18.4. Hipotézishalmaz együttes tanulása
Az eddigiekben olyan tanulási algoritmusokat vizsgáltunk, amelyek eredményeként a hipotézistérből kiválasztott egyetlen hipotézist használunk arra, hogy predikciót végezzünk. Az együttes tanulás (ensemble learning) alapötlete, hogy válasszunk ki a hipotézistérből egy teljes hipotéziskollekciót vagy hipotézisegyüttest (ensemble), és kombináljuk az általuk adott predikciókat. Generálhatunk például ugyanazon tanító halmaz alapján száz különböző döntési fát, és egy új példa esetén szavazással alakíthatjuk ki a legjobb predikciós osztályozási eredményt.
Az együttes tanulás motivációja kézenfekvő. Vizsgáljunk egy M = 5 hipotézisből álló együttest, és tegyük fel, hogy a predikciós eredményeket egyszerű többségi szavazással kombináljuk össze. Ahhoz, hogy az együttes rosszul osztályozzon egy új példát, legalább háromnak az öt hipotézisből rossz osztályozási eredményt kell adnia! Reményünk szerint ez sokkal kevésbé valószínű, mint az, hogy egyetlen hipotézis rossz osztályozásra jusson. Tegyük fel, hogy az együttes minden hi hipotézisének p a hibavalószínűsége, azaz p annak valószínűsége, hogy hi rosszul osztályoz egy véletlen módon kiválasztott példát. Továbbá tegyük fel, hogy a hipotézisek által elkövetett hibák függetlenek. Ez esetben – ha p kicsi – rendkívül kicsi a valószínűsége, hogy nagy számban történjék téves osztályozás. Egyszerű számítással (lásd 18.14. feladat) megmutatható például, hogy öt hipotézisből álló együttest használva a hibaarány 0,1-ről kevesebb mint 0,01-ra csökken. Valójában a függetlenség feltételezése nem racionális, mert a hipotéziseket a tanító halmaz félrevezető tulajdonságai hasonló módon vezetik félre. Mindamellett, ha a hipotézisek legalább kismértékben eltérőek, lecsökkentve a hibáik közti korrelációt, akkor az együttes tanulás nagyon hasznos lehet.
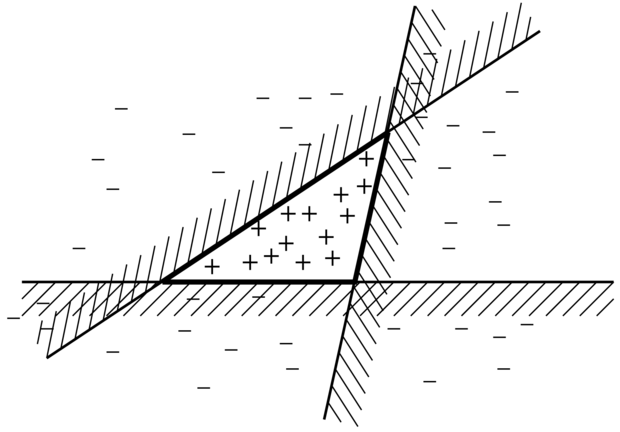
Az együttes tanulás tárgyalható más aspektusból is: gondolhatunk rá úgy, mint a hipotézistér egy általános kiterjesztésére. Tekintsünk úgy magára az együttesre, mint egy hipotézisre, és az új hipotézistér legyen mindazon lehetséges együttesek halmaza, amelyek az eredeti hipotézistérből konstruálhatók. A 18.8. ábra mutatja, hogyan eredményezhet ez egy sokkal kifejezőbb hipotézisteret. Ha az eredeti hipotézistér egyszerű és hatékony tanulási eljárást tett lehetővé, akkor az együttes tanulás módszere egy sokkal kifejezőbb hipotézisosztály tanulását biztosítja. Ennek általában nem túl nagy számítási és algoritmikus komplexitás növekedés az ára.
A legelterjedtebben használt együttes tanulási módszert turbózásnak (boosting) nevezzük. Ahhoz, hogy működését megértsük, be kell vezetnünk a súlyozott tanító halmaz (weighted training set) fogalmát. Egy ilyen tanító halmazban minden mintához hozzárendelünk egy wj ≥ 0 súlyt. Minél magasabb ez a súly, annál nagyobb jelentőséget tulajdonítunk az adott mintának a hipotézis tanulása során. Az eddigiekben áttekintett tanuló algoritmusaink kézenfekvő módon módosíthatók úgy, hogy súlyozott tanító halmazokkal is tudjanak működni.[185]
18.8. ábra - A együttes tanulás eredményeképpen nyert megnövekedett kifejezőerőt illusztráló példa. Három lineáris küszöb jellegű hipotézist vizsgálunk, mindegyik a nem vonalkázott félsíkon ad pozitív besorolást. Az együttesben csak arra adunk pozitív osztályozást, amelyre mindhárom pozitívat ad. Az eredményül kapott háromszögterület egy olyan hipotézisnek felel meg, amelyet az eredeti hipotézistér egyetlen eleme sem képes kifejezni.
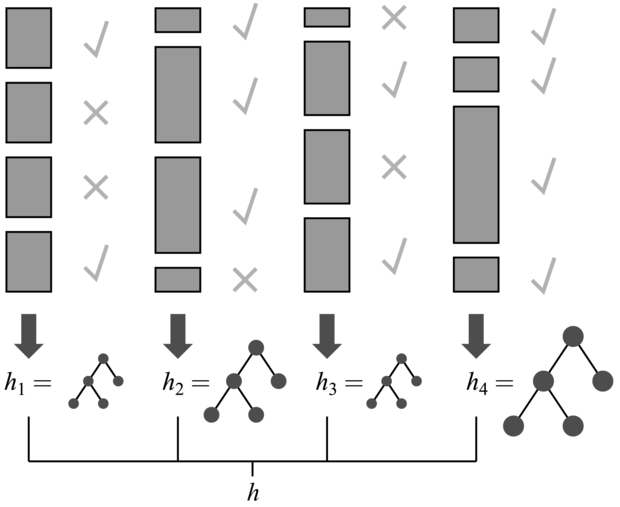
A turbózás az összes mintára wj = 1 értékkel (azaz egy normál tanító halmazzal) indul. Ebből a halmazból generálja az első hipotézist, h1-et. Ez a hipotézis egyes tanítómintákat jól osztályoz, másokat rosszul. Azt szeretnénk, ha a következő hipotézis jobb eredményt érne el a rosszul osztályozott mintákon, ezért megnöveljük a rosszul osztályozottak súlyait, míg a jól osztályozottakét csökkentjük. Ebből az új, súlyozott mintahalmazból generáljuk a h2 hipotézist. Az eljárást addig folytatjuk, míg M hipotézist nem generáltunk, ahol M a turbó tanulási algoritmus bemenő paramétere. Az algoritmus eredményeként kapott hipotézis együttes nem más, mint az M hipotézis súlyozott többségi szavazással kombinált eredője. A súlyokat aszerint határozzuk meg, hogy az egyes hipotézisek mennyire jól teljesítettek a tanító halmazon. A 18.9. ábrán bemutatjuk az algoritmus koncepcióját. Sok variánsa ismert a turbó tanulásnak, eltérő súlymódosítással, illetve a hipotézisek különböző kombinálási lehetőségeivel. Egy kiválasztott – ADABOOST nevű – algoritmust mutatunk be a 18.10. ábrán. Az alkalmazott súlymódosítási eljárás jelen esetben nem túl lényeges, viszont az ADABOOST algoritmusnak van egy nagyon lényeges jellemzője. Tegyük fel, hogy a használt L tanulási algoritmus egy gyenge tanulási (weak learning) algoritmus, ami azt jelenti, hogy L mindig visszaad egy olyan hipotézist, amelyik legalább egy csöppet jobban teljesít a tanító halmaz súlyozott hibájára nézve, mint a véletlen találgatás (azaz eredménye jobb mint 50% bináris osztályozás esetén). Ez esetben, kellően nagy M-re az ADABOOST mindig előállít egy olyan hipotézist, amely a tanító mintákat tökéletesen osztályozza! Tehát az algoritmus fokozza az eredeti tanuló eljárásnak a tanító mintán mért pontosságát. Ez mindig fennáll, attól függetlenül, hogy esetleg mennyire kevéssé kifejező az eredeti hipotézistér, és mennyire bonyolult a keresett függvény.
18.9. ábra - A turbó algoritmus működése. Mindegyik árnyékolt téglalap egy példának felel meg, a téglalap magassága mutatja a példa súlyát. A pipák és keresztek mutatják, hogy a példát jól vagy rosszul osztályoztuk a pillanatnyi hipotézis alapján. A döntési fa mérete mutatja, hogy ennek a hipotézisnek mekkora a súlya a végső együttesben.
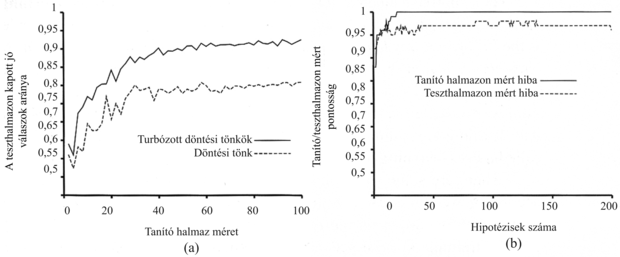
Vizsgáljuk meg, hogy mennyire jól működik a turbózás az éttermi adatainkon. Kiinduló hipotézistérként az úgynevezett döntési tönkök (decision stumps) terét választjuk, amelyek olyan döntési fák, amelyek csupán egy – a gyökércsomópontban elhelyezkedő – tesztből állnak. A 18.11. (a) ábra alsó görbéje mutatja, hogy turbózás nélkül ezek a döntési tönkök nem adnak valami jó eredményt, csupán 81%-os a 100 mintán mért predikciós teljesítményük. Amikor turbózást alkalmazunk (M = 5), akkor a teljesítmény javul, eléri a 93%-ot 100 példa esetén.
18.10. ábra - Az együttes tanulás turbó módszereinek
ADABOOST nevű variánsa. Az algoritmus hipotézisek kombinációját hozza létre. A SÚLYOZOTT-TÖBBSÉG egy hipotézist generál. Ez az új hipotézis azt a kimeneti értéket adja vissza, amely a h-ban található hipotézisek közül, a z-ben számon tartott súlyozással a legtöbb szavazatot kapta.
Fontos
Érdekes dolog történik, amikor az együttes M mérete növekszik. A 18.11. (b) ábra mutatja a tanító halmazon mért teljesítményt M függvényében. Figyeljük meg, hogy M = 20-nál a hiba eléri a nullát (ahogy a turbózással foglalkozó elmélet megjósolta), azaz 20 döntési tönk súlyozott többségi szavazással összefogott kombinációja elégséges a 100 mintára való pontos illeszkedéshez. Ha további tönköket adunk az együtteshez, akkor a hiba nulla marad. A görbe mutatja ugyanakkor, hogy a teszthalmazon mért teljesítmény még hosszasan nő azután is, hogy a tanító halmazon mért hiba elérte a nullát. M = 20 esetén a teszthalmazon mért teljesítmény 0,95 (a hiba 0,05), M = 137-ig növelve az együttes résztvevőinek számát a teljesítmény 0,98-ra nő, ezután leesik 0,95-re.
Ez a megfigyelés, amely különböző mintahalmazokra és hipotézisterekre nézve meglehetősen robusztusnak bizonyult, nagy meglepetést keltett a felfedezésekor. Az Ockham borotvája elv azt sugallja, hogy ne tegyük a hipotéziseket komplexebbé, mint szükséges, de a görbe azt mutatja, hogy a predikciók javulnak, ahogy az együttes hipotézis összetettebbé válik! Számos magyarázatot javasoltak erre a jelenségre. Az egyik megközelítés szerint a turbózás nem más, mint a Bayes-tanulás közelítése (lásd 20. fejezet), amely egy bizonyíthatóan optimális tanulási eljárás. Ez a közelítés javul, ahogy több és több hipotézist adunk az együtteshez. Másik lehetséges magyarázat, hogy további hipotéziseknek az együtteshez adása lehetővé teszi, hogy határozottabb legyen a megkülönböztetés a pozitív és negatív példák között, ami segít az új minták osztályozásában.
18.11. ábra - (a) A döntési tönkök és a turbózott döntési tönkök teljesítményének az étterem példán történő összehasonlítása M = 5 esetén. (b) A tanító halmazon és a teszthalmazon kapott jó válaszok aránya M-nek – az együttesben található hipotézisek számának – a függvényében. Figyeljük meg, hogy a teszthalmazon mért pontosság még azután is javul egy kicsit, amikor a tanító halmazon elérte az 1-et, azaz miután az együttes pontosan illeszkedett az adatokra.
[185] Azon tanulási eljárásokra, ahol ez nem lehetséges, ismétléses tanító halmazt (replicated training set) hozhatunk létre, ahol a j-edik minta a wj súllyal arányos példányszámban szerepel. Az esetleges nem egész súlyokat úgy kezelhetjük, hogy a mintaszámot valószínűségi változóként fogjuk fel.
