18.5. Miért működik a tanulás: a tanulás számítási elmélete
A legfontosabb megválaszolatlan kérdés, amelyet a 18.2. alfejezetben tettünk fel, a következő: hogyan bizonyosodhat meg valaki arról, hogy a tanulási algoritmusa által létrehozott elmélet helyesen fogja megjósolni a jövőt? Formálisan: honnan tudjuk, hogy a h hipotézis jól közelíti az f keresett függvényt, ha nem ismerjük f-et? Évszázadok óta foglalkoznak ezekkel a kérdésekkel. Amíg nem találjuk meg a válaszokat, addig a gépi tanulást – a legjobb esetben is – csak zavarba hozza saját sikere.
Fontos
Az ebben az alfejezetben tárgyalt megközelítés a tanulás számítási elméletén (computational learning theory) alapul, amely az MI, a statisztika és az elméleti számítástudomány közös határterülete. Ennek az elméletnek az alapvető elve a következő: bármely súlyosan hibás elmélet szinte bizonyosan nagy valószínűséggel felismerhető kisszámú példa vizsgálata alapján, mivel helytelen predikciót fog adni. Tehát minden hipotézis, amely egy kielégítően nagy tanító példahalmazzal konzisztens választ ad, nem valószínű, hogy súlyosan hibás lenne: azaz valószínűleg közelítőleg helyesnek (probably approximately correct) kell lennie. Minden olyan tanuló algoritmust, amely valószínűleg közelítőleg helyes hipotéziseket ad, VKH-tanuló (PAC-learning) algoritmusnak nevezünk.
Van néhány bonyolultabb rész az előbbi gondolatmenetben. A fő kérdés a tanító és a tesztpéldák viszonya: végül is mi azt szeretnénk, ha a hipotézis nem csupán a tanító halmazon lenne közelítőleg helyes, hanem elsősorban a teszthalmazon. Az alapvető feltevés az, hogy a tanító és a teszthalmazt ugyanolyan valószínűség-eloszlást használva, véletlenszerűen és függetlenül választottuk ugyanabból a példapopulációból. Ezt stacionaritási (stationarity) feltevésnek nevezzük. A stacionaritási feltevés nélkül az elmélet semmilyen, a jövőre vonatkozó igénnyel nem léphet fel, mivel nem lesz szükségszerű kapcsolat a múlt és a jövő között. A stacionaritási feltevés támasztja alá azt a gondolatot, hogy a példákat kiválasztó eljárás nem rosszindulatú. Persze ha a tanító halmaz kizárólag furcsa példákat tartalmaz – kétfejű kutyákat például –, akkor a tanuló algoritmus nyilvánvalóan nem tehet mást, mint sikertelen általánosításra jut a felől, hogy mi módon lehet a kutyákat felismerni.
Néhány definícióra szükségünk lesz ahhoz, hogy ezeket a felismeréseket a gyakorlatba át tudjuk ültetni:
-
Jelöljük X-szel az összes lehetséges példák halmazát.
-
Jelölje D azt a valószínűségi eloszlást, amely alapján a példákat választjuk.
-
Legyen H a lehetséges hipotézisek halmaza.
-
Legyen N a tanító halmaz elemeinek a száma.
Előzetesen feltesszük, hogy a keresett f függvény eleme H-nak. Most már definiálhatjuk azt a hibát (error), ami egy h hipotézisnek a keresett f függvénytől való eltérését jellemzi a mintákra vonatkozó adott eloszlás mellett, mint annak valószínűségét, hogy h az f-től eltérő választ ad egy példára:
error(h) = P(h(x) ≠ f(x)|x a D alapján választva)
Ez ugyanaz a mennyiség, mint amelyet az előzőkben bemutatott tanulási görbékkel mértünk a gyakorlatban.
18.12. ábra - A hipotézistér sematikus ábrázolása a keresett f függvény körül felvett „ ε -gömb” ábrázolásával
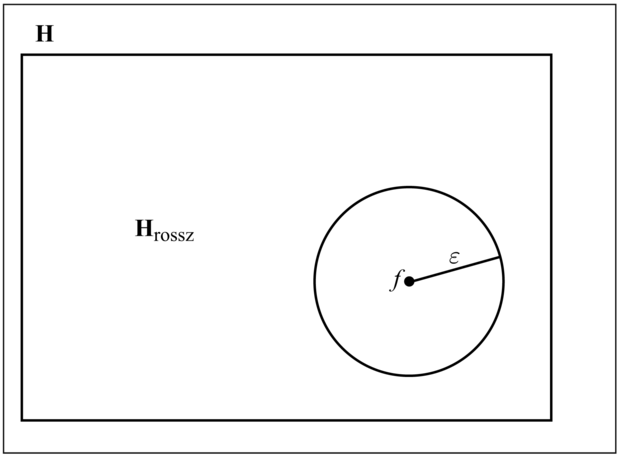
Egy h hipotézist közelítőleg helyesnek (approximately correct) nevezünk, ha error(h) ≤ ε, ahol ε egy kis konstans. A bizonyítás megközelítése az, hogy megmutatjuk: N példa vizsgálata után az összes konzisztens hipotézis nagy valószínűséggel közelítőleg helyes lesz. Úgy gondolhatunk egy közelítőleg helyes hipotézisre, mint amely közel van a keresett függvényhez a hipotézistérben: egy – a keresett f körül felvett – ε-gömbön (ε-ball) belül van. A 18.12. ábrán bemutatjuk az összes hipotézis H terét, amelyet két részre osztottunk, egyik az ε-gömb f körül, a másik a Hrossz-szal jelölt maradék.
A következők alapján kiszámíthatjuk annak valószínűségét, hogy egy „súlyosan hibás” hr ∈ Hrossz hipotézis konzisztens lesz az első N példával. Tudjuk, hogy error(hr) > ε. Tehát annak valószínűsége, hogy egy adott példára helyes választ ad, legfeljebb 1 – ε. Ezek után az N példára vonatkozó összefüggés:
P(hr konzisztens N példával) ≤ (1 – ε)N
Annak valószínűségét, hogy Hrossz legalább egy konzisztens hipotézist tartalmaz, a lehetséges egyedi hipotézisek száma határozza meg:
P(Hrossz tartalmaz egy konzisztens hipotézist) ≤ |Hrossz|(1 – ε)N ≤ |H|(1 – ε)N
Kihasználtuk, hogy |Hrossz| ≤ |H|. Ezt a valószínűséget valamely kellően kis δ érték alá akarjuk csökkenteni:
|H|(1– ε)N ≤ δ
Felhasználva, hogy (1 – ε) ≤ e–ε, a célunk elérhető, ha lehetővé tesszük, hogy az algoritmus
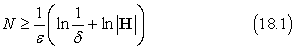
példát megvizsgálhasson. Ennek értelmében, ha egy algoritmus ilyen mennyiségű példával konzisztens hipotézist ad vissza, akkor legalább 1 – δ valószínűséggel a hibája legfeljebb ε. Más szavakkal közelítőleg helyesnek nevezzük. A szükséges példaszámot, ami ε és δ függvényeként adható meg, a hipotézistér minta komplexitásának (sample complexity) nevezzük.
Kiderült, hogy kulcskérdés a hipotézistér mérete. Mint korábban láttuk, ha H az n attribútumon felvehető Boole-függvények halmaza, akkor 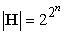 . Tehát a tér minta komplexitása 2n szerint nő. Mivel a lehetséges példák száma szintén 2n, ebből az következik, hogy a Boole-függvények terében egyetlen tanuló algoritmus sem tud jobb eredményt elérni, mint egy táblázat, ha csupán arra szorítkozik, hogy egy olyan hipotézist adjon vissza, amely az összes ismert példával konzisztens. Ennek megmutatására egy másik lehetőség az, hogy megfigyeljük: egy tetszőleges ismeretlen példára a hipotézistér ugyannyi pozitív kimenetelt jósoló konzisztens hipotézist tartalmaz, mint amennyi negatív kimenetelt jósol.
. Tehát a tér minta komplexitása 2n szerint nő. Mivel a lehetséges példák száma szintén 2n, ebből az következik, hogy a Boole-függvények terében egyetlen tanuló algoritmus sem tud jobb eredményt elérni, mint egy táblázat, ha csupán arra szorítkozik, hogy egy olyan hipotézist adjon vissza, amely az összes ismert példával konzisztens. Ennek megmutatására egy másik lehetőség az, hogy megfigyeljük: egy tetszőleges ismeretlen példára a hipotézistér ugyannyi pozitív kimenetelt jósoló konzisztens hipotézist tartalmaz, mint amennyi negatív kimenetelt jósol.
A következő dilemmával kerültünk szembe: ha nem korlátozzuk a szóba jövő függvények terét, akkor az algoritmus nem lesz képes tanulni, viszont ha korlátozzuk a függvények terét, akkor fennáll a veszély, hogy kihagyjuk a keresett függvényt. Két lehetőségünk van, hogy „kimeneküljünk” ebből a dilemmából. Az első, hogy nem csupán ahhoz ragaszkodunk, hogy az algoritmus egy tetszőleges konzisztens hipotézist adjon vissza, hanem ahhoz is, hogy részesítse előnyben az egyszerűeket (mint ahogy a döntési fa tanulásnál tettük). Ezen algoritmusok elméleti tárgyalása túlmegy ennek a könyvnek a keretein, de megemlítjük, hogy azon esetekben, amikor az egyszerű konzisztens hipotézisek keresése kezelhető probléma, a mintakomplexitás-eredmények jobbak, mint a csupán konzisztencián alapuló vizsgálatoké. A másik menekülési lehetőség, amelyet követni is fogunk, hogy a Boole-függvények teljes halmazából a megtanulható függvények részhalmazára fogunk koncentrálni. Az ötlet abban áll, hogy legtöbb esetben nincs szükségünk a Boole-függvények teljes kifejezőerejére, korlátozottabb nyelvek is kielégítők számunkra. A következőkben egy ilyen korlátozottabb nyelvet vizsgálunk meg részletesebben.
A döntési lista (decision list) egy kötött formájú logikai kifejezés. Egy tesztsorozatból áll, amely tesztek mindegyike literálisok konjunkciója. Ha egy teszt valamelyik példa leírására alkalmazva pozitív eredményt ad, akkor a döntési lista határozza meg a példára adandó választ. Ha a teszt eredménye negatív, akkor a lista következő tesztjével folytatódik a feldolgozás.[186] A döntési listák emlékeztetnek a döntési fákra, de a globális struktúrájuk egyszerűbb, ezzel szemben az egyes tesztek bonyolultabbak, mint a döntési fáknál. A 18.3. ábra egy döntési listát mutat be, amely a következő hipotézist reprezentálja:
∀x VárjunkE(x) ⇔ Vendégek(x, Néhány) ⋁ (Vendégek(x, Tele) ⋀ Péntek/Szombat(x))
Ha megengedünk tetszőleges méretű teszteket, akkor a döntési listák bármely Boole-függvény reprezentálására képesek (lásd 18.15. feladat). Másrészről, ha az egyes tesztek méretét k literálisra korlátozzuk, akkor lehetővé válik, hogy a tanuló algoritmus kisszámú példa alapján sikeresen általánosítson. Ezt k-DL nyelvnek nevezzük. Könynyen megmutatható, hogy a k-DL nyelvek részhalmazként tartalmazzák a k-DF nyelveket, amelyek a legfeljebb k mélységű döntési fák halmazát alkotják. Fontos, hogy egy adott nyelv, amelyre k-DL jelöléssel hivatkozunk, függ azoktól az attribútumoktól, amelyekkel a példákat leírjuk. A továbbiakban k-DL(n) lesz a jelölésünk azokra a k-DL nyelvekre, amelyek n logikai attribútumot használnak.

Első feladatunk annak megmutatása, hogy a k-DL nyelvek megtanulhatók, azaz bármely k-DL függvény pontosan közelíthető, ha kellő számú tanító mintán tanultunk. Ehhez ki kell számítanunk a nyelvben felvehető hipotézisek számát. Legyen a tesztek nyelve – n attribútumot használva, legfeljebb k literális konjunkciója – Conj(n, k). A döntési listákat tesztekből építjük fel, és minden teszthez egy Igen vagy Nem választ rendelhetünk, illetve harmadik lehetőségként a teszt hiányozhat a listáról, ezért legfeljebb 3|Conj(n,k)| különböző teszthalmaz létezhet. Ezek a tesztek tetszőleges sorrendben alkalmazhatók, így
|k-DL(n)| ≤ 3|Conj(n,k)||Conj(n,k)|!
Az n attribútumot használó k literális lehetséges konjunkcióinak száma:
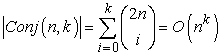
Így néhány lépés után:
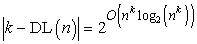
Ezt a (18.1) egyenletbe helyettesítve megmutathatjuk, hogy a k-DL függvények VKH-tanulásához szükséges minták száma polinomiálisan nő n-nel:
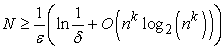
Ennek értelmében bármely algoritmus, amely konzisztens döntési listát ad vissza, kis k értékek esetén elfogadható példaszám alapján VKH-tanulással képes előállítani egy k-DL függvényt.
A következő feladatunk, hogy hatékony algoritmust találjunk, amely konzisztens döntési listát eredményez. A DÖNTÉSI-LISTA-TANULÁS nevű mohó algoritmust fogjuk használni. Ez ismételten talál egy olyan tesztet, amely pontosan a tanító halmaz valamely részhalmazának felel meg. Amikor talál egy ilyen tesztet, akkor azt hozzáadja a döntési listához, egyben eltávolítva a tesztnek megfelelő példákat a tanító halmazból. Ezek után létrehozza a döntési lista hátralevő részét pusztán a maradék példákra alapozva. Ezt addig ismétli, amíg nem marad több példa. Az algoritmust a 18.14. ábra mutatja.
Ez az algoritmus nem specifikálja, hogy milyen módszert használjunk a következő – a döntési listához adni kívánt – teszt kiválasztásához. Bár a bemutatott formálisan elért eredmények nem függnek a kiválasztás módszerétől, mégis az látszik józannak, ha előnyben részesítjük azokat az egyszerű teszteket, amelyek az osztályozott példák nagy részhalmazainak felelnek meg. Ennek eredményeként a döntési lista a lehető legtömörebb lesz. A legegyszerűbb stratégia, ha azt a legrövidebb t tesztet keressük meg, amely egy tetszőleges, egyforma osztálybasorolással rendelkező részhalmaznak megfelel, figyelmen kívül hagyva a részhalmaz méretét. Még ez a megközelítés is egész jól működik, mint az a 18.15. ábrán látható.

18.15. ábra - A
DÖNTÉSI-LISTA-TANULÁS algoritmusnak az éttermi adatokon felvett tanulási görbéje. Az összehasonlítás kedvéért feltüntettük a DÖNTÉSI-FA-TANULÁS algoritmus görbéjét is.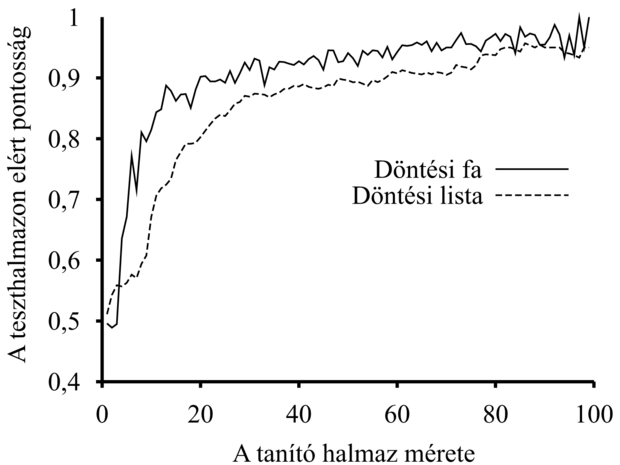
A tanulás számítási elmélete új szempontból világította meg a tanulás problémáját. Az 1960-as évek elején a tanulás elmélet az identifikáció határátmenetben (identification in the limit) problémájára koncentrált. E szerint egy identifikációs algoritmusnak mindenképpen vissza kell adnia egy olyan hipotézist, amely pontosan megegyezik a keresett függvénnyel. Erre a következőkben ismertetett eljárás ad egy lehetséges módszert. Először is rendezzük a H hipotézistér minden elemét valamilyen egyszerűség mérték szerint. Ezek után válasszuk azt a legegyszerűbb hipotézist, amely konzisztens az összes már rendelkezésre álló példával. Ahogy újabb példák érkeznek, a módszer fel fogja adni az egyszerűbb hipotézist, ha az új példák érvénytelenítették, és helyette egy bonyolultabbat választ. Amikor eléri a keresett függvényt, akkor azt már soha nem fogja feladni. Sajnálatos, hogy számos hipotézistérben óriási nagy lehet a keresett függvény eléréséhez szükséges idő, valamint a szükséges példák száma. Ezért a tanulás számítási elmélete nem ragaszkodik ahhoz, hogy a tanuló ágens megtalálja a környezetét vezérlő „egyedüli helyes törvényt”. Ehelyett inkább egy olyan hipotézist keres, amely egy bizonyos prediktív pontosságot elér. A tanulás számítási elmélete ezen felül erősen hangsúlyozza a hipotézis nyelv kifejezőképessége és a tanulás komplexitása közötti kompromisszum fontosságát. Ez az elmélet vezetett egy fontos tanuló algoritmus osztályhoz, a szupport vektorgépekhez.
Az általunk bemutatott, VKH-tanulásra vonatkozó eredmények a legrosszabb esetre érvényesek, nem feltétlenül mutatva azt az átlagos esetre vonatkozó mintakomplexitást, amelyeket viszont a bemutatott tanulási görbék tükröznek. Egy, az átlagos esetre vonatkozó analízisnek további feltételezésekkel kell élnie a minták eloszlásáról, valamint a keresett függvények eloszlásáról. Miközben ezeket a kérdéseket egyre jobban megértjük, a tanulás számítási elmélete folyamatosan a gépi tanulással foglalkozó kutatók hasznos útmutatójának bizonyul. Ezek a kutatók algoritmusaik módosításában vagy algoritmusaik tanulási képességének meghatározásában érdekeltek. A döntési listák mellett a Boole-függvények szinte minden ismert alosztályára, a neurális hálókra (lásd 20. fejezet), valamint az elsőrendű logikai állítások halmazaira (lásd 19. fejezet) születtek eredmények. Az elért eredmények azt mutatják, hogy a tisztán indukciós tanulás rendkívül nehéz. Tisztán indukciós tanuláson azt a helyzetet értjük, amelyben az ágens nem rendelkezik semmilyen, a keresett függvényre vonatkozó, előzetes ismerettel. Mint a 19. fejezetben megmutatjuk, az előzetes tudásnak az induktív tanulás vezérlésére való felhasználása lehetővé teszi, hogy meglehetősen nagy állításhalmazokat elfogadható mintaszám alapján megtanuljunk, még egy olyan nyelven is, amelynek kifejezőereje megegyezik az elsőrendű logikáéval.
