¬C1,2. Amikor konvertáljuk a (TB ∧ ¬α)-t CNF formára, akkor a 7.13. ábra felső részén látható klózokat kapjuk. Az ábra második sora mutatja az összes klózt, amit az első sor párjainak rezolválásából kaptunk. És akkor, amikor a C1,2-t rezolváljuk ¬C1,2-vel megkapjuk az üres klózt, amit egy kis négyzet jelöl. A 7.13. ábra megvizsgálása azt mutatja, hogy számos rezolúciós lépés felesleges. Például az S1,1 ∨ ¬S1,1 ∨ C1,2 ekvivalens az Igaz ∨ C1,2-vel, ami ekvivalens az Igazzal. Levezetni, hogy az Igaz az igaz, nem igazán hasznos. Így bármely olyan klóz, amelyben két kiegészítő klóz szerepel, figyelmen kívül hagyható.
7.12. ábra - Az
IK-REZOLÚCIÓ algoritmus részleges alkalmazása egy egyszerű wumpus világbeli következtetésre. A felső sor első négy klóza alapján származtatjuk a ¬P1,2-t.Hogy befejezzük a rezolúció tárgyalását, most megmutatjuk, hogy az IK-REZOLÚCIÓ algoritmus teljes. Ahhoz, hogy ezt megtehessük, hasznos bevezetni az S klózok halmazának rezolúciós lezártját (resolution closure), RC(S)-t, ami az összes olyan klóz halmaza, amely levezethető a rezolúció ismételt alkalmazásaival az S halmazbeli elemekből és ezek leszármazottaiból. Az IK-REZOLÚCIÓ a rezolúciós lezárás halmaz elemeit sorolja fel a klózok változóban. Könnyű belátni, hogy RC(S)-nek végesnek kell lennie, mert véges sok különböző klózt lehetséges konstruálni az P1, …, Pk szimbólumokból, amelyek elemei S-nek. (Vegyük észre, hogy ez nem volna igaz a faktorálási lépés nélkül, amely megszünteti a literálok többszöröződését.) Így az IK-REZOLÚCIÓ mindig terminálódik.
Az ítéletlogikában a rezolúció teljességi tételét alap rezolúciós tételnek (ground resolution theorem) nevezzük.
Ha klózok egy halmaza kielégíthetetlen, akkor ezeknek a klózoknak a rezolúciós lezártja tartalmazza az üres klózt.
A tételt az ellentétjének demonstrálásával bizonyítjuk: ha az RC(S) lezártja nem tartalmaz üres halmazt, akkor S kielégíthető. Valójában egy modellt konstruálunk S-nek a megfelelő P1, …, Pk igazság értékekkel. A konstrukciós eljárás a következő:
Minden i-re 1-től k-ig,
-
Ha létezik egy klóz RC(S)-ben, amely tartalmazza a ¬Pi literált úgy, hogy minden más literál hamis a választott P1, …, Pi–1 hozzárendelés szerint, akkor rendeljünk hamis értéket Pi-hez.
-
Egyébként rendeljünk igaz értéket Pi-hez.
Az maradt hátra, hogy megmutassuk, hogy ez a P1, …, Pk hozzárendelés modellje S-nek, feltéve, hogy RC(S) zárt a rezolúcióra, és nem tartalmazza az üres klózt. Ennek bizonyítását meghagyjuk feladatnak.
A rezolúciót a teljesség tulajdonsága igen fontos következtetési módszerré teszi. Számos gyakorlati esetben azonban, a rezolúció teljes erejére nincs szükség. A valósvilág-beli tudásbázisok gyakran a klózoknak csak egy, Horn-klóznak (Horn clause) nevezett korlátosabb fajtáját tartalmazzák. A Horn-klóz literálok olyan diszjunkciója, amelyek közül legfeljebb egy pozitív. Például a (¬P1,1 ∨ ¬Szellő ∨ S1,1) klóz, ahol P1,1 jelenti, hogy az ágens pozíciója az [1, 1], egy Horn-klóz, míg az (S1,1 ∨ C1,2 ∨ C2,1) nem az.
A korlátozás, hogy csak egy pozitív literál lehet, egy kissé önkényesnek és érdektelennek tűnhet, de valójában nagyon fontos, három ok miatt is:
-
Minden Horn-klóz felírható egy implikációként is, amelynek premisszája pozitív literálok konjunkciója, és konklúziója egyetlen pozitív literál (lásd 7.12. feladat). Például a (P1,1 ∨ Szellő ∨ S1,1) Horn-klóz átírható a (P1,1 ∧ Szellő) ⇒ S1,1 implikációra. Ebben az utóbbi formájában sokkal könnyebb olvasni a mondatot: azt mondja ki, hogyha az ágens az [1, 1]-ben van, és szellő érzékelhető ott, akkor az [1, 1] szellős. Számos területen az emberek számára könnyű a tudást ilyen mondatok formájában olvasni és leírni.
A Horn-klózokat, mint amilyen az előbbi, vagyis amelyben pontosan egy pozitív literál van, határozott klózoknak (definite clauses) nevezik. A pozitív literál a fej (head), míg a negatív literálok alkotják a klóz testét (body). Egy negatív literálok nélküli határozott klóz egyszerűen kijelent egy adott állítást, amit gyakran ténynek (fact) neveznek. A határozott klózok formálják a logikai programozás (logic programming) alapját, amelyet a 9. fejezetben tárgyalunk. Egy pozitív literálok nélküli Horn-klóz felírható, mint egy olyan implikáció, amelynek a konklúziója a Hamis literál. Például a (¬W1,1 ∨ ¬W1,2) klóz – a wumpus nem lehet mind az [1, 1], mind az [1, 2] mezőben, ekvivalens a W1,1 ∧ W1,2 ⇒ Hamis mondattal. Az ilyen mondatokat integritás kényszereknek (integrity constraints) nevezzük az adatbázis-kezelés területén, ahol adathibák jelzésére használják. A következőkben bemutatásra kerülő algoritmusokban az egyszerűség kedvéért feltételezzük, hogy a tudásbázis csak határozott klózokat tartalmaz, és nincsenek benne integritáskényszerek. Azt mondjuk, hogy ezek a tudásbázisok Horn-formában vannak.
-
A Horn-klózokon történő következtetés történhet az előrefelé láncolás (forward chaining) vagy a hátrafelé láncolás (backward chaining) algoritmusokkal, amelyeket a következőkben elmagyarázunk. Mindkét algoritmus igen természetes, a következtetési lépések nyilvánvalóak és egyszerűen követhetőek az emberek számára.
-
A maga után vonzás kérdésének eldöntéséhez szükséges idő lineárisan függ a tudásbázis méretétől.
7.14. ábra - Előrefelé láncolás algoritmus az ítéletkalkulus számára. Az agenda tartalmazza azokat a szimbólumokat, amelyek ismerten igazak, de még nem „dolgozták fel” őket. A számol tábla követi, hogy az egyes implikációknak hány premisszája ismeretlen. Ha az agendáról egy új p szimbólumot feldolgozunk, minden olyan implikáció számlálója csökken eggyel, amelynek premisszájában p megjelenik. (Ez megoldható konstans időben, ha a TB megfelelően indexelt.) Ha a számláló eléri a nullát, azaz az implikáció minden premisszája ismert, akkor az implikáció konklúzióját hozzá lehet adni az agendához. Végül szükségünk van arra, hogy kövessük melyik szimbólumot dolgoztuk már fel; egy kikövetkeztetett szimbólumot nem kell hozzáadni az agendához, ha azt már korábban sikeresen feldolgoztuk. Így elkerülhető a redundáns munka, és megakadályozza a végtelen ciklusok kialakulását, amelyet olyan implikációk okozhatnak, mint a P ⇒ Q és Q ⇒ P.

Ez az utolsó tény egy kellemes meglepetés. Azt jelenti, hogy a logikai következtetés nagyon olcsó számos, a gyakorlatban előforduló ítéletkalkulus tudásbázis esetében.
Az IK-EL-VONZAT? (TB, q) előrefelé láncolási algoritmus meghatározza, hogy egy q ítéletkalkulus szimbólum – a lekérdezés – vonzata-e egy Horn-klózokat tartalmazó tudásbázisnak. Az algoritmus a tudásbázisban található ismert tényekből (pozitív literálok) indul ki. Ha egy implikáció minden premisszája ismert, akkor a konklúzióját hozzáadjuk az ismert tények halmazához. Például, ha ismert a P1,1, és a Szellő és a (P1,1 ∧ Szellő) ⇒ S1,1 a tudásbázisban van, akkor S1,1-t hozzáadhatjuk ehhez. Ez a folyamat folytatódik, amíg vagy a q lekérdezést hozzá tudjuk adni az ismert tények halmazához, vagy már nem tudunk további következtetést végezni. A részletes algoritmust a 7.14. ábra mutatja, a legfontosabb tulajdonság, amire emlékeznünk kell, hogy ez lineáris időben fut.
Az algoritmust a legjobban úgy érthetjük meg, ha megnézünk egy példát és egy hozzá tartozó ábrát. A 7.15. (a) ábra egy egyszerű Horn-klózokból álló tudásbázist mutat be, amely az A és B ismert tényeket tartalmazza. A 7.15. (b) ábra ugyanezt a tudásbázist egy ÉS-VAGY gráfként (AND-OR graph) ábrázolja. Az ÉS-VAGY gráfokban a konjunkciókat ívekkel összefogott kapcsolatok – minden egyes kapcsolatot bizonyítani kell – jelölik, míg a diszjunkciókat ívek nélkül összefutó kapcsolatok – elég valamelyik kapcsolatot bizonyítani – jelölik. Könnyű áttekinteni, hogyan is működik az előrefelé láncolás a gráfon. Az ismert levelek (itt A és B) adottak, és a következtetés addig halad felfelé a gráfon, amíg lehetséges. Bárhol megjelenik egy konjunkció a folyamatban, a továbbterjesztés megáll addig, amíg az összes konjunkt ismertté nem válik, majd ezután halad tovább. Javasoljuk az olvasónak, hogy vegye át részletesen a példát.
7.15. ábra - (a) Egyszerű Horn-klózokból álló tudásbázis. (b) Ugyanez a tudásbázis ÉS-VAGY gráfként.
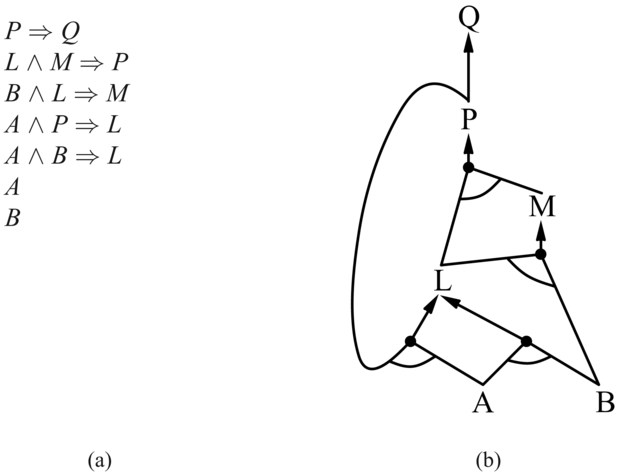
Fontos
Könnyű belátni, hogy az előrefelé láncolás helyes: minden következtetés valójában a Modus Ponens egy alkalmazása. Az előrefelé láncolás teljes is: minden vonzat atomi mondatot vezet le. A legegyszerűbben úgy érthetjük meg ezt, ha a kikövetkeztetett állapot tábla végső állapotát tekintjük (miután az algoritmus elért egy fix pontot (fixed point), ahol már újabb következtetés nem lehetséges). A tábla igaz értéket tartalmaz minden, a folyamat során kikövetkeztetett szimbólumra, és hamis értéket a többi szimbólumra. A táblát úgy tekinthetjük, mint egy logikai modellt, ráadásul minden határozott klóz az eredeti TB-ben igaz ebben a modellben. Ennek belátására feltételezzükaz ellenkezőjét, nevezetesen, hogy valamely a1 ∧ … ∧ ak ⇒ β klóz hamis a modellben. Ez azt jelenti, hogy a1 ∧ … ∧ ak-nak igaznak, míg β-nek hamisnak kell lennie a modellben. Ez viszont ellentmond annak a feltételezésünknek, hogy az algoritmus elérte a fix pontot! Így levonhatjuk azt a következtetést, hogy a kikövetkeztetett atomi mondatok halmaza a fix pontban az eredeti TB egy modelljét definiálja. Ezenkívül, bármely q atomi mondatnak, amely vonzata a TB-nek, igaznak kell lennie ennek minden modelljében, így ebben az említett modellben is. Ennélfogva az algoritmusnak ki kell következtetnie minden q vonzat mondatot.
Az előrefelé láncolás egy példája az általános adatvezéreltnek (data-driven) nevezett következtetési elvnek, amely olyan következtetéseket jelent, ahol a figyelem fókusza kezdetben az ismert adatokon van. Ez a megközelítés alkalmazható az ágenseknél a bejövő érzetekből történő következtetések levezetésére, gyakran anélkül is, hogy valamilyen kérdés lebegne a szemünk előtt. Például a wumpus ágens KIJELENT-heti az érzeteit a tudásbázisnak, felhasználva egy inkrementális előrefelé következtető algoritmust, amelyben új tényeket lehet felvenni egy előjegyzési listára, hogy további következtetés inicializálódjon. A mindennapi életben, jelentős számban fordul elő adatvezérelt következtetés, amikor új információk érkeznek. Például ha bent vagyok a szobában és hallom, hogy elkezd esni, akkor felmerülhet bennem, hogy a tervezett kirándulás elmarad. Ugyanakkor az valószínűleg nem fog megfordulni a fejemben, hogy a szomszéd kertjében a legnagyobb rózsa tizenhetedik szirma nedves lesz. Az emberek óvatos kontroll alatt tartják az előrefelé láncolást, nehogy elárasszák őket az irreleváns következmények.
A visszafelé láncolás algoritmus, ahogy azt a neve is sugallja, visszafelé működik a lekérdezésből indulva. Ha a q lekérdezésről tudjuk, hogy igaz, akkor nem szükséges további munka. Egyébként az algoritmus megtalál minden olyan implikációt a tudásbázisban, amelynek a következménye q. Ha valamelyik ilyen implikációnak az összes premisszáját be lehet bizonyítani (visszafelé láncolással), akkor q igaz. Amikor a 7.15. ábrán a Q lekérdezésre alkalmazzuk a módszert, akkor ez az ábrán követve vissza, lefelé működik, addig, amíg el nem éri az ismert tények halmazát, ami a bizonyítás alapja. A részletes algoritmust meghagyjuk feladatnak, és mint az előrefelé láncolásnál, egy hatékony implementáció itt is lineáris időben működik.
A visszafelé láncolás a célorientált következtetés (goal-oriented reasoning) egy formája. Hasznos-e megválaszolni olyan kérdéseket, mint hogy „Mit tegyek most?”, vagy hogy „Hol vannak a kulcsaim?”. Gyakran a visszafelé láncolás költsége sokkal kisebb, mint a tudásbázis méretétől lineárisan függő költség, mert a folyamat csak releváns tényeket érint. Általánosságban, egy ágensnek meg kell osztania a munkát az előrefelé és hátrafelé láncolás között, korlátozva az előrefelé következtetés alkalmazását azokra a tényekre, amelyek valószínűleg relevánsak azon lekérdezésekhez, amelyeket az ágens visszafelé láncolással fog megoldani.
[69] A nemmonoton logikák (nonmonotonic logics), amelyek megszegik a monotonitás tulajdonságot, az emberi érvelésnek azt a szokványos tulajdonságát jelenítik meg, amikor valaki meggondolja magát. Ezeket a 10.7. alfejezetben tárgyaljuk.
[70] Ha a klózt literálok halmazának tekintjük, akkor ezt a korlátozást automatikusan figyelembe vettük. A halmaz jelölést alkalmazva a klózokra a rezolúciós szabály sokkal tisztább lesz egy újabb jelölés bevezetésének árán.
