Az a priori információnak az előbbiektől eltérő felhasználási lehetősége, ha az információt közvetlenül beépítjük a tanuló eljárásba. A probléma általános felvetése Yaser Abu-Mostafatól származik, aki a járulékos információnak a tanuló eljárásba való beépítését, mint lehetőséget bevezette [Abu90], [Abu95]. Az általa megfogalmazott „utalásokból” történő tanulás(learning from hints) tulajdonképpen mindazon ismeretnek a tanuló eljárásba való beépítését jelenti, mely ismeret nem mintapontok formájában áll rendelkezésre. Ebben az értelmezésben − még ha csak közvetve is −, de az előbbiekben tárgyalt virtuális mintagenerálást is e körbe tartozónak kell tekinteni.
Azt a megközelítést, hogy a priori információt közvetlenül beépítünk a tanuló eljárásba valójában már korábban is alkalmaztuk. A tanuló eljárásba bármilyen járulékos információ beépítése legkönnyebben a kritériumfüggvény módosításán keresztül lehetséges. Amennyiben az optimalizálandó kritériumfüggvény nemcsak egy valamilyen értelemben vett hiba (veszteség, kockázat) minimalizálását fogalmazza meg, hanem járulékos ismeretekből származó feltételeket is megszab, az optimalizáló eljárás eredményeképp a járulékos ismeretek is „beépülnek” a megoldásba. Az előzőekben már alkalmazott regularizációs eljárások valójában pont ezt a megközelítést alkalmazzák. A „valódi” kritériumfüggvényt kiegészítjük egy regularizációs taggal, ahol ez a tag a tanító mintákon túl rendelkezésre álló ismeret figyelembevételét teszi lehetővé. Simasági feltétel beépítésére pl. már több megoldást is láttunk. Valójában a szupport vektor gépeknél alkalmazott súlyvektorhossz minimalizálási feltétel is egy simasági feltétel. A CMAC hálónál alkalmazott súlysimító regularizáció (ld. 5.2 alfejezet) is abból a feltételezésből (vagy a priori információból) indul ki, hogy azt várjuk, hogy a háló válasza a tanítópontok között minél kevésbé legyen változékony, és hirtelen ugrások a mintapontok közötti tartományokban ne forduljanak elő. A sima megoldás preferálása, mint általános cél − miközben természetesen a megoldás döntően a mintapontok által szolgáltatott ismereten kell hogy alapuljon − szintén a priori ismereten alapul, nevezetesen azon ismereten, hogy a természetben inkább sima leképezések fordulnak elő.
12.2.1. Monoton válaszú kernel regresszió
A simasági feltételen túl számos további feltétel megfogalmazása alapul a priori információn [Lau06]. Ilyen feltétel lehet, hogy egy regressziós feladatnál a megoldás monotonitását előírjuk. A monoton LS-SVM regressziós megoldásra találunk példát [Pel04]-ben. A 6. fejezetben bemutatott LS-SVM optimalizálási problémához egydimenziós esetben még a következő feltétel megfogalmazása adódik:
i=1,…,P-1, (12.1)
ahol xi jelöli az SVM bemenetét,
pedig a megfelelő választ. A járulékos információ a tanító eljárásba úgy épül be, hogy a Lagrange kritérium módosul:
. (12.2)
Látható, hogy a szokásos Lagrange együtthatós tag mellett egy újabb tag jelent meg, amely szintén Lagrange multiplikátoros formában veszi figyelembe a monotonitásra vonatkozó feltételeket, ahol a
együtthatók az új Lagrange multiplikátorok.
Más a priori ismeretet tükröző feltételek hasonló módon fogalmazhatók bele a tanuló eljárásba (a kiinduló kritériumfüggvénybe). Az eljárás hátránya, hogy minden újabb formálisan megfogalmazott a priori ismeret a teljes optimalizálási feladat származtatását igényli, ami egyes esetekben komoly matematikai nehézségekkel járhat. Az így kapott eljárások hatékonysága tehát jelentős mértékben függ attól, hogy milyen matematikai nehézségek merülnek fel az elsődleges, illetve a másodlagos optimalizálási feladatok megoldásánál. A monotonitást előíró feltételek figyelembevétele például kvadratikus optimalizálási feladatra vezet annak ellenére, hogy a standard LS-SVM-nél csak lineáris egyenletrendszert kell megoldanunk.
12.2.2. Tudásalapú szupport vektor gép
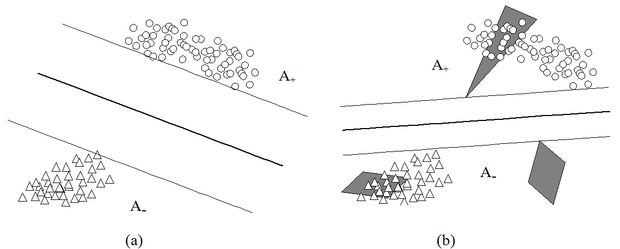
A tudásalapú szupport vektor gépeknél(knowledge-based support vector machines) az a priori tudás a bemeneti tér valamilyen korlátozott tartományára vonatkozik. Glenn Fung és munkatársai olyan osztályozós esetet vizsgáltak, amikor a bemeneti tér egyes poliéder tartományai teljes egészében az egyik osztályhoz tartoznak [Fun03]. Az osztályozási problémát ebben az esetben tehát egyrészt az ismert besorolású tanítópontok, másrészt a poliéder tartományok (egyenesekkel, síkokkal illetve hipersíkokkal határolt tartományok) specifikálják. A poliéder tartományoknak, mint a priori információnak az osztályozásra gyakorolt hatását illusztrálja a 12.1 ábra.
A Fung és Mangasarian által javasolt SVM-ben a megszokott négyzetes hiba helyett egyes normájú hiba szerepel a célfeltételben, így a feladat megoldása (hasonlóan az LS-SVM-hez) nem igényel kvadratikus programozást, elegendő a létrejövő lineáris egyenlőtlenségrendszert lineáris programozással megoldani. Az említett poliéder tartományok ezt a lineáris egyenletrendszert egészítik ki extra egyenlőtlenségekkel.
Hasonló eljárást dolgoztak ki függvényapproximációs feladatokra is, ahol az a priori információ a függvényre vonatkozóan extra korlátokat jelent [Man04]. Az alábbiakban bemutatjuk a lineáris kernel modellt, ami az alapfeladatot leírja.
Mint az eddigi függvényapproximációs feladatoknál most is egy
függvényt szeretnénk közelíteni az
. (12.3)
lineáris kapcsolattal az
mintapontok felhasználásával. Jelölje a bemeneti mintavektorokat összefogó mátrixot
. (12.4)
Ezzel a háló válasza az összes tanítópontra a következő formában is felírható:
, (12.5)
ahol
egy csupa egyesekből álló vektor. Feltételezve, hogy a háló válaszai közelítik a kívánt válaszokat, az approximáció hibája közel nulla, vagyis:
, (12.6)
ahol d a di, i=1,…,P kívánt válaszokból képezett vektor. Ahogy azt a kernel gépeknél már láttuk, a súlyvektor X sorainak lineáris kombinációjaként is előállítható:
. (12.7)
Itt
a lineáris kombináció együtthatóinak vektora. (A szokásos Lagrange multiplikátoros felírásnál
a Lagrange multiplikátorokból álló vektor.) Behelyettesítve a súlyvektor (12.7) kifejezését a (12.6) összefüggésbe, a lineáris kernel gépek szokásos formájú felírását kapjuk:
(12.8)
ahol
a lineáris kernel mátrix. A hibát az
vektorral elemenként mérjük, és ennek a hibának az 1-es normáját minimalizáljuk, ahol az 1-es norma jelentése:
(12.9)
Az 1-es norma alkalmazásának következménye, hogy a megoldást a szupport vektor gépeknél (6. fejezet) látott kvadratikus programozás helyett itt lineáris programozással megkaphatjuk. A megoldandó feladat a:
(12.10)
kritériumfüggvény minimumát biztosító α, b és e megtalálása, azzal a feltétellel, hogy teljesülnek az alábbi formában megfogalmazott egyenlőtlenségek:
(12.11)
A feltételes optimalizálási feladat az alábbi lineáris programozási feladatra vezethető vissza:
(12.12)
Az eddigiek csupán azt illusztrálták, hogy egy kernel regressziós feladatnál a kritériumfüggvény a 6. fejezetben bemutatott kritériumfüggvényektől eltérő formában is megfogalmazható. A más megfogalmazást az indokolja, hogy így a kvadratikus programozási feladat helyett a megoldás lineáris programozással megkapható. A lineáris programozás számítási komplexitásban egyértelműen előnyösebb, mint a kvadratikus programozást igénylő „klasszikus” SVM.
A tudás alapú szupport vektor gépeknél járulékos információt is beépítünk az eljárásba. A fenti kiindulás mellett a lineáris egyenlőtlenségek formájában megfogalmazott a priori információ beépítése is lineáris programozási feladatra vezet. Az a priori információ itt azt jelenti, hogy a bemeneti tér egy poliéder tartományára további feltétel fogalmazható meg.
Ez a feltétel minden olyan
bemenetre vonatkozik, amely nem feltétlenül tartozik a tanítópontok közé, de melyre igaz, hogy egy
, (12.13)
által meghatározott nem üres poliéderen belül található, ahol
valamilyen együttható készlet,
pedig valamilyen valós számokból álló vektor. A feltétel azt fogalmazza meg, hogy a poliéder tartományra az approximálandó függvénynek dominálnia kell egy adott lineáris függvényt, vagyis a járulékos információ az alábbi implikáció formájában fogalmazható meg:
, (12.14)
A lineáris függvény h és β paramétereit az a priori információ szolgáltatja. A súlyvektor (12.7) összefüggését felhasználva az implikáció
, (12.15)
formában is felírható. Ezt az implikációt kell még a (12.12) lineáris programozási feladathoz hozzávennünk.
Ennek érdekében az implikációt át kell alakítani lineáris egyenlőtlenségekké. Nem bizonyítjuk, de amennyiben a fenti implikációnak van megoldása, akkor az alábbi rendszer
megoldása ekvivalens az implikáció megoldásával:
(12.16)
Az itt megfogalmazott feltételeket hozzávéve a (12.12)-ben megadott lineáris programozási feladathoz megkapjuk azt a lineáris programozási feladatot, mely a mintapontokon túl a járulékos ismeretet is figyelembe veszi. A minimalizálandó kritériumfüggvény, melynél a minimumot
szerint keressük, ahol
, az alábbi:
, (12.17)
a mellékfeltételek pedig:
(12.18)
A kapott megoldás meglehetősen speciális esetre érvényes, hiszen lineáris függvényapproximációs feladatból indultunk ki és az a priori információ is a bemenet lineáris függvényeként van megfogalmazva. Az eljárás nemlineáris esetre történő általánosítása viszonylag természetes módon megtörténhet. Ekkor egyrészt a lineáris kernel helyett nemlineáris kernellel dolgozunk, másrészt az a priori információt is mint a bemenet nemlineáris függvényét fogalmazzuk meg. Ennek részleteire azonban itt nem térünk ki.
A priori ismeretek beépítésére az eddig bemutatott eljárásokon kívül számos további eljárást is kidolgoztak. Ilyen eljárásokat ismertet pl. [Yu04], [Sun05] és [Le06], valamint az a priori információ beépítésének egy további lehetőségére ad példát a következőkben bemutatott súlyozott margójú SVM is.
12.2.3. Súlyozott margójú szupport vektor gép
A súlyozott margójú szupport vektor gépeknél(Weighted Margin Support Vector Machines, WMSVM) [Wu04] minden tanító mintához a rendelkezésre álló a priori információ alapján egy konfidencia értéket is rendelünk. A konfidencia értékek hatása, hogy az egyes tanító minták különböző súllyal vesznek részt az SVM tanításában. A súlyozott szupport vektor gép működését lineárisan szeparálható esetre mutatjuk be, de értelemszerűen az eredmények megfelelő kernelfüggvény-választást követően érvényesek a nemlineárisan szeparálható esetre is.
Adott egy lineárisan szeparálható tanítóhalmaz
, és minden mintához rendelkezésünkre áll egy
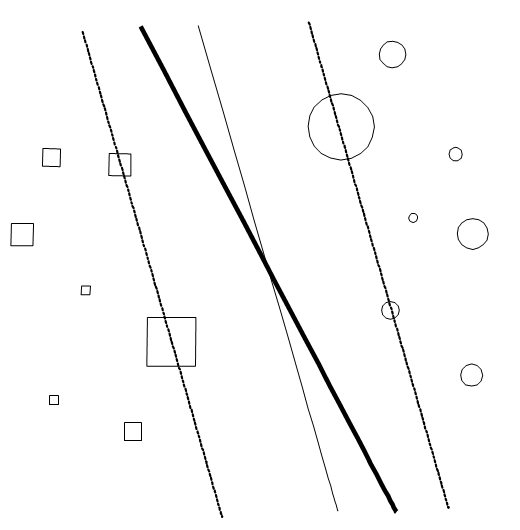
konfidenciaérték, ami a di kívánt válasz konfidenciaszintjét jellemzi. A konfidenciához olyan intuitív értelmezés adható, hogy minél nagyobb egy minta konfidenciája, annál nagyobb margót szeretnénk biztosítani az adott mintánál. A súlyozott SVM és a standard SVM közötti különbséget illusztrálja a 12.2 ábra. Az ábrán látható kétosztályos osztályozási feladatnál különböző méretű körök és négyzetek jelölik a két osztályba tartozó mintapontokat, és a körök, illetve a négyzetek mérete képviseli a mintaponthoz rendelt konfidenciát. Az ábrán vékony folytonos vonal jelzi az SVM szeparáló egyenesét. Látható, hogy ez nem veszi figyelembe a mintapontokhoz rendelt konfidenciát, míg a vastag vonal olyan elválasztó felületet képvisel, mely a nagyobb konfidenciájú pontoknál nagyobb távolságot (nagyobb margót), a kisebb konfidenciájú pontoknál pedig kisebb távolságot biztosít.
A súlyozott margójú megoldás származtatása a standard SVM 6. fejezetben bemutatott származtatásához hasonlóan történik. Itt is azt a w súlyvektorral és b eltolás értékkel jellemezhető hipersíkot keressük, ahol
minimális, és ahol az osztályozásra vonatkozó
(12.19)
feltételek teljesülnek. A (12.19) összefüggésben szereplő
monoton csökkenő függvény biztosítja, hogy a „megbízhatóbb”, nagyobb konfidenciájú mintapontok nagyobb hatást gyakorolnak az elválasztó hipersíkra, ezeknél a pontoknál nagyobb margót kapunk.
A részletektől eltekintve a megoldás súlyvektorára a következő adódik:
(12.20)
ahol az
együtthatók most is a Lagrange multiplikátorok.
A standard SVM-hez hasonlóan itt is származtatható egy lágy margójú változat, ha egy gyengítő változót vezetünk be. Ekkor a megfelelő kritériumfüggvény a következő lesz
. (12.21)
Ennek w szerinti minimumát keressük azzal a feltétellel, hogy
. (12.22)
ahol
egy monoton csökkenő és
egy monoton növekedő függvény és a
értékek a gyengítő változó értékei. A szokásos lépések eredményeképpen itt is megkapjuk a megoldás súlyvektorát:
, (12.23)
ahol teljesülnie kell még a következő összefüggéseknek:
. (12.24)
A priori tudás beépítése WMSVM-be
A súlyozott margójú szupport vektor gépeknél a priori tudást egyrészt a konfidencia értékek meghatározásával, másrészt virtuális minták generálásával is beépíthetünk az eljárásba. A kiinduló mintákhoz tartozó konfidencia értékek például a mintákat terhelő zajtól függhetnek. A virtuális minták generálása itt nem invariancia transzformációk alkalmazását jelenti, hanem ismeretlen válaszú mintapontok beiktatását, ahol a kívánt válasz és annak konfidenciája származik az a priori információból. Konfidencia értékként annak a
feltételes valószínűségnek a becslését használhatjuk, amely megadja, hogy egy adott, ismeretlen osztályba tartozó x bemenet milyen valószínűséggel tartozhat egy adott osztályba. A módszer jelentősége, hogy bizonytalan a priori tudást is be tud építeni. Ugyancsak a priori ismeret alapján választhatjuk meg az
és
függvényeket. Ezeknek a függvényeknek a hatása nagymértékben függ a
konfidencia értékektől. Mivel a legtöbb valós problémán a
értékekre csak durva becslést tudunk adni és semmilyen elmélet nem támasztja alá a komplexebb függvények használatának előnyét, ezért a legtöbb esetben a legegyszerűbb függvényeket, pl. az
és a
függvényeket használhatjuk.
Példaként tekintsünk egy lehetséges alkalmazást, különböző dokumentumok kategorizálását. A kiinduló tanítóhalmaz a már kategorizált dokumentumok halmaza. A virtuális tanítóhalmaz kialakításához szükséges konfidencia értékeket a már kategorizált tanítóhalmaz alapján szakértői tudás felhasználásával határozhatjuk meg. A szakértők a tanítóhalmazba tartozó dokumentumok alapján olyan szavakat választanak ki, melyek szerintük az adott kategóriát jól jellemzik, vagyis egy kiválasztott szó nagy valószínűséggel fordul elő egy adott kategóriába tartozó dokumentumokban. Ezeket a szavakat tekintsük kulcsszavaknak. Például, ha a kategória a kardiológia, akkor a kulcsszavak a vér, vérnyomás, szív, véna, artéria stb. A jelöletlen dokumentumok kategorizálása a kulcsszavak keresésével történik. A konfidencia értékeket többféleképpen is előállíthatjuk. Jelöljön x egy adott dokumentumot és c egy adott kategóriát. Az x mintának a c kategóriába tartozását jellemző konfidencia legyen egyszerűen
, ahol
jelöli, hogy az x dokumentumban az adott kategóriát jellemző kulcsszavak közül hány fordul elő,
pedig azt adja meg, hogy az adott kategóriát hány kulcsszóval jellemzünk (A jelölésnél a kw index a kulcsszóra (keyword) utal.) Azokat a dokumentumokat, melyek egyetlen kulcsszót sem tartalmaznak, figyelmen kívül hagyjuk.
Az SVM konstrukciója ezek után a két tanítóhalmaz együttes felhasználásával történik. Amennyiben az eredeti mintahalmaz pontjaihoz is rendeltünk konfidencia értékeket, a két mintahalmaz eltérő kezelésére nincs szükség. Ha azonban az eredeti tanítóhalmaz mintáit zajmentesnek, pontosnak tekinthetjük, akkor célszerű, ha ezen mintákhoz nem rendelünk konfidencia értékeket (pontosabban ezekhez egységnyi konfidencia értékeket rendelünk), vagyis a két mintahalmaz pontjait a kritériumfüggvényben különbözőképpen vesszük figyelembe. Amennyiben az első P1 elemű mintahalmaz az eredeti ismert kategóriájú tanítómintákból áll és a maradék P − P1 minta képezi a virtuális mintahalmazt, akkor a következő módosított kritériumfüggvényt célszerű használni:
. (12.25)
Itt C az SVM-nél megszokott paraméter, amely a biztonsági sáv mérete és a sávon belülre eső pontok száma közötti egyensúlyért felelős, míg az
paraméter a két tanítóhalmaz relatív fontosságának beállítására szolgál. Értelemszerűen, ha az eredetileg ismert kategóriájú dokumentumok száma kicsi, akkor nagy
-t érdemes választani. Ahogy a valóban kategorizált dokumentumok száma növekszik, úgy érdemes a virtuális tanítóhalmaz hatását csökkenteni, hiszen az eredeti tanítóhalmaz „jobb minőségű”.