22.3. Szintaktikai analízis (elemzés)
Már definiáltuk az elemzést (parsing) mint az adott bemeneti füzérhez tartozó levezetési fa megtalálásának folyamatát. Azaz a PARSE függvény meghívása, mint például a
Parse(„the wumpus is dead”, ℰ0, S)
olyan fát kell visszaadnia, amelynek gyökerében S áll, levelei a „the wumpus is dead” és belső csomópontjai az ℰ0 nyelvtan nem záró szimbólumai. A 22.1. ábrán láthattunk egy ilyen fát. Folytonos szövegként a következőképpen írhatjuk:
[S: [NP: [Article: the] [Noun: wumpus]]
[VP: [Verb: is][Adjective: dead]]]
Fontos
Az elemzés tekinthető egy levezetési fa megkeresésének folyamataként. A keresési tér meghatározásának két szélsőséges (és sok közbülső) módja van. Az egyik szerint kiindulhatunk az S szimbólumból, és kereshetünk egy olyan fát, amely leveleiben tartalmazza a szavakat. Ez az úgynevezett fentről lefelé elemzés (top-down parsing) (mivel S-et a fa tetejére helyezzük). Másrészt kiindulhatunk a szavakból, és kereshetünk egy fát, ahol S a gyökércsomópont. Ez a lentről felfelé elemzés (bottom-up parsing).[223] A fentről lefelé történő elemzés pontosan definiálható a következő keresési problémaként:
-
A kezdeti állapot (initial state) egy elemzési fa, amelynek S a gyökércsomópontja, és egy ismeretlen gyerekcsomópontja van: [S: ?]. Általánosságban a keresési térben minden állapot egy levezetési fa.
-
Az állapotátmenet-függvény (successor function) kiválasztja azt a legszélső csomópontot bal oldalon a fában, amelynek ismeretlen gyereke van. Ezek után a nyelvtanban olyan szabályokat keres, amelyek ezt a csomópontot tartalmazzák gyökérelemként. Minden ilyen szabályra generál egy következő állapotot, ahol a ? szimbólumot felcseréli a szabály jobb oldalának megfelelő listával. Például az ℰ0 nyelvtanban két szabály van S-re, így az [S: ?] fát a következő két származtatottal cseréli le:
[S: [S: ?] [Conjunction: ?] [S: ?]]
[S: [NP: ?] [VP: ?]]
A másodiknak hét származtatottja lesz, minden NP átírási szabályhoz egy.
-
A célteszt (goal test) ellenőrzi, hogy a levezetési fa levelei pontosan megfelelnek-e a bemeneti füzérnek, nincsenek-e ismeretlenek és lefedetlen bemenetek.
A fentről lefelé történő elemzés egyik nagy problémája az úgynevezett bal-rekurzív szabályok (left-recursive rules) kezelése, melyek X → X … alakúak. Mélységi kereséssel egy ilyen szabály végtelen ciklusban X-et [X: X …]-ra cserélné. Szélességi keresés esetén sikeresen megtaláljuk az érvényes mondatok elemzéseit, de érvénytelen mondatok esetében egy végtelen keresési térben ragadnánk le.
A lentről felfelé történő elemzés keresésként történő formalizálása a következő:
-
A kezdeti állapot (initial state) a bemeneti füzérben található szavak listája, mindegyiket egy olyan levezetési faként ábrázolva, melynek csak egy levele van, például: [the, wumpus, is, dead]. Általánosságban a keresés minden állapota levezetési fák egy listája.
-
Az állapotátmenet-függvény (successor function) megvizsgál minden i pozíciót a fák listájában a nyelvtan szabályainak minden lehetséges jobb oldalán. Ha a lista i pozíciójában kezdődő részsorozata illeszkedik a jobb oldalra, akkor a részsorozatot lecseréli egy új fára, amelynek kategóriája a szabály bal oldala, és amelynek gyerekei a részsorozat. „Illeszkedés” alatt azt értjük, hogy a csomópont kategóriája megegyezik a jobb oldal elemének kategóriájával. Például az Article → the szabály illeszkedik a [the, wumpus, is, dead] első csomópontjából álló részsorozatra, így a következő állapot az [[Article: the], wumpus, is, dead] lenne.
-
A célteszt (goal test) egy olyan állapotot keres, ahol egyetlen fa van, melynek gyökere az S.
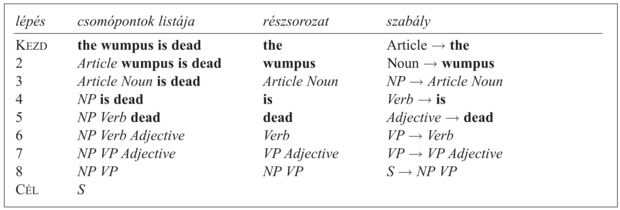
A 22.5. ábra bemutat egy példát a lentről felfelé történő elemzésre.
22.5. ábra - A „the wumpus is dead” lentről felfelé történő elemzési lépései. A szavakat tartalmazó csomópontok listájával kezdünk. Ezek után egy szabály jobb oldalára illeszkedő részsorozatokat felcserélünk egy új csomóponttal, amelynek gyökere a szabály bal oldala. Például a harmadik sorban az Article és Noun csomópontokat lecseréljük egy NP csomópontra, amelynek e két csomópont lesz a gyereke. A fentről lefelé elemzés hasonló lépéseket eredményezne, de épp a fordított irányban.
A lentről felfelé és a fentről lefelé történő elemzés is lehet kevéssé hatékony azon módok számossága miatt, ahogy különböző kifejezésekhez többféle elemzés rendelhető. Mindkettő elpazarolhatja az időt a keresési tér irreleváns részeinek vizsgálatával. A fentről lefelé keresés generálhat olyan közbülső csomópontokat, amelyek sosem zárhatók le szavakkal, és a lentről felfelé keresés generálhat olyan részleges elemzéseket a szavakhoz, amelyek nem fordulhatnak elő egy S-ben sem.
Még ha lenne is egy tökéletes heurisztikánk, amely lehetővé tenné az irreleváns kitérők nélküli keresést, ezek az algoritmusok akkor sem lennének hatékonyak, mivel bizonyos mondatoknak exponenciálisan sok levezetési fája van. A következő alfejezet megmutatja, hogy mit kezdhetünk ezzel a problémával.
Vizsgáljuk meg a következő két mondatot:
Have the students in section 2 of Computer Science 101 take the exam.
Have the students in section 2 of Computer Science 101 taken the exam?
Bár az első 10 szavuk közös, teljesen különböző levezetésük van, mivel az első egy felszólítás, a második egy kérdés. Egy balról jobbra elemző algoritmusnak tippelnie kellene, hogy az első szó egy felszólítás vagy egy kérdés része-e, és nem tudná megmondani, hogy a tipp helyes-e egészen a tizenegyedik szóig: take vagy taken. Ha az algoritmus rosszul tippelt, egészen az első szóig kellene visszalépnie. Az ilyen típusú visszalépés elkerülhetetlen, de ha azt szeretnénk, hogy az algoritmusunk hatékony legyen, akkor el kell kerülnie a „the students in section 2 of Computer Science 101” NP-ként történő újraelemzését minden alkalommal, amikor visszalép.
Fontos
Ebben a részben egy olyan algoritmust alakítunk ki, amely ezt a hatékonysági problémát kezelni tudja. Az alapötlet a dinamikus programozás (dynamic programming) egy példája: minden alkalommal, amikor egy részfüzért elemzünk, tárold az eredményt, így később majd nem kell újraelemeznünk. Például ha egyszer rájöttünk, hogy a „the students in section 2 of Computer Science 101” egy NP, ezt eltárolhatjuk egy diagramnak (chart) nevezett adatstruktúrában. Az így működő algoritmusokat diagramelemzőknek (chart parsers) nevezik. Mivel környezetfüggetlen nyelvtanokkal foglalkozunk, a keresési tér egy ágának kontextusában talált tetszőleges kifejezés éppúgy szerepelhet a keresési tér bármilyen más ágában is.
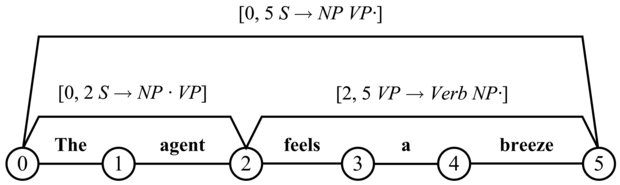
Egy n szóból álló mondat diagramja n + 1 csomópontból (vertex) és számos, ezeket összekötő élből (edges) áll. A 22.6. ábrán láthatunk egy diagramot hat csomóponttal (körök) és három éllel (vonalak). Például a
[0, 5, S → NP VP •]
címkéjű él azt jelenti, hogy egy NP-t egy VP követ, és együtt alkotnak egy S-et, mely a 0-tól 5-ig terjedő karaktersorozatot fedi le. Egy élben található • jel elválasztja a már megtaláltat a még keresettől.[224] A • jellel záródó éleket teljes éleknek (complete edges) nevezik. A
[0, 2, S → NP • VP]
él szerint egy NP lefedi a 0-tól 2-ig terjedő karaktersorozatot (az első két szó), és ha tudunk találni egy ezt követő VP-t, akkor lenne egy S-ünk. Az ilyen élek, ahol a pont a végük előtt van, úgynevezett befejezetlen (nem teljes) élek, és azt mondjuk, hogy az él egy VP-t vár.
22.6. ábra - A „The agent feels a breeze” mondat diagramjának egy részlete. Mind a hat csomópont látható, de csak három él szerepel azok közül, melyek teljes elemzést eredményeznének.
A 22.7. ábra a diagramelemző algoritmust szemlélteti. A lényege a fentről lefelé és a lentről felfelé legjobb tulajdonságainak ötvözése. A JÓSLÓ eljárás fentről lefelé működik: olyan bejegyzéseket helyez el a diagramban, amelyek megmondják, hogy milyen szimbólumok milyen helyszínen elvártak. A SZKENNER egy lentről felfelé eljárás, amely a szavakból indul ki, de egy szót csak egy meglevő diagrambejegyzés kiegészítésére használ fel. Hasonlóképpen a KITERJESZTŐ a komponenseket lentről felfelé építi, de csak egy meglevő diagrambejegyzést egészít ki.
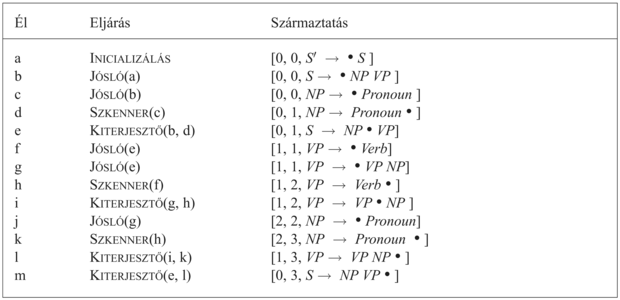
Egy trükköt alkalmaztunk a teljes algoritmus elindításához: hozzáadtunk egy [0, 0, S' → • S] élet a diagramhoz, ahol S a nyelvtan kezdeti szimbóluma, S' pedig egy általunk most kitalált új szimbólum. Az ÉL-HOZZÁAD meghívása azt eredményezi, hogy a JÓSLÓ éleket ad az olyan szabályokhoz, melyek S-t eredményezhetnek, azaz [S → NP VP]. Ezek után megvizsgáljuk ezen szabály első alkotóelemét, NP-t, és mindenféle módon olyan szabályokat adunk hozzá, melyek NP-t eredményeznek. Végső soron a JÓSLÓ fentről lefelé módon minden lehetséges élt hozzáad, ami felhasználható a végső S megalkotásában.
22.7. ábra - A diagramelemző algoritmus. S a kezdő szimbólum és S' egy új nem záró szimbólum, diagram[j] pedig azon élek listája, melyek a j csomópontban végződnek. A görög ábécé betűi nulla vagy több szimbólumból álló füzérekre illeszkednek.
![A diagramelemző algoritmus. S a kezdő szimbólum és S' egy új nem záró szimbólum, diagram[j] pedig azon élek listája, melyek a j csomópontban végződnek. A görög ábécé betűi nulla vagy több szimbólumból álló füzérekre illeszkednek.](/mi_almanach/sites/default/files/books/35/files/kepek/22-07.png)
Amikor S' jóslója készen van, belépünk egy ciklusba, amely meghívja a SZKENNER-t a mondat minden egyes szavára. Ha a j pozícióban álló szó egy B kategória tagja, amit valamelyik él keres a j pozícióban, akkor kiterjesztjük azt az élet megjelölve a szót, mint B egy példányát. Vegyük észre, hogy a SZKENNER minden egyes meghívása végződhet a JÓSLÓ és a KITERJESZTŐ rekurzív meghívásával, ily módon ötvözve a fentről lefelé és a lentről felfelé feldolgozást.
A másik lentről felfelé komponens, a KITERJESZTŐ[225] vesz egy teljes élt, amelynek bal oldalán B van, és felhasználja a diagramban levő bármely nem teljes szabály kiterjesztésére, amely ott végződik, ahol a teljes él kezdődik, ha a nem teljes szabály egy B-re vár.
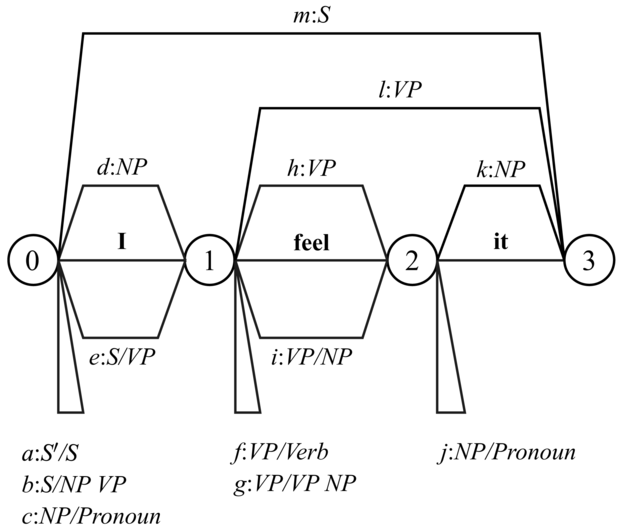
A 22.8. és 22.9. ábrák mutatják az „I feel it” mondat (amely a „Do you feel a breeze?” kérdésre adott válasz) diagramját és elemzési lépéseit. Tizenhárom él (a–m jelekkel ellátva) szerepel a diagramon, melyek közül öt teljes (a diagram verticei csomópontjai felett) és nyolc befejezetlen (alattuk). Vegyük észre a JÓSLÓ, SZKENNER és KITERJESZTŐ akciók ciklusát. Például a Jósló felhasználja azt a tényt, hogy az „a” él egy S-t vár ahhoz, hogy megelőlegezze egy NP („b” él) és egy Pronoun („c” él) jóslatát. Ezek után a SZKENNER felismeri, hogy van egy Pronoun a megfelelő helyen („d” él), és a KITERJESZTŐ kombinálja a „b” nem teljes élt a „d” teljes éllel, így előállítva egy új élt, „e”-t.
22.8. ábra - Az „0 I 1 feel 2 it 3” mondat diagramelemzése. Az m:S jelölés azt jelenti, hogy az m élnek egy S áll a jobb oldalán, míg az f:VP/Verb azt, hogy az f élnek VP van a bal oldalán, de egy Verb-et vár. Öt teljes él van a csomópontok felett, és nyolc hiányos alattuk.
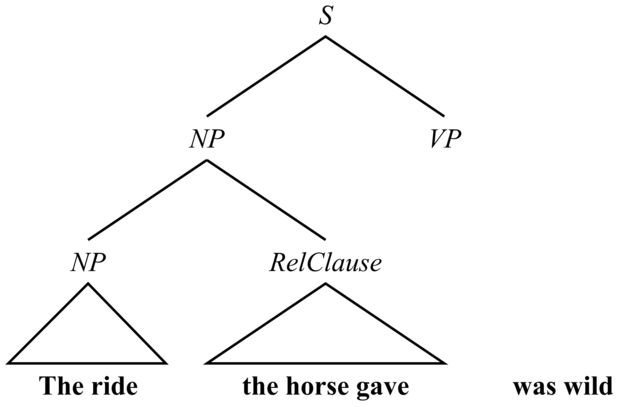
A diagramelemző algoritmus elkerüli az élek nagy halmazának építését, amit az egyszerű lentről felfelé eljárás végigvizsgált volna. Vegyük a „The ride the horse gave was wild” mondatot. Egy lentről felfelé elemzés megjelölné a „ride the horse”-t mint egy VP-t, majd elvetné az elemzési fát, amint rájönne, hogy nem illeszkedik egy nagyobb S-be. Azonban az ℰ0 nem engedi meg, hogy egy VP a „the”-t kövesse, így a diagramelemző algoritmus sosem jósol VP-t ezen a ponton, így elkerüli ott a VP szerkezet időpocsékoló építését. Azokat az algoritmusokat, melyek balról jobbra működnek, és elkerülik ezen lehetetlen szerkezetek felépítését, balsarok-elemzőknek (left-corner parsers) nevezzük, mivel egy olyan elemzési fát építenek fel, amely a nyelvtan kezdő szimbólumával indul, és a mondat legszélén balra (a bal sarokban) álló szó felé terjeszkednek. Egy élt csak akkor adnak a diagramhoz, ha ezen elemzési fa kiterjesztését szolgálhatja (példaként lásd 22.10. ábra).
22.9. ábra - Az „0 I 1 feel 2 it 3.” elemzési lépései. Az a–m élek mindegyikére megmutatjuk azt az eljárást, amit az él más, a diagramon már szereplő élekből történő származtatására használtunk. Bizonyos éleket a rövidség érdekében elhagytunk.
22.10. ábra - Egy balsarok-elemző algoritmussal elkerülhető a „ride” szóval kezdődő VP jóslása, de jósolni fog egy „was” szóval kezdődő VP-t, mivel a nyelvtan egy NP-t követő VP-t vár. A „the horse gave” feletti háromszög azt jelenti, hogy a szavaknak van egy RelCause elemzésük, amihez azonban közvetlenül további részek kapcsolódnak, amik nem láthatók.
A diagramelemző csak polinomiális idő- és tárigényű. O(kn2) helyet igényel az élek tárolására, ahol n a mondatban levő szavak száma és k egy, a nyelvtantól függő konstans. Amikor már nem tud több élt építeni, megáll, így tudjuk, hogy az algoritmus befejeződött (még akkor is, ha vannak bal-rekurzív szabályok). Valójában O(n3) időt igényel legrosszabb esetben, ami a legjobb, amit elérhetünk környezetfüggetlen nyelvtanokra. A DIAGRAMELEMZŐ szűk keresztmetszete a KITERJESZTŐ, amelynek meg kell próbálnia kiterjeszteni a j-ben végződő O(n) nem teljes él mindegyikét az ugyanott kezdődő O(n) teljes él mindegyikével, j lehetséges n + 1 különböző értékére. Ezeket összeszorozva kapjuk O(n3)-at. Ez egyfajta paradoxont ad a számunkra: hogyan tud egy O(n3) algoritmus visszaadni egy választ, amely exponenciális számosságú elemzési fát tartalmazhat? Vegyünk egy példát: a
„Fall leaves fall and spring leaves spring”
mondat többértelmű, mivel minden egyes szó (az „and” kivételével) lehet főnév és ige is, valamint a „fall” és a „spring” lehet melléknév is. Ennek a mondatnak mindösszesen négy elemzése van:[226]
[S: [S: [NP: Fall leaves] fall] and [S: [NP: spring leaves] spring]
[S: [S: [NP: Fall leaves] fall] and [S: spring [VP: leaves spring]]
[S: [S: Fall [VP: Fall leaves] fall] and [S: [NP: spring leaves] spring]
[S: [S: Fall [VP: Fall leaves] fall] and [S: spring [VP: leaves spring]]
Ha n többértelmű összekapcsolt részmondatunk lett volna, akkor 2n módon választhatnánk elemzést a részmondatokra.[227] Hogyan kerüli el a diagramelemző az exponenciális feldolgozási időt? Két választ is adhatunk a kérdésre. Először is, a DIAGRAMELEMZŐ algoritmus maga valójában egy felismerő, nem egy elemző. Ha van egy [0, n, S → α •] alakú teljes él a diagramon, akkor felismertünk egy S-t. Az elemzési fa előállítását ebből az élből nem tekintjük a DIAGRAMELEMZŐ feladatának, de elvégezhető. Vegyük észre, hogy a KIBŐVÍTŐ utolsó sorában α-t élek eB listájaként építjük fel, nemcsak kategória nevek listájaként. Így egy él elemzési fává történő átalakításához egyszerűen az összetevő éleket kell rekurzív módon végignézni, minden egyes [i, j, X → α •] élt egy [X : α] fává átalakítva. Ez egyenes/közvetlen módszer, de csak egy elemzési fát ad.
A második válasz szerint ha minden lehetséges elemzést szeretnénk, akkor mélyebbre kell ásnunk a diagramban. Miközben az [i, j, X → α •] élt egy [X : α] fává átalakítjuk, azt is megvizsgáljuk, hogy van-e másik, [i, j, X → β •] alakú él. Amennyiben van, ezek az élek további elemzési fákat generálnak. Így kapjuk azt a választási lehetőséget, hogy mit is kezdjünk velük. Felsorolhatjuk az összes lehetőséget, ami azt jelenti, hogy a paradoxont feloldanánk, és exponenciálisan sok időre lenne szükségünk az összes elemzés felsorolásához. Vagy továbbvihetjük a rejtélyt egy kicsit és az elemzéseket egy tömörített erdő (packed forest) nevű struktúrával reprezentálhatjuk, amely a következőképpen néz ki:
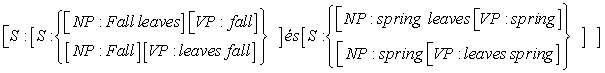
A lényeg az, hogy minden csomópont lehet egy hagyományos elemzési fa csomópont, illetve csomópontok egy halmaza is. Ez lehetővé teszi számunkra, hogy exponenciális számú elemzést reprezentáljunk polinomiális időben és tárhelyen. Természetesen n = 2 esetén nincs sok különbség 2n és 2n között, de nagy n-ekre egy ilyen reprezentáció jelentős megtakarítást eredményez. Sajnálatos módon ez az egyszerű tömörített erdő megközelítés nem kezeli az összes O(n!) lehetőséget a kapcsolódások összerendelésére. Maxwell és Kaplan (1995) megmutatja, hogy egy, az igazság-karbantartó rendszerek alapelveire épülő, összetettebb reprezentáció ezeket a fákat még jobban összetömörítheti.
[223] Észrevehető, hogy a fentről lefelé és a lentről felfelé történő elemzés hasonló az előre-, illetve hátrafelé következtetéshez, amiket a 7. fejezetben írtunk le. Hamarosan látni fogjuk, hogy ez az analógia pontos.
[224] A • miatt nevezik az éleket néha pontozott szabályoknak (dotted rules).
[225] A KITERJESZTŐ eljárásunkat tradicionálisan TELJESSÉ-TEVŐ-nek hívták. Ez a név félrevezető, mivel az eljárás nem fejez be éleket: bemenetként vesz egy teljes élt, és kiterjeszt nem teljes éleket.
[226] Az [S: Fall [VP: leaves fall]] elemzés megegyezik az „Autumn abandons autumn” mondattal.
[227] Emellett a komponensek összekapcsolódásának O(n!) számú értelmezése lenne – például (X és (Y és Z)), illetve ((X és Y) és Z). De ez már egy másik történet, amelyet Church és Patil (1982) igen jól mesél el.
