4.1. Informált (heurisztikus) keresési stratégiák
Ez a fejezet megmutatja, hogy az informált keresési (informed search) stratégia – amely a probléma definícióján túlmenően problémaspecifikus tudást is felhasznál – hogyan képes hatékonyabban megtalálni a megoldást.
Az általunk vizsgált általános megközelítést a legjobbat-először keresésnek (best-first search) nevezzük. A legjobbat-először keresés az általános FA-KERESÉS vagy GRÁF-KERESÉS algoritmusok olyan speciális esete, ahol egy csomópont kifejtésre való kiválasztása egy f(n) kiértékelő függvénytől (evaluation function) függ. Hagyományosan a legkisebb értékű csomópontot választjuk kifejtésre, mert a kiértékelő függvény a céltól való távolságot méri. A legjobbat-először keresés az eddigi általános keresési eljárások keretein belül egy prioritási sor segítségével implementálható, ami egy olyan adatstruktúra, mely a peremet a növekvő f-értékek szerint rendezi.
A legjobbat-először keresés egy nagy múltú, azonban pontatlan elnevezés. Amenynyiben valóban képesek lennénk a legjobb csomópontot kifejteni, akkor egyáltalán nem kellene keresnünk, nyílegyenesen elmasíroznánk a célhoz. Ezzel szemben csak a kiértékelő függvény szerint legjobbnak tűnő csomópontot tudjuk kiválasztani. Ha kiértékelő függvényünk mindentudó, akkor a kiválasztott csomópont egyben a legjobb csomópont is. A valóságban azonban a kiértékelő függvény néha pontatlan, és félrevezetheti a keresést. Azonban a továbbiakban is ragaszkodni fogunk a legjobbat-először keresés elnevezéshez, mert a legjobbnak tűnőt először keresés egy kicsit furcsán hangzana.
A LEGJOBBAT-ELŐSZÖR-KERESÉS algoritmus tulajdonképpen egy keresési algoritmus család, amelynek az elemeit az eltérő kiértékelő függvények[33] különböztetik meg. Ezeknek az algoritmusoknak a kulcseleme a h(n)-nel jelölt heurisztikus függvény[34] (heuristic function):
h(n) = az n csomóponttól a célig vezető legolcsóbb út becsült útköltsége
Például Romániában az Arad és Bukarest közötti legolcsóbb út költségét az Arad és Bukarest közötti légvonaltávolsággal meg lehetne becsülni.
A heurisztikus függvény a leginkább megszokott módja annak, hogy a problémára vonatkozó pótlólagos tudást a keresési algoritmusba be tudjuk injektálni. A heurisztikus függvényekkel részletesen a 4.2. alfejezetben foglalkozunk. Egyelőre tetszőleges, ám problémaspecifikus függvényeknek fogjuk őket tekinteni, egy kikötéssel: ha n egy célállapot, akkor h(n) = 0. A jelen fejezet hátralévő része két olyan utat mutat be, ahol a heurisztikus információt a keresés irányítására használjuk fel.
A mohó legjobbat-először keresés[35] (greedy best-first search) azt a csomópontot fejti ki a következő lépésben, amelyiknek az állapotát a legközelebbinek ítéli a célállapothoz, abból kiindulva, hogy így gyorsan megtalálja a megoldást. A csomópontokat az algoritmus tehát az f(n) = h(n) heurisztikus függvénnyel értékeli ki.
Nézzük meg, hogy hogyan működik ez a romániai útkeresésnél a légvonalban mért távolságot (straight-line distance) felhasználva, amit hLMT-vel fogunk jelölni. Ha a cél Bukarest, szükségünk lesz Bukarest légvonalbeli távolságaira, amelyeket a 4.1. ábra ad meg. Például hLMT(Benn(Arad)) = 366. Vegyük észre, hogy a hLMT értékeit magának a problémának a leírásából kiszámítani nem lehet. Továbbá egy kis tapasztalat is szükséges ahhoz, hogy rájöjjünk, hogy a hLMT az úton megtett tényleges távolsággal korrelál, és így számunkra hasznos heurisztika lehet.
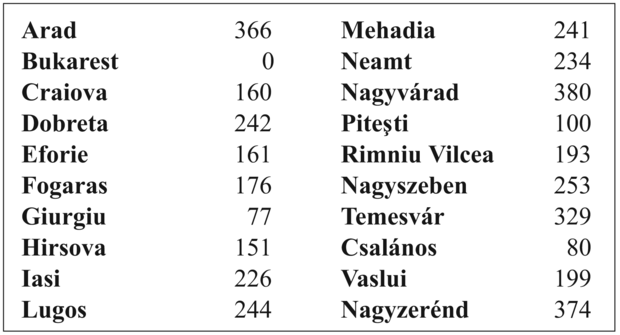
A 4.2. ábra egy Aradról Bukarestbe vezető út mohó legjobbat-először keresését mutatja, hLMT-t alkalmazva. Aradból az első kifejtett csomópont Nagyszeben, mert ez közelebb van Bukaresthez, mint Nagyzerénd vagy Temesvár. A következő kifejtendő csomópont pedig Fogaras, mert az van a legközelebb. Fogaras majd generálja Bukarestet, ami egyben a célállapot. Erre a konkrét problémára a hLMT -t alkalmazó mohó legjobbat-először keresés úgy talál megoldást, hogy soha sem fejt ki olyan csomópontot, ami nem a megoldási úton fekszik. Következésképpen minimális a keresési költsége. Azonban nem optimális: a Nagyszebenen és Fogarason keresztül Bukarestbe vezető út 32 kilométerrel hosszabb a Rimnicu Vilceán és Piteştin keresztül vezető útnál. Ebből látszik, hogy az algoritmus miért „mohó” – minden lépésben igyekszik annyira közel kerülni a célhoz, ahogy csak lehet.
4.2. ábra - A mohó legjobbat-először keresés lépései Bukarest esetén a légvonalban mért távolságot (hLMT) alkalmazva. A csomópontok a saját h-értékeikkel vannak felcímkézve.
A h(n) minimalizálása érzékeny a hibás kezdő lépésekre. Tekintsük például azt az esetet, amikor Iaşiról Fogarasra akarunk eljutni. A heurisztika alapján Neamtot kellene először kifejteni, hiszen ez fekszik Fogarashoz a legközelebb, azonban ez zsákutca. A megoldás, hogy először elmegyünk Vasluira – egy olyan lépést teszünk, ami a heurisztika szerint a céltól távolabb visz – és aztán elmegyünk Csalánosra, Bukarestre, majd Fogarasra. Ebben az esetben a heurisztika szükségtelen csomópontok kifejtését eredményezi. Továbbá, ha nem ügyelünk arra, hogy felismerjük az ismétlődő állapotokat, akkor soha nem találjuk meg a megoldást – a keresés Neamt és Iaşi között fog oszcillálni.
A mohó legjobbat-először keresés a mélységi keresésre hasonlít abból a szempontból, hogy egyetlen út végigkövetését preferálja a célig, azonban zsákutcába jutva visszalép. Ugyanazokkal a problémákkal küszködik, mint a mélységi keresés – nem optimális és nem teljes (mert elindulhat egy végtelen úton és soha sem tér vissza újabb lehetőségeket kipróbálni). A mohó keresés legrosszabb esetre számított (worst-case) idő- és tárigénye O(bm), ahol m a keresési tér maximális mélysége. Jól megválasztott heurisztikus függvénnyel a komplexitás azonban jelentősen csökkenthető. A csökkenés mértéke az adott problémától és a heurisztikus függvény minőségétől függ.
A legjobbat-először keresés leginkább ismert változata az A* keresés (a kiejtése ’A csillag’). A csomópontokat úgy értékeli ki, hogy összekombinálja g(n) értékét – az aktuális csomópontig megtett út költsége – és h(n) értékét – vagyis az adott csomóponttól a célhoz vezető út költségének becslőjét:
f(n) = g(n) + h(n)
Mivel g(n) megadja a kiinduló csomóponttól az n csomópontig számított útköltséget, és h(n) az n csomóponttól a célcsomópontba vezető legolcsóbb költségű út költségének becslője, így az alábbi összefüggést kapjuk:
f(n) = a legolcsóbb, az n csomóponton keresztül vezető megoldás becsült költsége.
Így amennyiben a legolcsóbb megoldást keressük, ésszerű először a legkisebb g(n) + h(n) értékkel rendelkező csomópontot kifejteni. Ezen stratégia kellemes tulajdonsága, hogy ez a stratégia több mint ésszerű: amennyiben a h függvény eleget tesz bizonyos feltételeknek, az A* keresés teljes és optimális.
Az A* optimalitását könnyű elemezni, ha az algoritmust a FA-KERESÉS-sel együtt alkalmazzuk. Ilyenkor A* optimális lesz, ha h(n) egy elfogadható heurisztika (admissible heuristic), azaz ha h(n) soha nem becsüli felül a cél eléréséhez szükséges költséget. Az elfogadható heurisztikák természetükből adódóan optimisták, mivel úgy gondolják, hogy a probléma megoldása kisebb költséggel jár, mint amekkora költséget a megoldás valójában igényel. Mivel g(n) az n csomópont elérésének pontos költsége, azonnali következményként adódik, hogy f(n) soha sem becsüli túl az n csomóponton keresztül vezető legjobb megoldás valódi költségét.
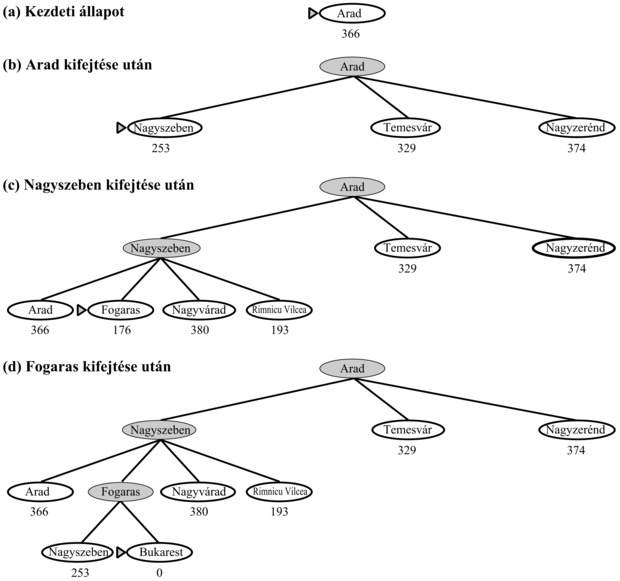
Az elfogadható heurisztikus függvények talán egyik legnyilvánvalóbb példája a Bukarestbe történő utazás során felhasznált hLMT légvonalban mért távolság. A légvonalban mért távolság elfogadható, mert bármely két pont között a legrövidebb távolság a légvonalban mért távolság, így a légvonalbeli táv soha nem becsülhet túl. A 4.3. ábra a Bukarestet kereső A* fakeresés előrehaladását mutatja. A g értékeket a 3.2. ábrán látható lépésköltségekből számítjuk ki, a hLMT értékei a 4.1. ábrán adottak.
Fontos
Vegyük észre, hogy Bukarest először az (e) lépés peremében jelent meg, azonban kifejtésre nem került, mert Bukarest f-értéke (450) magasabb, mint Piteştié (417). Ezt úgy lehetne megmagyarázni, hogy lehet, hogy Piteştin keresztül létezik egy 417 költségű olcsó megoldás, így az algoritmus egy 450 költségű megoldást nem fog választani. Ebből a példából megalkothatjuk annak az általános bizonyítását, hogy a FA-KERESÉS-t használó A* algoritmus optimális, ha h(n) elfogadható. Tegyük fel, hogy a peremen egy G2 szuboptimális célcsomópont jelenik meg, és az optimális megoldás költsége legyen C*. Így mivel G2 szuboptimális és h(G2) = 0 (ami minden célállapotra igaz), tudjuk, hogy:
f(G2) = g(G2) + h(G2) = g(G2) > C*
Gondoljunk most egy perembeli n csomópontra, amely a megoldási útvonalon fekszik (ilyennek mindig léteznie kell, ha a megoldás létezik). Ha h(n) nem becsüli túl a megoldáshoz vezető út folytatását, akkor tudjuk, hogy:
f(n) = g(n) + h(n) ≤ C*
Kimutattuk tehát, hogy f(n) ≤ C* < f(G2), így G2 nem kerül kifejtésre, és az A* egy optimális megoldással tér vissza.
A bizonyítás összeomlik, ha a FA-KERESÉS helyett a 3.19. ábra szerinti GRÁF-KERESÉS algoritmust használjuk. Az algoritmus visszatérhet szuboptimális megoldással, mert a GRÁF-KERESÉS algoritmus elvetheti az ismétlődő állapothoz vezető optimális utat, ha az nem elsőnek került kiszámításra (lásd 4.4. feladat). A problémát kétféle módon lehet megoldani. Az első megoldás a GRÁF-KERESÉS olyan kiterjesztése, hogy az az ugyanahhoz a csomóponthoz vezető két út közül a drágábbat fogja elvetni (lásd az értékelést a 3.5. alfejezetben). A pótlólagos adminisztrálás nem egyszerű, de az optimalitást garantálni fogja. A második megoldásnál azt kell biztosítani, hogy a bármelyik ismétlődő csomóponthoz vezető optimális út mindig az, amit az algoritmus elsőnek követ – mint ahogy ez az egyenletes költségű keresésénél volt. Ez a tulajdonság akkor áll fenn, ha a h(n) függvényre extra követelményeket fogalmazunk meg, megkövetelve annak konzisztenciáját (consistency), másképpen monotonitását (monotonicity). A h(n) heurisztikus függvény konzisztens, ha minden n csomópontra és annak egy tetszőleges a cselekvéssel generált minden n′ utódcsomópontjára az n csomóponttól elért cél becsült költsége nem kisebb, mint az n′ -be kerülés lépésköltsége és az n′ csomóponttól elért cél becsült költsége:
h(n) ≤ c(n, a, n′) + h(n′)
Ez az általános háromszög egyenlőtlenség (triangle inequality) egy formája, amely azt fejezi ki, hogy egy háromszög egy oldala sem lehet hosszabb, mint a két másik oldal összege. Itt a háromszöget az n, az n′ és az n-hez legközebbi cél határozza meg. Könnyű megmutatni (4.7. feladat), hogy minden konzisztens heurisztika egyben elfogadható is.
Fontos
A konzisztencia legfontosabb következménye az, hogy: a GRÁF-KERESÉS-t használó A* algoritmus optimális, ha h(n) konzisztens.
4.3. ábra - Az A* keresés lépései Bukarest keresése során. A csomópontok az f = g + h értékekkel vannak felcímkézve. A h-értékek a Bukaresttől légvonalban mért távolságokat jelölik, melyeket a 4.1. ábrából vettünk át.
Bár a konzisztencia az elfogadhatóságnál szigorúbb követelmény, igazán nehéz olyan elfogadható heurisztikát találni, ami nem lenne egyben konzisztens. Az ebben a fejezetben tárgyalt összes elfogadható heurisztika mind konzisztens. Vegyük például a hLMT-t. Tudjuk, hogy az általános háromszög egyenlőtlenség teljesül, ha az oldalakat egyenes vonalú távolságokkal mérjük, és hogy az n és n′ közötti egyenesvonalú távolság c(n, a, n′)-nél nem nagyobb. A hLMT így egy konzisztens heurisztika.
Fontos
A konzisztencia egy másik fontos következménye az, hogy ha h(n) konzisztens, akkor az f(n) értékek akármilyen út mentén nem csökkennek. A bizonyítás bizonyos a mellett közvetlenül következik a konzisztencia definíciójából. Tegyük fel, hogy n′ az n utódja, ekkor:
g(n′) = g(n) + c(n, a, n′)
és
f(n′) = g(n′) + h(n′) = g(n) + c(n, a, n′) + h(n′) ≥ g(n) + h(n) = f (n)
A GRÁF-KERESÉS-t használó A* algoritmus által kifejtett csomópontok sorozata tehát f(n)-ben nem csökkenő. A kifejtésre választott első célcsomópont így egy optimális megoldás is egyben, mert minden utána következő csomópont legalább ilyen költséges lenne.
Ha az f-költségek sohasem csökkenek, bármilyen utat választunk, akkor az állapottérben határvonalakat (contour) húzhatunk be, hasonlóan egy topografikus térkép kontúrjaihoz. A 4.4. ábra erre mutat egy példát. A 400-zal felcímkézett határvonalon belül az összes csomópont f(n) értéke nem nagyobb 400-nál, és hasonló érvényes a többire is. Mivel az A* keresési algoritmus a legkisebb f értékkel rendelkező levélcsomópontot fejti ki először, láthatjuk, hogy az A* keresési algoritmus a gyökércsomópontból legyezőszerűen halad kifelé, növekvő f értékekhez tartozó koncentrikus sávokban hozzáadva a csomópontokat.
Az egyenletes költségű keresés esetén (A* keresés h = 0 mellett) a csomópontsávok a kiinduló csomópont köré húzott koncentrikus „köröket” alkotnak. Pontosabb heurisztikus függvény alkalmazásával a sávok a célállapot felé elnyúlnak, és keskenyebben fókuszálódnak az optimális út körül. Ha C* az optimális megoldási út költségét jelöli, akkor az alábbiakat jelenthetjük ki:
-
Az A* keresési algoritmus kifejti az összes f(n) < C* értékkel rendelkező csomópontot.
-
Ezek után az A* keresési algoritmus egy célcsomópont kiválasztása előtt még kifejthet néhány csomópontot a „célhatárvonalon”, amelyekre f(n) = C*.
Intuitíven nyilvánvaló, hogy az első megtalált megoldásnak optimális megoldásnak kell lennie, hiszen a következő határvonalakon az összes csomóponthoz nagyobb f költség, ebből adódóan nagyobb g költség tartozik (mivel minden célállapotra h(n) = 0). Intuitíven az is nyilvánvaló, hogy az A* keresési algoritmus teljes. Ahogy egyre növekvő f értékű sávokat adunk a kereséshez, előbb-utóbb elérünk egy sávot, amelyhez tartozó f érték megegyezik egy célállapothoz vezető út költségével.[36]
4.4. ábra - Románia térképe. Az ábra Arad mint kiinduló állapot esetén az f = 380, f = 400 és f = 420 értékekhez tartozó határvonalat mutatja. Egy adott határvonalon belüli csomópontokhoz a határvonal értékénél kisebb f költség tartozik.
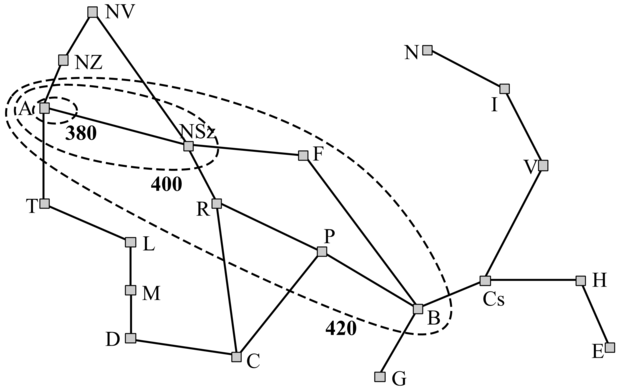
Vegyük észre, hogy az A* nem fejt ki f(n) > C* tulajdonságú csomópontokat. A 4.3. ábrán például Temesvár nem kerül kifejtésre annak ellenére, hogy ez a gyökérnek egy utódcsomópontja. Azt mondjuk, hogy a Temesvár alatti fát lenyestük (pruned). Mivel hLMT elfogadható, az algoritmus biztonságosan figyelmen kívül hagyhat egy ilyen fát, miközben az optimalitást garantálja. A nyesés gondolata – a lehetőségek eliminálása anélkül, hogy megvizsgálnánk azokat – igen fontos az MI sok területén.
Egy végső észrevétel, az ilyen típusú – a gyökérből kiinduló utakat bővítő – optimális algoritmusok közül az A* keresési algoritmus bármely adott heurisztikus függvény mellett optimális hatékonyságú (optimally efficient). Ez azt jelenti, hogy egyetlen más optimális algoritmus sem fejt ki garantáltan kevesebb csomópontot, mint az A* (kivéve talán az f(n) = C* típusú csomópontok körét, ahol holtverseny alakulhat ki). Ez azért van, mert az összes olyan algoritmus, amelyik nem fejti ki az összes csomópontot, melyre f(n) < C*, kockáztatja az optimális megoldás elkerülését.
Felettébb örömteli hír számunkra, hogy az A* keresési algoritmus teljes, optimális és az összes ilyen jellegű algoritmus között optimálisan hatékony. Sajnos ez azonban nem jelenti azt, hogy az A* algoritmus megoldja az összes kereséssel kapcsolatos problémánkat. A buktató a dologban az, hogy a legtöbb probléma esetén a csomópontok száma a keresési tér célhatárvonalon belüli részén a megoldás hosszának még mindig exponenciális függvénye. Bár az eredmény bizonyítása túlmutat ezen könyv keretein, megmutatható, hogy az exponenciális növekedéssel mindenképp szembe kell néznünk, kivéve, ha a heurisztikus függvényünk hibája legfeljebb az aktuális útköltség logaritmusával nő. Az exponenciálisnál lassabb növekedés feltétele matematikai megfogalmazásban:
|h(n) – h*(n)| ≤ O(log h*(n))
ahol h*(n) az n csomópontból a célcsomópontba való eljutás valódi költségét jelöli. Majdnem minden, a gyakorlatban használt heurisztikus függvény esetén a hiba legalább arányos az útköltséggel, és az ebből adódó exponenciális növekedéssel egyetlen számítógép sem tud megbirkózni. Ezért ahhoz ragaszkodni, hogy egy optimális megoldást találjunk, gyakran nem is praktikus. Használhatjuk az A* olyan változatát, amely a szuboptimális megoldásokat gyorsan megtalálja, vagy pedig dolgozhatunk pontosabb, de nem elfogadható heurisztikákkal. Egy jól megválasztott heurisztikus függvény ettől függetlenül a nem informált keresési algoritmusokhoz képest jelentős megtakarítást eredményezhet. A 4.2. alfejezetben megvizsgáljuk, hogy hogyan is lehet jó heurisztikus függvényt tervezni.
Az A* algoritmusnak azonban nem a szükséges számítási idő a nagy problémája. Mivel az összes legenerált csomópontot a memóriában tárolja (ahogy ezt az összes GRÁF-KERESÉS algoritmus teszi), ezért az algoritmus általában lényegesen hamarabb felemészti a rendelkezésére álló memóriát, mintsem kifutna az időből. Ezért az A* sok nagyméretű problémához nem praktikus. A közelmúltban kifejlesztett algoritmusok a végrehajtási idő kismértékű növekedése mellett a memóriaproblémát megoldották, anélkül hogy feláldoznák az optimalitást vagy a teljességet. Ezekkel az algoritmusokkal fogunk most foglalkozni.
Az A* memóriaigényének mérséklésére a legegyszerűbb módszer az iteratívan mélyülő algoritmus adaptálása heurisztikus keresés környezetre. Ennek eredménye az iteratívan mélyülő A* algoritmus – IMA* – (iterative deepening A*, IDA*). Az IMA* és a közönséges iteratívan mélyülő algoritmus közötti fő különbség az, hogy a vágási mechanizmus nem a mélységen, hanem az f költségen (g + h) alapul. Ezáltal minden egyes iterációban a vágási érték az a legkisebb f költség, ami az előbbi iterációban használt vágási értéknél nagyobb. Az IMA* praktikus megoldás számos olyan probléma esetén, ahol egységnyi a lépésköltség és elkerüli a rendezett csomópontsor memóriában való tartásának jelentős overheadjét. Sajnos, az IMA* algoritmus a valós értékű költségektől ugyanúgy szenved, mint az egyenletes költségű keresés iteratív változata, amit a 3.11. feladatban írtunk le. Ebben a fejezetben megvizsgálunk a memóriakorlátozott algoritmusok köréből két frissebb ötletet – az RLEK-t és az MA*-t.
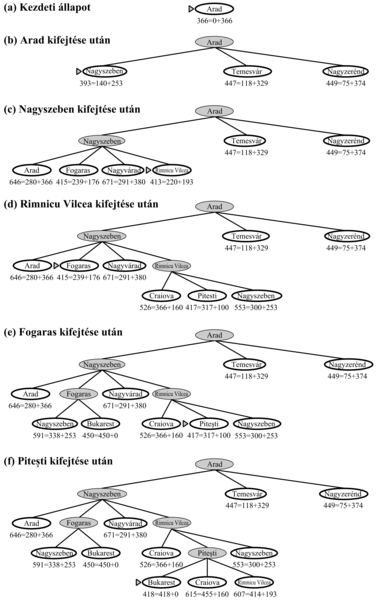
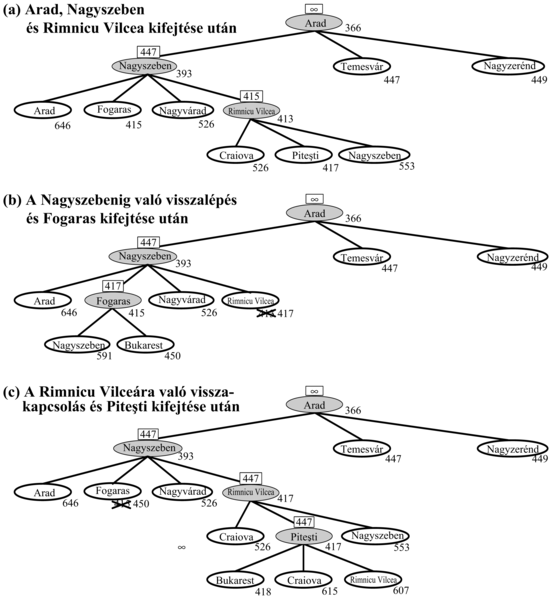
A rekurzív legjobbat-először keresés, az RLEK (recursive best-first search, RBFS) egy egyszerű rekurzív algoritmus, amely megkísérli a rendes legjobbat-először algoritmus működését mímelni, de csak lineáris tárat használva. Az algoritmust a 4.5. ábra mutatja. A struktúrája hasonlít a rekurzív mélységi keresésre, azonban ahelyett, hogy az algoritmus egy utat a végtelenségig folytatna az aktuális pálya mentén, figyeli az aktuális csomóponthoz az elődeitől vezető eddigi legjobb alternatív út f-értékét. Ha az aktuális csomópont ezt az értéket túlhaladja, a rekurzió az alternatív útra lép vissza. Ahogy a rekurzió visszalép, az RLEK minden csomópont f-értékét a pálya mentén a gyerekeinek legjobb f-értékével helyettesíti. Ily módon az RLEK emlékszik a legjobb levélértékre az elfelejtett alfában, és eldöntheti, vajon érdemes-e ezt a fát valamikor később újra kifejteni. A 4.6. ábra azt mutatja, hogy hogyan éri el Bukarestet az RLEK.
Az RLEK valamivel hatékonyabb, mint az IMA*, azonban még mindig túlságosan szenved a csomópontok túlzott újbóli generálása miatt. A 4.6. ábrán látható példában az RLEK először a Rimnicu Vilceán átmenő utat követi, majd „meggondolja magát” és Fogarassal kísérletezik, majd újra meggondolja magát. Ezek a meggondolások azért történnek meg, mert amikor az aktuális legjobb utat tovább fejtjük, nagy az esély arra, hogy az f-érték nőni fog – h általában kevésbé optimista a célhoz közeli csomópontok esetén. Amikor ez megtörténik, különösképpen nagy keresési terekben, a második legjobb út a legjobb úttá válhat, és a keresésnek vissza kell lépnie, hogy ezt az utat tudja követni. Minden meggondolás megfelel az IMA* egy-egy iterációjának és az elfelejtett csomópontok számos újbóli kifejtését teszi szükségessé, hogy a keresés képes legyen a legjobb utat visszaállítani, és azt egy csomóponttal meghosszabbítani.

Az A*-hoz hasonlóan az RLEK is optimális algoritmus, feltéve, hogy a h(n) heurisztikus függvény elfogadható. Tárkomplexitása O(bd), az időkomplexitását azonban nehezebb meghatározni. Ez függ a heurisztika pontosságától és attól is, mennyire gyakran változik a csomópontok kifejtése közben a legjobb út. Mind az IMA*, mind az RLEK elvileg ki vannak téve a gráfokban való kereséssel kapcsolatos exponenciális komplexitásnövekedésnek (lásd 3.5. alfejezet), tekintettel arra, hogy az ismétlődő állapotok jelenlétét csak az aktuális úton képesek ellenőrizni. Előfordulhat így, hogy ugyanazt az állapotot többször is kifejtik.
Az IMA*-nak és az RLEK-nek az a baja, hogy túl kevés memóriát használ. Az egyes iterációk között az IMA* egyetlen számot, az aktuális f-költség korlátot tárolja el. Az RLEK több információt tárol el a memóriában, azonban csak O(bd) memóriát használ. Még ha több memória is állna a rendelkezésére, az RLEK-nek nincs módja ezt kihasználni.
Ésszerűnek tűnik tehát az összes, rendelkezésre álló memóriát használni. Az erre képes két algoritmus az MA* (memóriakorlátozott A*) és az EMA* (egyszerűsített MA*). Itt az EMA*-t írjuk le, ami – mitagadás – az egyszerűbb. Az EMA* az A* módjára halad a legjobb levelet kifejtve, amíg a memória be nem telik. Ezen a ponton a keresési fához új csomópontot hozzáadni nem képes, hacsak egy régit nem töröl ki. Az EMA* mindig a legrosszabb – a legmagasabb f-értékű – csomópontot hagyja ki. Majd, mint az RLEK, az elfelejtett csomópont értékét a szülőjéhez továbbítja. Ily módon egy elfelejtett részfa elődje tudja a részfa legjobb útjának az értékét. Ezzel az információval az EMA* csak akkor fejti ki újra a fát, ha kimutatta, hogy minden más út rosszabbnak tűnik, mint az elfelejtett út. Más szóval, ha az n csomópont minden utódját elfelejtjük, nem tudjuk, hogy n-ből merrefelé lehetne menni, tudni fogjuk azonban, hogy mennyire érdemes egyáltalán bárhová is menni az n-ből kiindulva.
4.6. ábra - Az RLEK lépései, miközben a legrövidebb utat keresi Bukarest felé. A mindenkori rekurzív hívás f-korlát értéke a mindenkori aktuális csomópont felett látható. (a) A Rimnicu Vilceán át vezető utat az algoritmus addig követi, amíg az aktuális legjobb levél (Piteşti) értéke nem lesz rosszabb, mint a legjobb alternatív út értéke (Fogaras). (b) A rekurzió visszalép és az elfelejtett alfa legjobb levélértékét (417) Rimnicu Vilceánál feljegyezzük. Majd Fogaras kifejtése következik 450-nel, mint a legjobb levélértékkel. (c) A rekurzió visszalép. Az elfelejtett alfa legjobb levélértékét (450) Fogarasnál jegyezzük fel. Következik Rimnicu Vilcea kifejtése. Ezúttal, mivel a legjobb alternatív út (Temesváron keresztül) 447-be kerül, a kifejtés folytatódik Bukarest felé.
A teljes algoritmus túlságosan bonyolult, hogy itt írjunk róla,[37] azonban egy finom vonását érdemes megemlíteni. Azt mondtuk, hogy az EMA* a legjobb levelet fejti ki és a legrosszabb levelet felejti el. Mi van akkor, ha minden levélnek ugyanaz az f-értéke? Az algoritmus ekkor ugyanazt a csomópontot kifejtésre is, és elhagyásra is kiválaszthatná. Az EMA* ezt a problémát úgy oldja meg, hogy a kifejtésre a legújabb csomópontot választja, és a legrégebbi csomópontot törli. Ez a kettő ugyanaz a csomópont csak akkor lehet, ha csak egy levél van. Ebben az esetben az aktuális keresési fa egyetlen útból áll a gyökértől a levélig, ami kitölti a teljes memóriát. Ha a levél nem egy célcsomópont, akkor még ha a célhoz vezető optimális úton fekszik is, ez a cél az adott memóriával nem érhető el. Következésképpen a csomópontot ugyanúgy el lehet dobni, mintha nem is lenne követője.
Az EMA* teljes, ha van egyáltalán elérhető megoldás – azaz ha D, a legsekélyebb célcsomópont mélysége kevesebb, mint a memória nagysága (csomópontokban kifejezve). Optimális, ha van elérhető optimális megoldás, másképpen az algoritmus a legjobb elérhető megoldással tér vissza. Gyakorlatilag az EMA*-t messze a legjobb általánosan használatos algoritmusnak lehet tekinteni az optimális megoldások megkeresésére, különösképpen ha az állapottér egy gráf, a lépésköltség nem egyenletes, és a csomópontkifejtés drága a nyitott és zárt listák karbantartásának pótlólagos overheadjéhez képest.
Fontos
Nagyon nehéz problémák esetén azonban az EMA* sokszor kénytelen folyamatosan oda-vissza kapcsolgatni a lehetséges megoldási utak között, amelyekből csak kevés fér be a memóriába (hasonló ez a diszkalapú memória lapozó rendszer vergődési (thrashing) problémájára). Az ugyanazon csomópontok ismételt újrakifejtéséhez szükséges extra idő azt jelenti, hogy azok a problémák, amelyeket a végtelen memóriájú A* gyakorlatilag meg tudna oldani, az EMA* számára kezelhetetlenek. Ez azt jelenti, hogy memóriakorlát a problémát a számítási idő szempontjából kezelhetetlenné teheti. Bár a memória és az idő közötti kompromisszum magyarázatára nincs elmélet, úgy tűnik, hogy ettől a problémától megmenekülni nem lehet. Egyetlen kiút elvetni az optimalitás követelményét.
Az eddigiekben néhány rögzített stratégiát mutattunk be – szélességi, mohó legjobbat-először stb. keresés –, amelyeket számítógépes szakemberek terveztek. Meg tudná-e tanulni egy ágens, hogy jobban keressen? A válasz igen, és a módszer alapját egy fontos fogalom, a metaszintű állapottér (metalevel state space) adja. A metaszintű állapottér minden állapota az objektumszintű állapottérbeli (object-level state space) – amilyen például Románia – keresőprogram egy belső (számítási) állapotának felel meg. Az A* algoritmus belső állapota például az aktuális keresési fa. A metaszintű állapottér minden cselekvése egy számítási lépés, amely a belső állapotot változtatja meg. Az A* esetén például minden számítási lépés kifejt egy levelet, és a követőit a fához adja hozzá. A 4.3. ábra, amely az egyre növekvő keresési fák sorozatát mutatja, értelmezhető lehetne úgy, hogy a metaszintű állapottérben egy utat mutat, ahol az út minden állapota egy objektumszintű keresési fa.
A 4.3. ábrán az út öt lépésből áll, Fogaras kifejtését is beleszámítva, ami nem volt valami hasznos. Nehezebb problémák esetén sok ilyen téves lépésre lehet számítani, és a metaszintű tanulási algoritmus (metalevel learning) ilyen tapasztalatokból tanulhat, hogy elkerülje a haszontalan részfák kifejtését. Az ilyen tanuláshoz alkalmas módszereket a 21. fejezetben tárgyaljuk. A tanulás célja a problémamegoldás totális költségének (total cost) a minimalizálása, kompromisszumot kötve a számítási kiadások és az útköltség között.
[33] A 4.3. feladatban azt kérjük Öntől, hogy mutassa ki, hogy ez a család néhány jól ismert nem informált keresést is tartalmaz.
[34] A h(n) heurisztikus függvény bemenete ugyan egy csomópont, a függvény értéke azonban a csomóponthoz tartozó állapottól függ.
[35] A könyv első kiadásában ennek mohó keresés (greedy search) volt a neve. Más szerzők ezt legjobbat-először keresésnek (best-first search) nevezik. A második változat általunk választott általánosabb használata Pearlt (Pearl, 1984) követi.
[36] A teljesség megkívánja, hogy a C* költségnél kisebb vagy azzal egyenlő költségű csomópontokból véges sok legyen. Ez a feltétel akkor lesz igaz, ha minden lépésköltség egy véges ε-nál nagyobb és b véges.
[37] Az algoritmus vázlatos leírása a könyv első kiadásában megtalálható.
