23.4. Gépi fordítás
A gépi fordítás (machine translation) egy természetes nyelvű szöveg egyik nyelvről (forrás) egy másik nyelvre (cél) történő automatikus fordítása. Ez a folyamat számos feladatra alkalmasnak bizonyult, beleértve a következőket:
-
Nyersfordítás (rough translation), amelyben a cél pusztán az, hogy egy passzus lényegét megkapjuk. Nyelvtanilag helytelen és nem elegáns mondatokat is elfogadunk, mindaddig, amíg a jelentés világos. Például a webszörfözés során a felhasználó gyakran örül az idegen nyelvű weboldal nyersfordításának. Az esetek egy részében egy egynyelvű ember utólagosan szerkesztheti a kimenetet, az eredeti szöveg elolvasásának szükségessége nélkül. A géppel támogatott fordítás ezen típusa azért takarít meg pénzt, mert az ilyen szerkesztőknek kevesebbet kell fizetni, mint a kétnyelvű fordítóknak.
-
Korlátozott forrás fordítása (restricted-source translation), amelyben a forrásszöveg témája és formátuma szigorúan korlátozott. Az egyik legsikeresebb példa a
TAUM-METEOrendszer, amely időjárás-jelentéseket fordít angolból franciára. Azért működik, mert az időjárás-jelentések nyelvezete erősen stilizált és reguláris. -
Előre szerkesztett fordítás (preedited translation), amelyben egy ember úgy szerkeszti meg előre a forrásdokumentumot, hogy megfeleljen az angol nyelv (vagy bármely forrásnyelv) egy korlátozott részhalmazának. Ez a megközelítés különösen akkor költséghatékony, amikor egyetlen dokumentumot sok nyelvre kell lefordítani, mint például jogi szövegeket az Európai Közösségnél, vagy olyan vállalatok esetén, amelyek ugyanazt a terméket sok országban értékesítik. A korlátozott nyelveket néha „Caterpillar-angolnak” nevezik, mert a Caterpillar vállalat volt az első, amelyik az útmutatóit ilyen formában próbálta megírni. A Xerox olyan nyelvet definiált a javítási útmutatók számára, amely annyira egyszerű volt, hogy géppel le lehetett fordítani minden olyan nyelvre, amellyel a Xerox érintkezésbe kerül. További haszonként az eredeti angol nyelvű útmutatók is világosabbá váltak.
-
Irodalmi fordítás (literary translation), amely a forrásszöveg legkisebb árnyalatát is megőrzi. Ez jelenleg túlmutat a legmodernebb gépi fordítók képességén is.
A nyersfordítás példájaként álljon itt jelen fejezetünk első bekezdésének a SYSTRAN fordító szolgáltatás által történt fordítása előbb olaszra, majd vissza angolra:[252]

A fordítás azért nehéz, mert általában a szövegek mély megértését igényli, amihez pedig a közölt szituáció mély megértése szükséges. Ez még nagyon egyszerű szövegek esetén is fennáll, sőt egyszavas „szövegek” esetén is. Vegyük a „Open” szót egy üzlet ajtaján.[253] Ez azt az információt közvetíti, hogy az üzlet pillanatnyilag fogad vevőket. Most vegyük ugyanezt a szót egy újonnan felépített üzleten található hatalmas transzparensen. Ez azt jelenti, hogy az üzlet megnyílt, de az olvasók nem éreznék becsapva magukat, ha éjszaka a transzparens eltávolítása nélkül lenne zárva a bolt. A két felirat ugyanazt a szót használja különböző jelentések közvetítésére. Német nyelvű országban a felirat az ajtón „Offen”, míg a transzparensen „Neu eröffnet” lenne.[254]
Az a probléma, hogy az egyes nyelvek eltérő módon kategorizálják a világot. Például a francia „doux” szó jelentések széles körét fogja át, amely megközelítőleg a következő angol szavakkal adható meg: „soft”, „sweet”, „gentle”.[255] Hasonlóképpen az angol „hard” szó gyakorlatilag a német „hart” szó összes jelentését (fizikailag ellenálló, durva) lefedi, emellett a „schwierig” („nehéz”, fáradságos, bonyolult értelemben) szó néhány jelentését is magában foglalja. A német „heilen” (meggyógyít) ige az angol „cure” (gyógyít) szó orvosi használatát fedi le, továbbá a „heal” (meggyógyul) tranzitív és intranzitív jelentéseit. Emiatt az adott mondat jelentésének ábrázolása sokkal nehezebb a fordítás, mint az egynyelvi megértés esetén. Egy egynyelvű elemzőrendszer használhatna olyan predikátumokat, mint Open(x), azonban a fordítás céljából a reprezentációs nyelvnek esetleg több megkülönböztetést kellene tennie, például az „Offen” jelentést reprezentáló Open1(x) predikátummal és a „Neu eröffnet” jelentést reprezentáló Open2(x) predikátummal. Azt a reprezentációs nyelvet, amely a lefedett nyelvekhez szükséges összes megkülönböztetést lehetővé teszi, köztes nyelvnek (interlingua) nevezzük.
Folyékony fordításhoz az szükséges, hogy a fordító (ember vagy gép) elolvassa az eredeti szöveget, megértse a szituációt, amiről szól, és találjon egy megfelelő szöveget a célnyelvben, amely jól leírja ugyanazt, vagy egy hasonló szituációt. Ez gyakran választást jelent. Például amennyiben az angol „you” szó egy személyre vonatkozik, akkor vagy a magyar hivatalos „ön” vagy a közvetlen „te” alakra fordítható. Egyszerűen nem lehet a „you” fogalomról beszélni magyarul anélkül, hogy eldöntenénk, hogy hivatalos vagy közvetlen módon szeretnénk használni. A fordítók (mind a gépi, mind az emberi) néha nehezen tudják ezt a döntést meghozni.
A gépi fordító rendszerek erősen különböznek abban, hogy milyen szinten elemzik a szöveget. Egyes rendszerek a bemeneti szöveget egészen a köztes nyelv szintjéig próbálják elemezni (mint ahogy azt a 22. fejezetben tettük), majd a célnyelven ezen reprezentáció alapján generálnak mondatokat. Ez azért nehéz, mert részproblémaként tartalmazza a teljes nyelvi megértés problémáját, amihez még a köztes nyelv kezeléséből fakadó nehézségek is hozzáadódnak. A megközelítés azért törékeny, mert ha az elemzés sikertelen, akkor nincs kimenet. Azonban az az előnye, hogy a rendszerben nincs olyan komponens, amelynek két (természetes) nyelvet egyszerre kell ismernie. Ez azt jelenti, hogy köztes nyelv használatával n nyelv közti fordítás O(n) és nem O(n2) nehézségű.
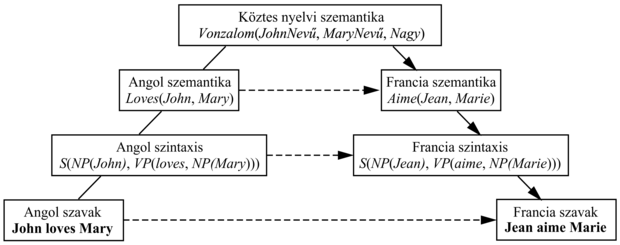
Más rendszerek az átvitelen (transfer) alapulnak. Fordítási szabályok (vagy példák) adatbázisát tartalmazzák, és amikor egy szabály (vagy példa) illeszkedik, akkor közvetlenül fordítanak. Az átvitel lexikai, szintaktikai vagy szemantikai szinten történhet. Például egy szigorúan szintaktikai szabály az angol [Melléknév Főnév] szekvenciát a francia [Főnév Melléknév] szekvenciába képezi le. Egy kevert szintaktikai és lexikai szabály a francia [S1 „et puis” S2] szekvenciát az angol [S1 „and then” S2] szekvenciába képezi le.[256] Azt az átvitelt, amely egy mondatot közvetlenül egy másikba visz át, memóriaalapú fordításnak (memory-based translation) nevezünk, mivel nagyszámú (angol, francia) pár memorizálására támaszkodik. Az átviteli módszer robusztus, mert minden esetben generál valamilyen kimenetet, és legalább a szavak egy része feltétlenül helyes. A 23.5. ábra bemutatja az egyes átviteli pontokat.
23.5. ábra - Egy gépi fordító rendszer választási lehetőségeit ábrázoló sematikus diagram. A fenn található angol szöveggel kezdjük. A köztes nyelven alapuló rendszer a folytonos vonalakat követi, az angol szöveget először szintaktikai elemzésnek veti alá, majd szemantikai és köztes nyelvi reprezentációt állít elő, végül szemantikai, szintaktikai és lexikai formákon keresztül francia szöveget állít elő. Az átvitelalapú rendszerek a szaggatott vonalak által jelölt rövidzárakat használják. Az egyes rendszerek eltérő szinteken végzik az átvitelt, egyes rendszerek több szinten is.
Az 1960-as évek elején nagy reményeket fűztek ahhoz, hogy a számítógépek képesek egyik természetes nyelvből a másikba fordítani csakúgy, mint ahogy Turing projektje képes volt kódolt német üzeneteket értelmes német szövegbe fordítani. 1966-ra világossá vált, hogy a folyékony fordítás igényli az üzenet jelentésének a megértését, míg a kódfejtés nem.
Az elmúlt évtizedben elmozdulás volt megfigyelhető a statisztikai alapú gépi fordító rendszerek irányába. Természetesen, a 23.5. ábra bármely lépésének javára szolgálnának statisztikai adatok, valamint egy olyan egyértelmű valószínűségi modell használata, amely megadja, hogy mi egy jó analízis vagy átvitel. Azonban a „statisztikai gépi fordítás” az egész fordítási probléma olyan megközelítésének a megnevezésévé vált, amely a mondat legvalószínűbb fordításának kétnyelvű korpuszon alapuló megtalálását jelenti. A kétnyelvű korpuszok egyik példája a Hansard,[257] amely parlamenti viták naplója. Kanada, Hongkong és más országok kétnyelvű Hansardokat tesznek közzé, az Európai Unió 11 nyelven[258] publikálja hivatalos dokumentumait, míg az Egyesült Nemzetek Szervezete többnyelvű dokumentumokat ad ki. Ezek a statisztikai gépi fordítás számára felbecsülhetetlenül értékes forrásoknak bizonyultak.
Egy angol nyelvű mondat (E) például francia[259] (F) mondatra történő fordításának problémáját a Bayes-szabály következő alkalmazásaként írhatjuk le:
|
|
|
|
|
Ez a szabály azt állítja, hogy minden lehetséges F francia mondatot figyelembe kell vennünk, és azt kell választanunk, amelyik maximalizálja P(E|F)P(F)-t. A P(E) tényezőt nem kell figyelembe venni, hiszen minden F esetén azonos. A P(F) tényező a francia nyelvi modell (language model), azt adja meg, hogy milyen valószínűségű egy adott francia mondat. A P(E|F) a fordítási modell (translation model), azt adja meg, hogy milyen valószínűségű egy adott angol mondat, mint az adott francia mondat fordítása.
Az ügyes olvasók bizonyára csodálkoznak, hogy mit nyertünk a P(F|E) definiálásával a P(E|F) segítségével. A Bayes-szabály más alkalmazásainál azért tettük ezt, mert kauzális modellt akartunk használni. Például a P(Szimptómák|Betegség) kauzális modellt használtuk P(Betegség|Szimptómák) kiszámolására. A fordítás esetében azonban egyik irány sem kauzálisabb, mint a másik. Jelen esetben a Bayes-szabály alkalmazásának az az oka, hogy azt hisszük, képesek leszünk egy olyan P(F) nyelvi modellt megtanulni, amely pontosabb, mint a P(E|F) fordítási modell (és pontosabb, mint P(F|E) közvetlen becslése). Lényegében a problémát két részre osztottuk: először a P(F|E) fordítási modellt alkalmazzuk, hogy olyan francia mondatokat találjunk, amelyek visszaadják az angol mondat lényegét, de amelyek nem feltétlenül folyékony francia mondatok, majd a P(F) nyelvi modellt (amelyre sokkal jobb valószínűségi becslésünk van) használjuk a legjobb jelölt kiválasztására.
A P(F) nyelvi modell bármilyen olyan modell lehet, amely egy mondathoz valószínűséget rendel. Nagyon nagy korpusz esetén P(F)-et közvetlenül becsülhetnénk az egyes mondatok korpuszbeli előfordulási száma alapján. Például ha a webről összegyűjtünk 100 millió francia mondatot, és a „Clique ici”[260] mondat 50 ezerszer fordul elő, akkor P(Clique ici) = 0,0005. Azonban még 100 millió példa esetén is a legtöbb mondat előfordulási száma nulla lenne.[261] Emiatt az ismert bigram modellt fogjuk alkalmazni, amelyben az f1…fn szavakból álló francia nyelvű mondat valószínűsége:
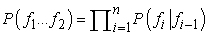
Ismernünk kell az olyan bigram valószínűségeket, mint például a P(Eiffel|tour) = 0,02.[262] Ez a szintaxis mindössze nagyon lokális jellemzőit képes leírni, ahol a szó csak az őt megelőző szótól függ. A nyersfordításhoz azonban többnyire ez is elegendő.[263]
A P(E|F) fordítási modellt (translation model) nehezebb meghatározni. Egyrészt nem áll rendelkezésünkre (angol, francia) mondatpárokból álló kész gyűjtemény, amely alapján taníthatnánk. Másrészt a modell komplexitása nagyobb, mivel mondatok keresztszorzatára, és nem pedig különálló mondatokra alapul. Egy túlzottan leegyszerűsített fordítási modellel fogunk kezdeni, és felépítünk valamit, ami az „IBM Model 3”-at (Brown és társai, 1993) közelíti, ami továbbra is a végletekig leegyszerűsítettnek tűnik, azonban az esetek körülbelül felében elfogadható fordításokat generált.
A végletekig leegyszerűsített modell arról szól, hogy „a mondat fordításához egyszerűen fordítsuk le a szavakat egyesével és egymástól függetlenül, balról jobbra”. Ez egy unigram szóválasztási modell. Lehetővé teszi, hogy egyszerűen kiszámítsuk egy fordítás valószínűségét:
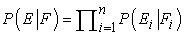
Néhány esetben ez a modell jól működik. Vegyük például a következőt:
P(the dog|le chien) = P(the|le) × P(dog|chien)
Bármely elfogadható valószínűségi értékhalmaz esetén a „the dog”[264] lenne a „le chien” maximum-likelihood becslője. A legtöbb esetben azonban a modell megbukik. Az egyik probléma a szórend. Franciában a „dog” megfelelője a „chien”, a „brown”-é a „brun”, azonban a „brown dog”-é a „chien brun”.[265] A másik probléma az, hogy a szóválasztás nem egy az egyes leképezés. Az angol „home” szót gyakran „à la maison”-nak[266] fordítják, ami egy hármas leképezés (illetve három az egybe a másik irányban). Ezen problémák ellenére az IBM Model 3 makacsul ragaszkodik az alap unigram modellhez, bár, hogy javítson rajta, hozzátesz néhány kiegészítést.
A modell, hogy képes legyen kezelni azt a tényt, hogy a szavakat nem egy az egyben fordítjuk, bevezeti a szó termékenységének (fertility) fogalmát. Egy n termékenységű szót n-szer lemásolja, és az n másolat mindegyike függetlenül fordítódik. A modell az összes francia szóra tartalmazza a P(termékenység = n|szó) paramétereket. Az „à la maison” „home”-ra történő fordításához a modell 0 termékenységet választana az „à” és „la” szavakra,[267] míg egyet a „maison”-ra, és utána az unigram modellt alkalmazná a „maison” szó „home”-ra történő fordításához. Ez eléggé indokoltnak tűnik, az „à” és a „la” kis információtartalmú szavak, amelyeket ésszerű üres karakterfüzérré fordítani. A másik irányba történő fordítás már kétségesebb. A „home” szóhoz hármas termékenységet rendelne a modell, „home home home” szekvenciát kapva. Az első „home” „à”-ra, a második „la”-ra, míg a harmadik „maison”-ra fordulna. A fordítási modell szempontjából az „à la maison” és a „maison à la” pontosan azonos valószínűséget kapna. (Pont ez a kétséges rész.) A nyelvi modellre lenne bízva, hogy eldöntse, melyik a jobb. Értelmesebbnek tűnhet a „home”-ot közvetlenül „à la maison”-ra fordítani, mint közvetett módon a „home home home”-on keresztül, azonban ehhez sokkal több paraméterre lenne szükség, amelyeket nehéz lenne a rendelkezésre álló korpuszból meghatározni.
A fordítási modell végső része a szavak megfelelő sorrendbe történő permutálása. Ez egy eltolási modellel történik, amely során a szó az eredeti pozíciójából a végleges pozícióba mozog. Például a „chien brun” „brown dog”-ra történő fordítása során a „brown” szó +1 eltolási értéket kap (azaz jobbra egy pozíciót mozog), míg a „dog” –1 értéket. Az olvasó elképzelheti, hogy az eltolásnak függnie kellene a szótól: az olyan melléknevek, mint a „brown” többnyire pozitív eltolási értékkel rendelkeznének, mert a francia nyelv általában a főnév után helyezi el a mellékneveket. Azonban az IBM Model 3 úgy döntött, hogy a szótól függő eltolás túl sok paramétert igényelne, ezért az eltolás független a szótól, és csak a mondatbeli pozíciótól és a mondat mindkét nyelvbeli hosszától függ. Azaz a modell a következő paramétereket becsüli:
P(Eltolás = o|Pozíció = p, AngolHossz = m, FranciaHossz = n)
Azaz a „brown” szó „brown dog”-beli eltolásának meghatározásához megnézzük a P(Eltolás|1,2,2) értékét, amely mondjuk +1 értéket adna 0,3, és 0 értéket 0,7 valószínűséggel. Az eltolási modell még kétségesebbnek látszik, olyan, mintha egy olyan személy agyalta volna ki, aki sokkal jobban ért a mágnesbetűk hűtőn történő tologatásához, mint a valódi természetes nyelven történő beszédhez. Rövidesen bemutatjuk, hogy nem azért tervezték ilyen módon, mert jól modellezi a természetes nyelvet, hanem azért, mert a rendelkezésre álló adatokat ésszerűen hasznosítja. Mindenesetre arra szolgál, hogy élénken emlékeztessen bennünket arra, hogy egy középszerű fordítási modellt meg lehet menteni egy jó francia nyelvi modellel. Íme, egy példa egy mondat fordításának lépéseire.[268]

Most már tudjuk, hogyan kell kiszámítani a P(F|E) valószínűséget bármely (francia, angol) mondatpárra. Azonban amit igazából tenni akarunk az az, hogy egy adott angol mondat esetén megtaláljuk azt a francia mondatot, amely maximalizálja ezt a valószínűséget. Nem sorolhatunk fel egyszerűen mondatokat: 105 francia szó esetén 105n n hosszúságú mondat lehetséges, és számos összerendelés mindegyikre. Még ha csak a 10 leggyakoribb szó-szó fordítást tekintjük minden egyes szóra, és csak 0 és ±1 eltolást veszünk figyelembe, akkor is 2n/210n mondatot kapunk, ami azt jelenti, hogy n = 5 esetén még fel tudnánk őket sorolni, de n = 10 esetén már nem. Ehelyett meg kell keresnünk a legjobb megoldást. Az A* keresés hatékonynak bizonyult a feladatra (Germann és társai, 2001).
Körvonalaztunk egy olyan P(F|E) modellt, amely négy paraméterhalmazt tartalmaz:
Nyelvi modell: P(szói|szói–1)
Termékenységi modell: P(Termékenység = n|szóF)
Szóválasztási modell: P(szóE|szóF)
Eltolási modell: P(Eltolás = o|pozíció, hosszE, hosszF)
Ennek a modellnek még egy 1000 szót tartalmazó, szerény szókincs esetén is paraméterek millióira van szüksége. Nyilvánvalóan adatokból kell megtanulnunk őket. Feltételezzük, hogy az egyetlen rendelkezésünkre álló adat egy kétnyelvű korpusz. Lássuk a felhasználási módját:
Mondatokra történő szegmentáció: a fordítási egység a mondat, tehát a korpuszt mondatokra kell tördelnünk. A pont a mondatvég jellemző indikátora, de vegyük a „Dr. J. R. Smith of Rodeo Dr. megérkezett.” példát, amelyben csak az utolsó pont jelenti a mondat végét. A mondatokra történő szegmentációt körülbelül 98%-os pontossággal lehet elvégezni.
A P(szói|szói–1) francia nyelvi modell becslése: vegyük a korpusz francia nyelvű részét, számoljuk meg a szópárok előfordulási gyakoriságát, és végezzünk simítást, hogy megkapjuk a P(szói|szói–1) becslőjét. Például megkaphatjuk, hogy P(Eiffel|tour) = 0,02.
Mondatok illesztése: minden egyes angol nyelvű mondatra határozzuk meg az(oka)t a francia nyelvű mondato(ka)t, amely(ek) megfelel(nek) neki a francia változatban. Általában a szövegben következő angol mondat megfelel a következő francia mondatnak 1:1 megfeleltetéssel, azonban néha előfordulnak variációk: az egyik nyelvű mondatot 2:1 megfeleltetésbe vágjuk, vagy két mondat sorrendjét felcseréljük, 2:2 megfeleltetést kapva. Mindössze a mondathosszakat tekintve lehetséges az illesztésük (1:1, 1:2, 2:2 stb.) 90% és 99% közötti pontossággal, a Viterbi szegmentációs algoritmus (lásd 23.1. ábra) megfelelő variációjával. Még jobb illeszkedés is elérhető amennyiben olyan iránypontokat használunk, amelyek mindkét nyelvben közösek, mint például számok, tulajdonnevek, illetve olyan szavak, melyeknek – egy kétnyelvű szótár alapján – tudjuk, hogy egyértelmű a fordításuk.
A P(Termékenység = n|szóF) kezdeti termékenységi modell becslése: legyen adott egy m hosszúságú francia mondat, amely egy n hosszúságú angol mondathoz illeszkedik, ekkor vegyük ezt annak alátámasztásaként, hogy mindegyik (a mondatban előforduló) francia szó termékenysége n/m. Vegyük figyelembe ezeket az összes mondatra az egyes szavak termékenységi eloszlásának meghatározásához.
A P(szóE|szóF) kezdeti szóválasztási modell becslése: vegyük az összes olyan mondatot, amely tartalmazza például a „brun” szót. Azok a szavak, amelyek a leggyakrabban fordulnak elő az illeszkedő angol mondatokban, valószínűleg a „brun” szó-szó fordításai.
A P(Eltolás = o|pozíció, hosszE, hosszF) kezdeti eltolási modell becslése: most, hogy rendelkezünk egy szóválasztási modellel, használjuk fel azt az eltolási modell becslésére. Egy n hosszúságú angol mondat esetén, amely egy m hosszúságú francia mondathoz illeszkedik, vegyük minden egyes francia szót (i pozícióban) és minden olyan angol szót (j pozícióban), amely valószínű választás lenne a francia szóra, és vegyük ezt P(Eltolás = i – j|i, n, m) bizonyítékául.
A becslések javítása: használjuk az EM (elvárásmaximalizáló) algoritmust a becslések javítására. A rejtett változó az illeszkedő mondatpárok közti szóilleszkedési vektor (word alignment vector). A vektor megadja minden egyes angol szóra a megfelelő francia szó francia mondatbeli pozícióját. Például megkaphatjuk a következőt:

Először a paraméterek aktuális becslőit használva elkészítjük a szóilleszkedési vektort mindegyik mondatpárra. Ez jobb becslő megalkotását fogja számunkra lehetővé tenni. A termékenységi modellt az alapján becsüljük, hogy a szóilleszkedési vektor egy adott tagja hányszor képződik le több szóra, vagy egyetlenegyre sem. A szóválasztási modellnek a mondat összes szava helyett most már csak olyan szavakat kell figyelembe vennie, amelyek egymáshoz lettek illesztve. Az eltolási modell a mondat egyes pozícióinak elmozdulását vizsgálja a szóilleszkedési vektornak megfelelően. Sajnos nem tudjuk, hogy mi a helyes illeszkedés, és túl sok van belőlük ahhoz, hogy mindet felsoroljuk. Emiatt arra vagyunk kényszerítve, hogy megkeressünk néhány nagy valószínűségű illeszkedést, és a valószínűségükkel súlyozzuk őket, miközben bizonyítékot gyűjtünk az új paraméterbecslőkhöz. Mindössze ennyire van szükségünk az EM algoritmushoz. A kezdeti paraméterek alapján illeszkedéseket számolunk, majd az illeszkedések alapján javítjuk a paraméterbecslőket. Ismételjük, amíg konvergál.
[252] A fejezet első bekezdésének eredeti angol szövege: In Chapter 22, we saw how an agent could communicate with another agent (human or software), using utterances in a common language. Complete syntactic and semantic analysis of the utterances is necessary to extract the full meaning of the utterances, and is possible because the utterances are short and restricted to a limited domain. Látható, hogy a két angol nyelvű szöveg között jelentős eltérések vannak, azonban a gépi fordítás eredményeként kapott szöveg nagyjából érthető. (A ford.)
[253] Martin Kay példája.
[254] Nyitva – Kinyitottunk (A ford.)
[255] doux – édes, enyhe, lágy, soft – lágy, sweet – édes, gentle – finom, gyengéd (A ford.)
[256] Mindkét esetben magyarul [S1 „és utána” S2] (A ford.)
[257] William Hansard után elnevezve, aki 1811-ben elsőként publikálta a brit parlamenti vitákat.
[258] Az angol nyelvű kiadás idején. (A ford.)
[259] Ebben a bekezdésben az angolról francia nyelvre történő fordítás problémájával foglalkozunk. Ne zavarja az olvasót, hogy a Bayes-szabály alkalmazása a P(E|F), és nem a P(F|E) figyelembe vételéhez vezet, ami annak tűnik, mintha franciáról fordítanánk angolra.
[260] Kattints ide (A ford.)
[261] Amennyiben csak 100 ezer szó fordulna elő a lexikonban, akkor az összes lehetséges háromszavas mondatok 99,99999%-ának előfordulási száma nulla lenne a 100 milliós korpuszban. Hosszabb mondatok esetén még rosszabb a helyzet.
[262] Eiffel-torony (A ford.)
[263] Világos, hogy a fordítás finomabb részleteihez P(fi|fi–1) nem elegendő. Híres példaként álljon itt Marcel Proust 3500 oldalas regénye, a „A la récherche du temp perdu”, amely ugyanazzal a szóval kezdődik és végződik, így egyes fordítók úgy döntöttek, hogy ugyanezt teszik, azaz egy szó fordítását egy olyan szóra alapozták, amely durván 2 millió szóval korábban fordult elő.
[264] a kutya (A ford.)
[265] barna kutya (A ford.)
[266] home – otthon, à la maison – otthon lenni, haza menni értelemben (A ford.)
[267] „à” – nagyjából a magyar -ban, -ben, -ba, -be ragoknak felel meg, „la” – nőnemű határozott névelő (A ford.)
[268] A barna kutya nem ment haza. (A ford.)
