17.4. Részlegesen megfigyelhető Markov döntési folyamatok
A Markov döntési folyamatok leírása a 17.1. alfejezetben feltételezte, hogy a környezet teljesen megfigyelhető (fully observable). E mellett a feltételezés mellett az ágens mindig tudja, hogy melyik állapotban van. Ez együttesen az állapotátmenet-modell Markov-tulajdonságának a feltevésével azt eredményezi, hogy az optimális eljárásmód csak az aktuális állapottól függ. Amikor a környezet csak részlegesen megfigyelhető (partially observable), a helyzet nem ennyire átlátható. Az ágens nem tudja feltétlenül, hogy melyik állapotban is van, így nem hajthatja végre az adott állapothoz javasolt π(s) cselekvést. Továbbá, egy s állapot hasznossága és az s-beli optimális cselekvés nemcsak s-től függ, hanem attól is, hogy az ágens mennyit tud, amikor s-ben van. Ebből kifolyólag a részlegesen megfigyelhető MDF-eket (RMMDF) (partially observable MDPs, POMDPs) általában sokkal nehezebb dolgoknak tartják, mint a hagyományos MDF-eket. Az RMMDF-ek azonban nem megkerülhetők, mivel a valódi világ is egy RMMDF.
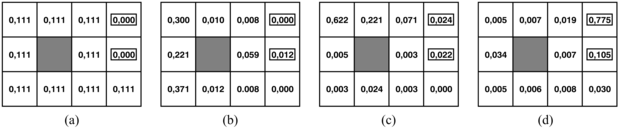
Példaként gondoljuk át újra a 17.1. ábra 4 × 3-as világát, de most tegyük fel, hogy az ágensnek egyáltalán nincsenek érzékelői, és elképzelése sincs arról, hogy hol lehet. Pontosabban, tegyük fel, hogy az ágens kezdeti állapota egyenlő valószínűséggel valamelyike a kilenc nem végállapotnak (17.8. (a) ábra). Világos, hogz ha az ágens tudná, hogy (3, 3)-ban van, akkor Jobbra mozgást hajtana végre; ha tudná, hogy (1, 1)-ben van, akkor Fel mozogna; de mivel bárhol lehet, mit is kellene tennie? Egy lehetséges válasz, hogy az ágensnek először olyan cselekvéseket kell végrehajtani, amelyek csökkentik a bizonytalanságát, és csak ezután kell megpróbálni a +1 kijárat felé tartani. Például ha az ágens öt alkalommal Balra mozgást hajt végre, akkor igen valószínű, hogy a bal oldali falnál van (17.8. (b) ábra). Ezután öt alkalommal Fel mozgást hajt végre, akkor igen valószínű, hogy a felső falnál van, valószínűleg a bal felső sarokban (17.8. (c) ábra). Végül öt Jobbra mozgást hajt végre, ekkor jó eséllyel – körülbelül 77,5%-kal – eléri a +1 kijáratot (17.8. (d) ábra). A Jobbra mozgás ezt követő folytatása az esélyét 81,8%-ra növeli. Ez az eljárásmód így meglepően biztonságos, de ebben az esetben az ágens igen lassan éri el a kijáratot, és a várható hasznossága csupán 0,08 körül van. Az optimális eljárásmód, amit hamarosan leírunk, sokkal jobban teljesít.
17.8. ábra - (a) Az ágens elhelyezkedésének kezdeti valószínűségi eloszlása. (b) Ötszöri Balra mozgás után. (c) Ötszöri Fel mozgás után. (d) Ötszöri Jobbra mozgás után.
Az RMMDF-ek kezeléséhez először is megfelelően kell őket definiálni. Egy RMMDF-nek az elemei ugyanazok, mint egy MDF-nek – egy T(s, a, s′) állapotátmenet-modell és egy R(s) jutalomfüggvény –, de van egy O(s, o) megfigyelési modellje (observational model) is, ami az s állapotban az o megfigyelés érzékelésének a valószínűségét adja meg.[173] Például az érzékelő nélküli ágensünknek csak egyetlen megfigyelése van (az üres megfigyelés), ami minden állapotban 1 valószínűséggel bekövetkezik.
A 3. és 12. fejezetben nemdeterminisztikus és részlegesen megfigyelhető tervkészítési problémákat tanulmányoztunk, és megállapítottuk, hogy a hiedelmi állapot (belief state) – az aktuális állapotok halmaza, amelyekben az ágens lehet – kulcsfogalom a megoldások leírására és kiszámítására.
Az RMMDF-ekben a fogalmat kissé finomítjuk. Egy b hiedelmi állapot most egy valószínűség-eloszlás lesz az összes lehetséges állapot felett. Például a 17.8. (a) ábra kezdeti hiedelmi állapota úgy írható, hogy 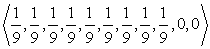 . A b hiedelmi állapot által az aktuális i állapothoz rendelt valószínűséget b(s)-sel jelöljük. Az ágens úgy számíthatja ki a jelenlegi hiedelmi állapotát, mint egy feltételes eloszlást az aktuális állapotok felett, az eddigi megfigyelések és cselekvések sorozatának ismeretében. Ez lényegében a szűrési (filtering) feladat (lásd 15. fejezet). A rekurzív szűrési alapegyenlet (lásd (15.3) egyenlet a 15.2.1. szakasz - Szűrés és előrejelzés részben) megmutatja, hogy hogyan számolhatjuk ki az új hiedelmi állapotot az előző hiedelmi állapotból és az új megfigyelésből. Az RMMDF-eknél a jelölés eltérő, és meg kell gondolni még a cselekvést is, de az eredmény lényegében ugyanaz. Ha b(s) volt az előző hiedelmi állapot, és az ágens az a cselekvést hajtja végre és az o megfigyelést érzékeli, akkor az új hiedelmi állapot a következő:
. A b hiedelmi állapot által az aktuális i állapothoz rendelt valószínűséget b(s)-sel jelöljük. Az ágens úgy számíthatja ki a jelenlegi hiedelmi állapotát, mint egy feltételes eloszlást az aktuális állapotok felett, az eddigi megfigyelések és cselekvések sorozatának ismeretében. Ez lényegében a szűrési (filtering) feladat (lásd 15. fejezet). A rekurzív szűrési alapegyenlet (lásd (15.3) egyenlet a 15.2.1. szakasz - Szűrés és előrejelzés részben) megmutatja, hogy hogyan számolhatjuk ki az új hiedelmi állapotot az előző hiedelmi állapotból és az új megfigyelésből. Az RMMDF-eknél a jelölés eltérő, és meg kell gondolni még a cselekvést is, de az eredmény lényegében ugyanaz. Ha b(s) volt az előző hiedelmi állapot, és az ágens az a cselekvést hajtja végre és az o megfigyelést érzékeli, akkor az új hiedelmi állapot a következő:
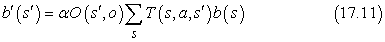
ahol a egy normalizációs konstans, ami a hiedelmi állapot 1-re összegzését biztosítja. Ezt az egyenletet úgy rövidíthetjük, hogy b′ = ELŐRE(b, a, o).
Fontos
A RMMDF-ek megértéséhez szükséges lényegi meglátás pedig ez: az optimális cselekvés csak az ágens aktuális hiedelmi állapotától függ. Így az optimális eljárásmód leírható a hiedelmi állapotok cselekvésekre történő π*(b) leképzésével. Ez nem függ az ágens aktuális állapotától, amiben tartózkodik. Ez hasznos tulajdonság, mivel az ágens nem ismeri az aktuális állapotát; csupán a hiedelmi állapotát. Ekkor egy RMMDF ágens döntési ciklusa a következő:
-
Adott jelenlegi b hiedelmi állapot esetén hajtsuk végre az a = π* (b) cselekvést.
-
Fogadjuk az o megfigyelést.
-
Állítsuk a jelenlegi állapothiedelmet
ELŐRE(b, a, o)-ra, és ismételjük meg a ciklust.
Most úgy gondolhatunk az RMMDF-ekre, mint amelyek keresést igényelnek a hiedelmi állapotok terében, pontosan úgy, ahogy az érzékelő nélküli és az eshetőségi problémákra vonatkozó módszerek a 3. fejezetben. A fő különbség az, hogy az RMMDF hiedelmi állapot tere folytonos, mivel egy RMMDF hiedelmi állapot egy valószínűségi eloszlás. Például a hiedelmi állapot a 4 × 3-as világ esetében egy pont a 11 dimenziós folytonos térben. Egy cselekvés megváltoztatja a hiedelmi állapotot is, nemcsak a fizikai állapotot, így kiértékelése aszerint az információ szerint történik, amit a cselekvés eredményeként az ágens megszerez. Az RMMDF-ekbe ezért beletartozik az információ értéke is (16.6. alfejezet) mint a döntési probléma egy komponense.
Nézzük meg tüzetesebben a cselekvések kimenetelét. Nevezetesen, számítsuk ki annak valószínűségét, hogy az ágens a b hiedelmi állapotból a b′ hiedelmi állapotba jut az a cselekvés végrehajtása után. Ekkor, ha ismernénk a cselekvést és a bekövetkező megfigyelést, akkor a (17.11) egyenlet a hiedelmi állapot egy determinisztikus frissítését adná: b′ = ELŐRE(b, a, o). Természetesen a bekövetkező megfigyelés még nem ismert, így az ágens a számos lehetséges hiedelmi állapot egyikébe, b′-be kerülhet az előforduló megfigyelés függvényében. Az o érzékelésének valószínűsége, feltéve hogy a b′ hiedelmi állapotban az a cselekvés került végrehajtásra, az összes olyan s′ aktuális állapot feletti összegzéssel adódik, amelyeket az ágens elérhet:
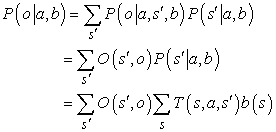
Jelölje τ(b, a, b′) annak a valószínűségét, hogy b-ből b′-be jutunk egy a cselekvéssel. Ennek felhasználásával ekkor
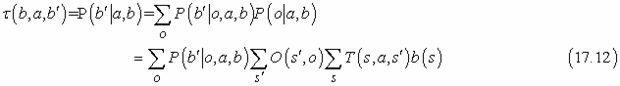
ahol P(b′|o, a, b) 1, ha b′ = ELŐRE(b, a, o), egyébként pedig 0.
Fontos
A (17.2.) egyenletet felfoghatjuk egy állapotátmenet-modellnek a hiedelmi állapot térben. Definiálhatunk egy jutalomfüggvényt is a hiedelmi állapotokra (azaz azon aktuális állapotok várható jutalmát, amelyekben az ágens lehet):
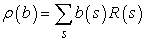
Így láthatóan τ(b, a, b′) és ρ(b) együtt egy megfigyelhető MDF-et definiál a hiedelmi állapotok terén. Továbbá megmutatható, hogy egy π*(b) optimális eljárásmód erre az MDF-re, szintén optimális eljárásmód az eredeti RMMDF-re. Máshogy fogalmazva, egy RMMDF megoldása a fizikai állapottérben redukálható egy MDF megoldására a hozzá tartozó hiedelmi állapot térben. Ez a tény talán kevésbé meglepő, arra gondolva, hogy a hiedelmi állapot definíció szerint az ágens számára mindig megfigyelhető.
Vegyük észre, hogy bár az RMMDF-eket sikeresen redukáltuk az MDF-ekre, a kapott MDF-eknek folytonos (és általában sokdimenziós) állapotterük van. A 17.2. és 17.3. alfejezetekben leírt algoritmusok egyike sem alkalmazható közvetlenül ilyen MDF-ekre. Kiderült, hogy az érték- és eljárásmód-iterációnak kifejleszthetők olyan változatai, amelyek folytonos állapotú MDF-ekre is alkalmazhatók. Az alapötlet az, hogy egy π(b) eljárásmód reprezentálható a hiedelmi állapot tér olyan részeinek egy halmazaként, amelyek mindegyikéhez egy adott optimális cselekvés tartozik.[174] Az értékfüggvény b különböző lineáris függvényét rendeli az egyes térrészekhez. Minden érték- és eljárásmód-iterációs lépés finomít a térrészek határain, és új térrészeket vezethet be.
Az algoritmus részletei meghaladják a könyv kereteit, de megadjuk a megoldást az érzékelőmentes 4 × 3-as világra. Az optimális eljárásmód a következő:
[Balra, Fel, Fel, Jobbra, Fel, Fel, Jobbra, Fel, Fel, Jobbra, Fel, Jobbra, Fel, …]
Az eljárásmód egy sorozat, mivel ez a probléma determinisztikus a hiedelmi állapotok terében – nincsenek megfigyelések. Azt a „trükköt” alkalmaztuk, hogy az ágens egyetlen Balra mozgással biztosítja, hogy nincs (4, 1)-ben, azért, hogy aztán meglehetős biztonsággal mozoghasson Fel és Jobbra a +1 kijárat eléréséhez. Az ágens a +1 kijáratot 86,6% gyakorisággal éri el, és sokkal gyorsabban, mint az alfejezet elején megadott eljárásmód esetén, így a várható hasznossága 0,38, szemben az előző 0,08-as értékével.
Bonyolultabb RMMDF-eknél, amikor megfigyelések is vannak, nagyon nehéz (valójában PSPACE-beli – azaz valóban nagyon nehéz) közelítőleg optimális eljárásmódokat találni. A problémák néhány tucat változóval gyakran kivitelezhetetlenek. A következő alfejezet egy eltérő közelítő módszert ír le RMMDF-ek megoldására, ami az előrenéző keresésen alapul.
[173] A megfigyelési modell alapvetően azonos az időbeli folyamatok érzékelő modelljével (sensor model) a 15. fejezetből. Ahogyan az MDF-ek jutalomfüggvényénél, a megfigyelési modell szintén függhet a cselekvéstől és a kimeneteli állapottól, de ez most sem egy alapvető változás.
[174] Bizonyos RMMDF-ekre az optimális eljárásmódhoz végtelen számú térrész tartozik, így az egyszerű térrészek listája megközelítés nem működik, és ötletesebb módszerek szükségesek még egy közelítés megtalálásához is.
