19.4. Tanulás releváns információ alapján
Úgy tűnik, hogy a Brazíliába utazónk képes a Brazíliában beszélt nyelvre vonatkozó megbízható általánosításra. A következtetésre az a háttértudása jogosítja, miszerint egy adott ország lakói (általában) ugyanazt a nyelvet beszélik. Ezt a tudást az elsőrendű logikában az alábbi módon fejezhetjük ki:[191]
Nemzetisége(x, n) ∧ Nemzetisége(y, n) ∧ Nyelve(x, l) ⇒ Nyelve(y, l) (19.6)
(szó szerint: „Ha x és y azonos n állampolgárságú, és x az l nyelvet beszéli, akkor y szintén az l nyelvet beszéli.”). Nem nehéz kimutatni, hogy a fenti kijelentésből és a
Nemzetisége(Fernando, Brazil) ∧ Nyelve(Fernando, Portugál)
megfigyelésből logikailag következik (lásd 19.1. feladat), hogy:
Nemzetisége(x, Brazil) ⇒ Nyelve(x, Portugál)
A (19.6) típusú mondatok szigorú relevanciát fejeznek ki: a nemzetiség teljesen meghatározza a nyelvet. Másképpen fogalmazva: a nyelv a nemzetiség függvénye. Az ilyen mondatokat funkcionális függőségeknek (functional dependencies) vagy meghatározásoknak (determinations) nevezzük. Bizonyosfajta alkalmazásoknál (például az adatbázisrendszer-tervek specifikálásánál) ezek annyira általánosan fordulnak elő, hogy a felírásukhoz speciális szintaxist használnak. Davies (Davies, 1985) jelölésével élve:
Nemzetisége(x, n) ≻ Nyelve(x, l)
Ez persze csak egy egyszerű szintaktikai nyalánkság, azonban világosan mutatja, hogy egy meghatározás valójában predikátumok közötti reláció: a nemzetiség meghatározza a nyelvet. Az anyag vezetőképességét és sűrűségét meghatározó releváns tulajdonságokat hasonlóképpen kifejezhetjük:
Anyaga(x, m) ∧ Hőmérséklete(x, t) ≻ Vezetőképessége(x, ρ)
Anyaga(x, m) ∧ Hőmérséklete(x, t) ≻ Sűrűsége(x, d)
A hozzá tartozó általánosítások a meghatározásokból és a megfigyelésekből származnak.
Fontos
Annak ellenére, hogy meghatározások igazolják az összes brazilra vagy az adott hőmérsékletű réz minden darabjára vonatkozó általános következtetések levonását, ahhoz természetesen nem elegendők, hogy egyetlenegy példából következtessünk ki egy általános prediktív tulajdonságú elméletet, amely az összes nemzetiségre, az összes hőmérsékletre és anyagra vonatkozik. Hatásuk úgy képzelhető el legjobban, hogy leszűkítik a tanuló ágens által figyelembe veendő hipotézisek terét. A vezetőképesség előrejelzésénél például csupán az anyagra és a hőmérsékletre kell koncentrálnunk, figyelmen kívül hagyva a tömeget, a tulajdonviszonyokat, a hét napját, a jelenlegi államelnököt stb. A hipotézisek természetesen tartalmazhatnak olyan komponenseket, mint például a molekuláris struktúra, a termikus energia, a szabad elekronok sűrűsége, amit az anyag és a hőmérséklet befolyásol. A meghatározások egy elégséges alapszótárt adnak meg ahhoz, hogy a célpredikátumra vonatkozó hipotéziseket megkonstruáljuk. Ezt a kijelentést úgy láthatjuk be, hogy megmutatjuk: egy adott meghatározás logikailag ekvivalens azzal az állítással, miszerint a célpredikátum helyes definíciója a meghatározás bal oldalán lévő predikátumok által kifejezhető definíciók egyike.
Intuitív módon érthető, hogy a hipotézistér méretének számítási redukálásának könynyebbé kell tennie a célpredikátum megtanulását. A számítási tanulás elmélet alaperedményeit (lásd 18.5. alfejezet) felhasználva, a lehetséges nyereség mennyiségileg is kifejezhető. Emlékezzünk arra, hogy egy Boole-függvény esetén log(|H|) számú példa (ahol |H| a hipotézistér mérete) szükséges ahhoz, hogy egy elfogadható hipotézishez konvergáljunk. Ha a tanuló n Boole-tulajdonsággal rendelkezik a hipotézisek megkonstruálásához, akkor egyéb korlátozások hiányában 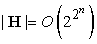 , így a példák száma O(2n). Ha a meghatározás bal oldalán d számú predikátum áll, a tanulónak O(2d) példára van szüksége, ami O(2n–d) méretű redukciót jelent. Elfogult hipotézistér, például konjuktív elfogultságok esetén, a redukció még mindig számottevő lesz, bár kevésbé lesz látványos.
, így a példák száma O(2n). Ha a meghatározás bal oldalán d számú predikátum áll, a tanulónak O(2d) példára van szüksége, ami O(2n–d) méretű redukciót jelent. Elfogult hipotézistér, például konjuktív elfogultságok esetén, a redukció még mindig számottevő lesz, bár kevésbé lesz látványos.

Ahogy ezt a fejezet bevezetőjében már megemlítettük, az előzetes tudás hasznos a tanulás szempontjából, azonban valahogy ezt is meg kell tanulni. Hogy a relevanciaalapú tanulást teljes mértékben megfogalmazhassuk a meghatározások tanulási mechanizmusát meg kell még adnunk. A most bemutatásra kerülő algoritmus alapja a megfigyelésekkel konzisztens legegyszerűbb meghatározás megtalálása. Egy P ≻ Q meghatározás azt jelenti, hogy ha egy példa illeszkedik P-re, akkor Q-ra is kell illeszkednie. Egy meghatározás konzisztens a példák egy halmazával, ha minden példapár, amely a bal oldali predikátumokon illeszkedik egymásra, a célpredikátumon is illeszkedik, magyarán, ha a besorolása azonos. Tegyük fel, hogy bizonyos anyagi mintákat megmérve a vezetőképesség alábbi méréseivel rendelkezünk:
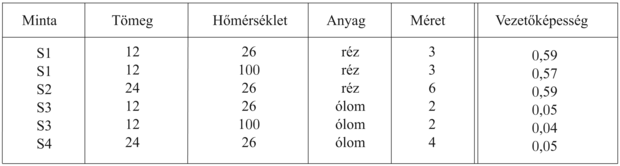
A minimális konzisztens meghatározás: Anyaga ∧ Hőmérséklete ≻ Vezetőképessége. Létezik konzisztens, de nem minimális meghatározás is: Tömege ∧ Nagysága ∧ Hőmérséklete ≻ Vezetőképessége. Ez azért konzisztens a példákkal, mert a tömeg és a méret meghatározza a sűrűséget, és az adatbázisunkban nincs két különböző anyag, amelynek sűrűsége azonos lenne. Mint mindig, most is nagyobb példahalmazra lenne szükségünk, hogy a közel helyes hipotézist kiszűrjük.
A minimális konzisztens meghatározás megkeresésének több lehetséges algoritmusa létezik. Kézenfekvő megközelítés a meghatározások terében keresni, először az egypredikátumos, a kétpredikátumos stb. meghatározásokat ellenőrizve, amíg rá nem lelünk egy konzisztens meghatározásra. Egyszerű attribútumalapú ábrázolást tételezünk fel, hasonlóan ahhoz, mint amit a döntési fák tanulásánál a 18. fejezetben használtunk. Tekintettel arra, hogy a célpredikátumot rögzítettnek vesszük, a d meghatározást a bal oldal attribútumhalmaza fogja képviselni. Az algoritmust a 19.8. ábra mutatja.
Ennek az algoritmusnak az időigénye a legkisebb konzisztens meghatározás nagyságától függ. Tegyük fel, hogy az ilyen meghatározásnak p attribútuma van a lehetséges n-ből. Az algoritmus addig nem lesz képes a meghatározást megtalálni, amíg az A-nak p nagyságú részhalmazait nem kezdi végigvizsgálni. Miután 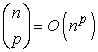 ilyen részhalmaz létezik, következésképpen az algoritmus a minimális meghatározás méretét tekintve exponenciális lesz. Az is kiderült, hogy a probléma NP-teljes, így általános esetben sem várhatunk jobbat. A legtöbb tárgytartomány azonban elegendő lokális strukturáltsággal (a lokálisan strukturált tárgytartomány definíciójára lásd 14. fejezet) rendelkezik, így p minden bizonnyal kicsi lesz.
ilyen részhalmaz létezik, következésképpen az algoritmus a minimális meghatározás méretét tekintve exponenciális lesz. Az is kiderült, hogy a probléma NP-teljes, így általános esetben sem várhatunk jobbat. A legtöbb tárgytartomány azonban elegendő lokális strukturáltsággal (a lokálisan strukturált tárgytartomány definíciójára lásd 14. fejezet) rendelkezik, így p minden bizonnyal kicsi lesz.
Ha a meghatározások tanuló algoritmusa már adott, a tanuló ágensnek módja van egy olyan minimális hipotézist megkonstruálni, amelyen belül kell a célpredikátumot megtanulnia. Összemásolhatjuk a MINIMÁLIS-KONZISZTENS-MEGH és a DÖNTÉSI-FA-TANULÁS algoritmusait, és így az RADFT-t, a relevanciaalapú döntési fa tanuló algoritmust kapjuk, amely először a releváns attribútumok minimális halmazát azonosítja, majd ezen halmazt tanulás céljából döntési fa algoritmusának adja tovább. A DÖNTÉSI-FA-TANULÁS-sal ellentétben az RADFT egyidejűleg tanulja és használja a releváns információt ahhoz, hogy a hipotézisteret minimalizálja. Elvárjuk, hogy az RADFT tanulási görbéje a DÖNTÉSI-FA-TANULÁS tanulási görbéjénél jobb legyen, és tényleg ez a helyzet. A 19.9. ábrán a két algoritmus tanulási görbéje látható, véletlen módon generált adatokon és egy olyan tanulandó függvény esetén, amely a lehetséges 16 attribútumból csupán 5-öt használ fel. Természetesen azokban az esetekben, amikor az összes attribútum releváns, az RADFT nem mutat előnyöket.
19.9. ábra - Az RADFT és a
DÖNTÉSI-FA-TANULÁS hatékonyságának összehasonlítása véletlen módon generált adatok és egy olyan célfüggvény esetén, amely a lehetséges 16 attribútumból csak 5-öt használ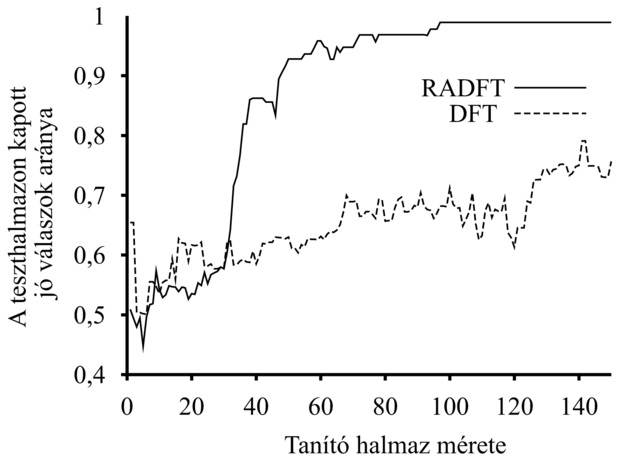
Ez a rész csak érintette a deklaratív elfogultság (declarative bias) területét, melynek az a célja, hogy megértsük, hogy az előzetes tudást hogyan kell felhasználni a megfelelő hipotézistér azonosításához, amelyben a korrekt céldefiníciót keressük. Sok kérdés megválaszolatlan maradt:
-
Hogyan kell az algoritmust kiterjeszteni a zaj kezelésére is?
-
Tudunk-e folytonos értékeket felvevő változókat kezelni?
-
Hogyan lehetne felhasználni az előzetes tudás más típusát is, a meghatározásokon kívül?
-
Hogyan lehet az algoritmusokat általánosítani, hogy egy elsőrendű elméletre, és nem csupán az attribútumalapú reprezentációra vonatkozzanak ?
Az egyes kérdésekre a következő alfejezetben keresünk választ.
[191] Az egyszerűség kedvéért feltételezzük, hogy egy személy csak egy nyelven beszél. Az olyan országok esetén, mint Svájc vagy India, a szabályt természetesen bővíteni kell.
