3.3. Megoldások keresése
Az előzőkben láttuk, hogyan kell egy problémát definiálni. A hátralévő lépés – a megoldás megkeresése – az állapottérben végrehajtott kereséssel történik. Ebben a részben olyan keresési technikákkal foglalkozunk, amelyek egy explicit keresési fát (search tree) használnak, amelyet az állapotteret együttesen definiáló kezdeti állapotból és az állapotátmenet-függvényből generálnak. Általánosságban, ha egy állapotot több úton is elérhetünk, inkább keresési gráfról, mint keresési fáról beszélünk. Ezzel az igen fontos bonyolítással később a 3.5. alfejezetben foglalkozunk.
3.6. ábra - Az Arad és Bukarest közötti útkeresési probléma részleges keresési fái. A kifejtett csomópontokat árnyékoltuk, a legenerált, de még ki nem fejtett csomópontok vastagon keretezettek, a még le nem generált csomópontokat pedig halvány szaggatott vonalak jelzik.
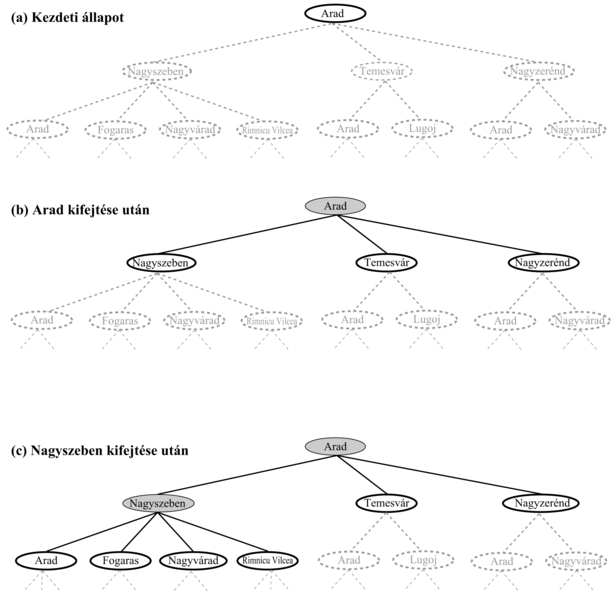
A 3.6. ábrán láthatjuk az Arad és Bukarest közötti útkereső probléma keresési fájának egy kezdeti kifejtését. A keresési fa gyökere az a keresési csomópont (search node), amely a Benn(Arad) kezdeti állapotnak felel meg. Az első lépés annak ellenőrzése, hogy vajon ez célállapot-e. Nyilvánvalóan nem az, de fontos ellenőrizni, hogy meg tudjuk oldani az olyan beugrató problémákat is, mint amilyen például az „Aradról indulva jussunk el Aradra”. Mivel ez nem célállapot, egyéb állapotokat is meg kell vizsgálnunk. Ezt az aktuális állapot kifejtésével (expanding) tesszük, azaz az állapotátmenet-függvénynek az aktuális állapotra történő alkalmazásával, amivel az állapotok egy új halmazát generáljuk (generating). Ebben az esetben három új állapotot kapunk: Benn(Nagyszeben), Benn(Temesvár) és Benn(Nagyzerénd). Most el kell döntenünk, hogy a három lehetőség közül melyik utat kövessük.
A keresés lényege a következő: egy lehetőséget kiválasztani, és a többit későbbre halasztani arra az eshetőségre, ha az első választás nem vezetne megoldásra. Tételezzük fel, hogy elsőnek Nagyszebent választjuk. Ellenőrizzük, hogy ez célállapot-e (nem az), majd kifejtjük, aminek hatására a Benn(Arad), Benn(Fogaras), Benn(Nagyvárad) és Benn(RimnicuVilcea) állapotokat kapjuk. Ezek után e négy közül bármelyiket választhatjuk, vagy akár vissza is mehetünk és választhatjuk Nagyzeréndet vagy Temesvárt. Folytatjuk a kiválasztást, a célállapot-ellenőrzést és a kifejtést, míg egy megoldást nem találunk, vagy amíg el nem fogynak a kifejtendő állapotok. A kifejtendő állapot kiválasztását a keresési stratégia (search strategy) határozza meg. Az általános fakereső algoritmus informális megfogalmazását a 3.7. ábra mutatja.

Fontos megkülönböztetni az állapotteret és a keresési fát. Az útkeresési probléma esetében az állapottér csak 20 állapotból áll, minden egyes városhoz tartozik egy állapot. Ebben az állapottérben azonban végtelen sok út vezet, így a keresési fa végtelen sok csomópontból áll. Például az Arad–Nagyszeben, Arad–Nagyszeben–Arad, Arad– Nagyszeben–Arad–Nagyszeben három út az első három a végtelen számú útszekvenciából. (Egy jó keresési algoritmus nyilvánvalóan elkerüli az ilyen utak követését. A 3.5. alfejezetben megmutatjuk hogyan.)
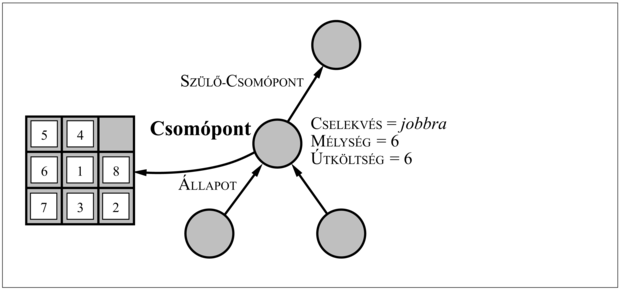
A csomópontokat sokféle módon lehet reprezentálni, de mi feltételezzük, hogy egy csomópont egy öt komponensből álló adatszerkezet:
-
ÁLLAPOT: az állapottérnek a csomóponthoz tartozó állapota; -
SZÜLŐ-CSOMÓPONT: a keresési fa azon csomópontja, amely a kérdéses csomópontot generálta; -
CSELEKVÉS: a csomópont szülő-csomópontjára alkalmazott cselekvés; -
ÚT-KÖLTSÉG: a kezdeti állapotból a kérdéses csomópontig vezető út általában g(n)-nel jelölt költsége, ahogy ezt a szülőmutatók jelzik; -
MÉLYSÉG: a kezdeti állapotból vezető út lépéseinek a száma.
Fontos visszaidéznünk a csomópontok és az állapotok közti különbséget. A csomópont egy adatnyilvántartásra használt adatszerkezet, amit egy keresési fa leírására használunk. Egy állapot a világ egy konfigurációja. Így a csomópontok a SZÜLŐ-CSOMÓPONT mutatók által definiált meghatározott úton találhatók, míg az állapotok nem. Továbbá könnyen előfordulhat, hogy két különböző csomópont egyazon állapotot tartalmaz, ha ezt az állapotot két különböző cselekvéssorozattal generálták le. A csomópont-adatstruktúrát a 3.8. ábra mutatja.
3.8. ábra - A keresési fa alapvető építő adatstruktúrái a csomópontok. Minden csomópontnak van szülője, állapota és számos adminisztráló adatmezeje. A nyilak a gyerekektől a szülőkig mutatnak.
Valahogy nyilván kell tartanunk a legenerált, kifejtésre váró csomópontokat is – ezt a gyűjteményt, listát peremnek (fringe) nevezik. A perem minden eleme egy levélcsomópont (leaf node), azaz egy olyan csomópont, amelynek a fában nincsenek követői. A 3.6. ábrán a fák pereme a vastagon bekeretezett csomópontokból áll. A perem legegyszerűbb reprezentációja egy csomóponthalmaz lenne. A keresési stratéga ekkor olyan függvény lenne, amely a következő lépésben kifejtendő csomópontot ebből a halmazból választaná ki. Bár elvi szempontból ez nyilvánvaló megoldás, számításigény szempontjából drága lenne, mert a keresési stratégia függvénynek a halmaz minden egyes elemét végig kellene néznie, hogy ki tudja választani a legjobb csomópontot. Ezért a továbbiakban feltesszük, hogy a csomópontgyűjtemény egy várakozási sorként (queue) van megvalósítva. A soron végezhető műveletek az alábbiak:
-
SORT-LÉTREHOZ(elem, …) létrehoz egy az adott elemeket tartalmazó sort. -
ÜRES?(sor) csak akkor ad vissza igaz értéket, ha a sor üres. -
ELSŐ-ELEM(sor) visszaadja a sor első elemét. -
TÁVOLÍTSD-EL-AZ-ELSŐ-ELEMET(sor) visszaadja azELSŐ-ELEM(sor)-t és ezt eltávolítja a sorból. -
BESZÚR(elem, sor) egy elemet szúr be a sorba. -
BESZÚR-MIND(elemek, sor) egy elemhalmazt beszúr a sorba.
Ezen definíciók felhasználásával az általános fakeresési algoritmus egy formálisabb definícióját adhatjuk meg. Ezt a 3.9. ábra mutatja.
3.9. ábra - Az általános fakeresési algoritmus. (Vegyük észre, hogy a perem argumentumnak egy üres sornak kell lennie, és a sor típusa befolyással lesz a keresés sorrendjére.) A
MEGOLDÁS függvény a szülőmutatók gyökérig való követésével kinyert cselekvéssorozatot adja vissza.
A problémamegoldó algoritmus kimenete vagy kudarc, vagy egy megoldás (egyes algoritmusok végtelen hurokba kerülhetnek és soha nem térnek vissza válasszal). Mi az algoritmusok hatékonyságát négyféle módon fogjuk értékelni:
-
Teljesség (completeness): az algoritmus garantáltan megtalál egy megoldást, amennyiben létezik megoldás?
-
Optimalitás (optimality): a stratégia megtalálja az optimális megoldást, ahogy azt a 3.1.1. szakasz - Jól definiált problémák és megoldások részben definiáltuk?
-
Időigény (time complexity): mennyi ideig tart egy megoldás megtalálása?
-
Tárigény (space complexity): a keresés elvégzéséhez mennyi memóriára van szükség?
Az idő- és tárigényről beszélve mindig a probléma nehézségének valamilyen mértékét tartjuk szem előtt. Az elméleti számítástudományban egy tipikus ilyen mérték az állapottér gráf nagysága, mivel a gráf a kereső program bemenetére adott explicit adatstruktúrának tekinthető (erre egy példa Románia térképe). Az MI-ben, ahol a gráfot implicit formában a kezdeti állapottal és az állapotátmenet-függvénnyel reprezentáljuk, és ahol a gráf sokszor végtelen, a komplexitást három tényezővel fejezzük ki. Ezek: b – az elágazási tényező (branching factor), vagyis a követők maximális száma minden csomópontban, d – a legsekélyebb célállapot mélysége és m – az állapottérben található utak maximális hossza.
Az időt gyakran a keresés közben generált[31] csomópontok számával, a tárat pedig a memóriában maximálisan tárolt csomópontok számával mérik.
A keresés hatékonyságának becslésénél gondolhatunk a keresési költségre (search cost), amely tipikusan az időigénytől függ, de tartalmazhat egy tárigényt jelző komponenst is; vagy használhatjuk a keresés összköltségét (total cost), amely a megoldás útköltségét és a keresési költséget kapcsolja össze. Az Aradról Bukarestbe vezető útkeresési probléma esetén a keresési költség a keresés ideje, a megoldási költség pedig a teljes út hossza km-ben. Így amikor a teljes költséget akarjuk kiszámítani, kilométert és milliszekundumot kellene összeadnunk. Ez nem mindig egyszerű, mert nem létezik semmilyen „hivatalos váltószám” a kettő között, ennél a problémánál azonban értelmesnek tűnhet a kilométereket milliszekundumokra átszámítani a gépkocsi átlagsebességét használva (mert az ágensnek az idő a fontos). Ez lehetővé teszi, hogy az ágens megtalálja azt a kompromisszumot, amikor a legrövidebb út keresését célzó minden további számítás improduktívvá válik. A különböző javak közötti kompromisszum általános problémájára a 16. fejezetben még visszatérünk.
[31] Egyes források ehelyett az időt a kifejtett csomópontok számával mérik. A két mérték legfeljebb egy b tényezőben tér el. Nekünk úgy tűnik, hogy a csomópontkifejtés végrehajtási ideje nő az adott kifejtésben generált csomópontok számával.
