9.5. Rezolúció
A logikai rendszerek általunk bemutatandó három családjának az utolsó tagja a rezolúción (resolution) alapul. Láttuk a 7. fejezetben, hogy a propozíciós rezolúció egy cáfolásteljes következtetési folyamat az ítéletlogikában. Ebben az alfejezetben meg fogjuk vizsgálni, hogyan lehet kiterjeszteni a rezolúciót az elsőrendű logikára.
A teljes bizonyítási eljárás létezésének kérdése a matematikusokat érdekli közvetlenül. Ha egy teljes bizonyítási eljárás megtalálható matematikai állításokra, ebből két dolog következik. Először is, az összes tétel előfeltételeit mechanikusan elő tudjuk állítani; másodszor, a teljes matematika felépíthető alapaxiómák halmazának logikai következményeként. A teljesség kérdésének vizsgálata így a 20. századi matematika néhány legfontosabb eredményényének a megszületéséhez vezetett. 1930-ban Kurt Gödel német matematikus bebizonyította az első teljességi tételt (completeness theorem) az elsőrendű logikára, megmutatva, hogy minden kikövetkeztetett mondatnak létezik véges bizonyítása. (Gyakorlatban is felhasználható bizonyítási módszert viszont nem találtak egészen addig, amíg J. A. Robinson nem publikálta a rezolúciós algoritmust 1965-ben.) 1931-ben Gödel bebizonyította a még híresebb nemteljességi tételt (incompleteness theorem). A tétel kimondja, hogy egy logikai rendszer, amely tartalmazza az indukció elvét – amely nélkül a diszkrét matematika igen kis része építhető fel – szükségszerűen nem teljes. Ebből az következik, hogy léteznek olyan kikövetkeztetett mondatok, amelyeknek a rendszeren belül nincs véges bizonyítása. Lehet, hogy a tű ott van a metaforikus szénakazalban, de nincs olyan eljárás, amely garantálná, hogy megtaláljuk.
Gödel tétele ellenére, a rezolúcióalapú tételbizonyításokat széles körben alkalmazták matematikai tételek levezetésére, beleértve néhány olyan tételt is, amelyre előzőleg nem volt ismert bizonyítás. A tételbizonyításokat – más alkalmazások mellett – használták például hardvertervezés verifikálására vagy logikailag helyes programok generálására.
Mint az ítélatlogika esetében, az elsőrendű rezolúció is megköveteli, hogy a mondatok konjunktív normál formában (conjunctive normal form) (CNF) legyenek, tehát minden mondat klózok konjunkciója, ahol minden egyes klózt literálok diszjunkciója alkot.[92] A literálok tartalmazhatnak változókat, amelyeket univerzális kvantorral ellátottnak feltételezünk. Például a
∀x Amerikai(x) ∧ Fegyver(y) ∧ Elad(x, y, z) ∧ Ellenséges(z) ⇒ Bűnöző(x)
mondat CNF-formára átalakítva ilyen lesz:
¬Amerikai(x) ∨ ¬Fegyver(y) ∨ ¬Elad(x, y, z) ∨ ¬Ellenséges(z) ∨ Bűnöző(x)
Fontos
Minden elsőrendű logikai mondat átalakítható a következtetés szempontjából egyenértékű CNF-mondattá. Ami azt jelenti, hogy egy CNF-mondat akkor kielégíthetetlen, ha az eredeti mondat is kielégíthetetlen, ezáltal a CNF-mondatok között ellentmondásokat keresve létre tudunk hozni bizonyításokat.
A CNF-mondatok átalakításának eljárása nagyon hasonló az ítéletlogikai eljáráshoz, amelyet a „Konjunktív normál forma”részben láthatunk. A legfontosabb különbség abból fakad, hogy ki kell vonnunk a mondatokból az egzisztenciális kvantorokat. Ezt az eljárást a következő mondat lefordításával illusztráljuk: „Mindenkit, aki az összes állatot szereti, valaki szeret”, vagyis:
∀x [∀y Állat(y) ⇒ Szereti(x, y)] ⇒ [∃y Szereti(y, x)]
A lépések a következők:
-
Az implikációk eliminálása.
∀x [¬∀y ¬Állat(y) ∨ Szereti(x, y)] ∨ [∃y Szereti(y, x)]
-
A ¬befelé mozgatása. A negált összekötőjelekre vonatkozó már ismert szabályok mellett szükségünk van a negált kvantorokra vonatkozó szabályokra is. Így ezt kapjuk:
¬∀x p-ből lesz ∃x ¬p
¬∃x p-ből lesz ∀x ¬p
A mondatunk a következő átalakításokon megy keresztül:
∀x [∃y ¬(¬Állat(y) ∨ Szereti(x, y))] ∨ [∃y Szereti(y, x)]
∀x [∃y ¬ ¬Állat(y) ∧ ¬Szereti(x, y)] ∨ [∃y Szereti(y, x)]
∀x [∃y Állat(y) ∧ ¬Szereti(x, y)] ∨ [∃y Szereti(y, x)]
Figyeljük meg, hogyan alakítottuk át az univerzális kvantort (∀y) az implikáció premisszájában egzisztenciális kvantorrá. A mondatot most így lehet kiolvasni „Vagy van olyan állat, amelyet x nem szeret, vagy (ha ez nem áll fenn) valaki szereti x-et.” Világos, hogy az eredeti mondat jelentését megőriztük.
-
A változók átnevezése. Az olyan mondatokban, mint a (∀x P(x)) ∨ (∃x Q(x)), amelyek ugyanazt a változó nevet kétszer is használják, változtassuk meg az egyik változó nevét. Ezzel elkerüljük, hogy később keveredés lehessen, amikor elhagyjuk a kvantorokat. Így ezt kapjuk:
∀x [∃y Állat(y) ∧ ¬Szereti(x, y)] ∨ [∃z Szereti(z, x)]
-
Skolemizáció. A skolemizáció (skolemization) az az eljárás, amelynek során eliminációval eltávolítjuk az egzisztenciális kvantorokat. Egyszerű esetben ez megegyezik a 9.1. alfejezetben található egzisztenciális példányosítási szabállyal: fordítsuk le a ∃x P(x)-et P(A)-ra, ahol az A egy új konstans. Ha ezt a szabályt alkalmazzuk a mintamondatunkra, akkor azonban ezt kapjuk:
∀x [Állat(A) ∧ ¬Szereti(x, A)] ∨ Szereti(B, x)
amelynek teljesen téves a jelentése: azt mondja ki, hogy mindenki vagy nem tud szeretni egy bizonyos A állatot, vagy egy bizonyos B entitás szereti őt. Valójában, az eredeti mondatunk lehetővé teszi minden egyes személy számára, hogy ne szeressen egy másik állatot, vagy egy másik személy szeresse őt. Így tehát, azt szeretnénk, hogy a Skolem entitások az x-től függjenek:
∀x [Állat(F(x)) ∧ ¬Szereti(x, F(x))] ∨ Szereti(G(x), x)
Itt az F és a G Skolem-függvények. Az általános szabály az, hogy a Skolem-függvények argumentumai mind univerzális kvantorral ellátott változók, amelyeknek a hatókörében az egzisztenciális kvantor értelmezett. Hasonlóan az Egzisztenciális Példányosításhoz, a skolemizált mondat is pontosan akkor kielégíthető, ha az eredeti mondat is kielégíthető.
-
Az univerzális kvantorok elhagyása. Ezen a ponton minden megmaradt változó univerzális kvantorral van ellátva. Mi több, a mondat egyenértékű azzal a mondattal, amelyben az összes univerzális kvantort balra rendezték. Így tehát most már elhagyhatjuk az univerzális kvantorokat:
[Állat(F(x)) ∧ ¬Szereti(x, F(x))] ∨ Szereti(G(x), x)
-
Az ∧ elosztása a ∨ felett.
[Állat(F(x)) ∨ Szereti(G(x), x)] ∧ [ ¬Szereti(x, F(x)) ∨ Szereti(G(x), x)]
Ennek a lépésnek az elvégzéséhez szükség lehet az egymásba ágyazott konjunkciók és diszjunkciók kibontására is.
A mondat most CNF formájú, és két klózból áll. Eléggé olvashatatlan lett. (Némiképpen segíthet, ha megmagyarázzuk, hogy az F(x) függvény egy, az x személy által potenciálisan nem szeretett állatra vonatkozik, míg a G(x) olyan valakire utal, aki szeretheti x-et.) Szerencsére, nekünk ritkán kell CNF-mondatokat vizsgálnunk – a fordítási folyamat könnyen automatizálható.
Az elsőrendű klózokra vonatkozó következtetési szabály egyszerűen a 7.5.1. szakasz - Rezolúció részben megadott propozíciós rezolúciós szabály kiterjesztett változata. Két klóz, amelyek standardizálva vannak, tehát nem tartalmaznak azonos változókat, akkor rezolválható, ha tartalmaznak komplememens literálokat. Az ítéletlogikai literálok akkor komplemensek, ha az egyik a negációja a másiknak; míg az elsőrendű literálok akkor komplemensek, ha az egyik egyesül a másik negációjával. Így ezt kapjuk:
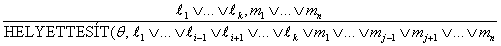
ahol az EGYESÍT (li, ¬mj) = θ. Például rezolválhatjuk ezt a két klózt:
[Állat(F(x)) ∨ Szereti(G(x), (x)] és [¬Szereti(u, v) ∨ ¬Megöli(u, v)]
a θ = {u/G(x), v/x} egyesítő felhasználásával a komplemens literálokat, a Szereti(G(x), x)-t és a ¬Szereti(u, v)-t eliminálva kapjuk meg a rezolvens (resolvent) klózt:
[Állat(F(x)) ∨ ¬Megöli(G(x), x)]
A bemutatott szabály neve bináris rezolúciós (binary resolution) szabály, mert pontosan két literált old fel. A bináris rezolúciós szabály önmagában nem eredményez egy teljes következtetési folyamatot. A teljes rezolúciós szabály literálok részhalmazait rezolválja minden egyes egyesíthető klózban. Egy alternatív megközelítés a faktorálásnak (factoring), a felesleges literálok eltávolításának a kiterjesztése az elsőrendű logikára. A propozíciós faktorálás két literált eggyé redukál, ha azok azonosak. Az elsőrendű faktorálás két literált eggyé redukál, ha azok egyesíthetők. Az egyesítőt a teljes klózra kell alkalmazni. A bináris rezolúció és a faktorálás kombinációja már teljes eljárást eredményez.
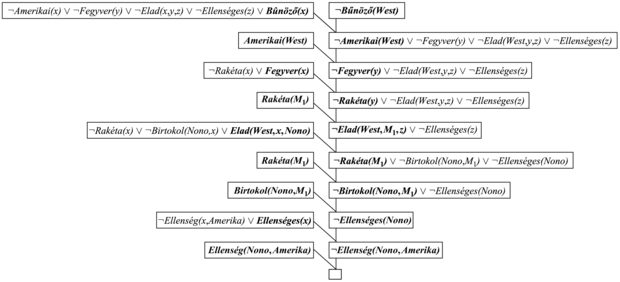
A rezolúció a TB ⊨ α állítást úgy igazolja, hogy bebizonyítja, hogy a TB ∧ ¬α nem kielégíthető, vagyis a bizonyítás az üres klóz származtatásával történik. Az algoritmikus megközelítés megegyezik az ítéletlogikában lévővel, amelyet a 7.12. ábrán már bemutattunk, így ezt itt most nem ismételjük meg. Ehelyett inkább két példabizonyítást adunk meg. Az első a bűntény példa a 9.3. alfejezetből. A mondatok CNF-ben a következők:
¬Amerikai(x) ∨ ¬Fegyver(y) ∨ ¬Elad(x, z, y) ∨ ¬Ellenséges(z) ∨ Bűnöző(x)
¬Rakéta(x) ∨ ¬Birtokol(Nono, x) ∨ Elad(West, x, Nono)
¬Ellenség(x, Amerika) ∨ Ellenséges(x)
¬Rakéta(x) ∨ Fegyver(x)
Birtokol(Nono, M1) Rakéta(M1)
Amerikai(West) Ellenség(Nono, Amerika)
Hozzáadjuk a mondatok halmazához a negált célt is ¬Bűnöző(West). A rezolúciós bizonyítást a 9.11. ábra mutatja be. Figyeljük meg a szerkezetét: a bizonyításnak egy egyszerű „gerince” van, amely a célklózzal kezdődik, és folyamatosan rezolvál a tudásbázisból származó klózokkal, mindaddig, amíg az üres klózt nem generálja. Ez jellemző a Horn-klózokat tartalmazó tudásbázisokon végzett rezolúcióra. Valójában a fő gerinc mentén található klózok pontosan megfelelnek a 9.6. ábrán látható hátrafelé láncolási algoritmusban a célváltozók egymást követő értékeinek. Ez azért van így, mert mindig azt a klózt választjuk ki rezolválásra, amelynek a pozitív literálja egyesíthető a gerincen lévő „aktuális” klóz bal szélen elhelyezkedő literáljával, és pontosan ez történik a hátrafelé láncolásban is. Így tehát a hátrafelé láncolás valójában a rezolúció egy speciális esete, egy különleges vezérlési stratégiával, amely meghatározza, hogy melyik rezolúciót hajtsuk végre legközelebb.
A második példánk kihasználja a skolemizációt, és nem határozott klózokat is tartalmaz. Ez valamivel bonyolultabb bizonyítási struktúrát eredményez. Természetes nyelven megfogalmazva a probléma a következő:
Mindenkit, aki az összes állatot szereti, szeret valaki.
Bárkit, aki megöl egy állatot, senki sem szeret.
Jankó szereti az összes állatot.
Vagy Jankó, vagy a Kíváncsiság ölte meg a macskát, akinek a neve Tuna.
A Kíváncsiság ölte meg a macskát?
Először is leírjuk az eredeti mondatokat, némi háttértudást, és a G negált célt az elsőrendű logikában:
A. ∀x [∀y Állat(y) ⇒ Szereti(x, y)] ⇒ [∃y Szereti(y, x)]
B. ∀x [∃y Állat(y) ∧ Megöli(x, y)] ⇒ [∀z ¬Szereti(z, x)]
C. ∀x Állat(x) ⇒ Szereti(Jankó, x)
D. Megöli(Jankó, Tuna) ∨ Megöli(Kíváncsiság, Tuna)
E. Macska(Tuna)
F. ∀x Macska(x) ⇒ Állat(x)
G. ¬Megöli(Kíváncsiság, Tuna)
Most pedig alkalmazzuk az átalakítási procedúrát, hogy minden egyes mondatot CNF-be konvertáljunk:
A1. Állat(F(x)) ∨ Szereti(G(x), x)
A2. ¬Szereti(x, F(x)) ∨ Szereti(G(x), x)
B. ¬Állat(y) ∨ ¬Megöli(x, y) ∨ ¬Szereti(z, x)
C. ¬Állat(x) ∨ Szereti(Jankó, x)
D. Megöli(Jankó, Tuna) ∨ Megöli(Kíváncsiság, Tuna)
E. Macska(Tuna)
F. ¬Macska(x) ∨ Állat(x)
¬G. ¬Megöli(Kíváncsiság, Tuna)
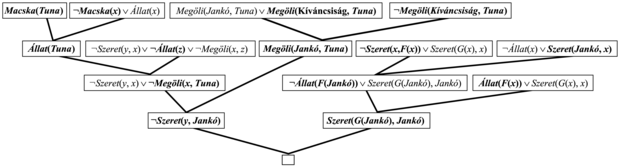
A 9.12. ábrán látható a rezolúciós bizonyítása annak, hogy a Kíváncsiság ölte meg a macskát. Magyarul a bizonyítást így írhatjuk át:
Tegyük fel, hogy a Kíváncsiság nem ölte meg Tunát. Tudjuk, hogy vagy Jankó, vagy a Kíváncsiság tette; tehát biztosan Jankó tehette. Mármost, Tuna egy macska, és a macskák állatok, tehát Tuna egy állat. Mivel bárkit, aki megöl egy állatot, senki sem szeret, tudjuk, hogy Jankót nem szereti senki. Másrészt, Jankó minden állatot szeret, tehát valaki szereti őt, tehát ez az ellentmondás áll fenn. Így tehát a Kíváncsiság ölte meg a macskát.
A bizonyítás képes megválaszolni a „A Kíváncsiság ölte meg a macskát?” kérdést, de gyakran ennél általánosabb kérdéseket akarunk feltenni, mint például: „Ki ölte meg a macskát?” A rezolúció meg tudja válaszolni ezt is, de ennek a válasznak a levezetése egy kicsit több munkát igényel. A célállítás a ∃w Megöli(w, Tuna), amely negáláskor CNF-ben ¬Megöli(w, Tuna) lesz. Megismételve a bizonyítást a 9.12. ábrán az új negált céllal, hasonló bizonyítási fát kapunk, de a következő helyettesítéssel: {w/Kíváncsiság} az egyik lépésben. Így ebben az esetben, annak a kiderítése, hogy ki ölte meg a macskát, nem áll másból, mint a lekérdezés változóiban lévő lekötések nyomon követése a bizonyításban.
Sajnos, a rezolúció csak nem konstruktív bizonyítást (nonconstructive proofs) tud előállítani az egzisztenciális célmondatokra. Például a ¬Megöli(w, Tuna) rezolválható a Megöli(Jankó, Tuna) ∨ Megöli(Kíváncsiság, Tuna)-val, hogy a Megöli(Jankó, Tuna) mondatot megkapjuk, amely megint rezolválható ezzel: ¬Megöli(w, Tuna), és így kapjuk meg az üres klózt. Figyeljük meg, hogy ebben a bizonyításban a w-nek két különböző lekötése van. A rezolúció megmutatja azt, hogy igen, valaki megölte Tunát – vagy Jankó, vagy a Kíváncsiság. Ez nem túl meglepő! Egy lehetséges megoldás korlátozni a rezolúciós lépéseket úgy, hogy a kérdés változóinak csak egy lekötésük lehessen egy adott bizonyításban, majd képesnek kell lennünk arra, hogy visszakövessük a lehetséges lekötéseket. Egy másik megoldás egy speciális válasz literál (answer literal) hozzáadása a negált célhoz, amelyből ez lesz: ¬Megöli(w, Tuna) ∨ Válasz(w). Ilyenkor a rezolúciós folyamat mindig generál egy pontosan egy literált tartalmazó választ, amikor egy ilyan klóz generálódik. A 9.12. ábrán látható bizonyításra ez a Válasz(Kíváncsiság).A nem konstruktív bizonyítás ezt a klózt generálná: Válasz(Kíváncsiság) ∨ Válasz(Jankó), amely nem ad számunkra választ.
9.12. ábra - Egy rezolúciós bizonyítása annak, hogy a Kíváncsiság ölte meg a macskát. Figyeljük meg a faktorálás használatát a Szereti(G(Jankó), Jankó) klóz származtatásánál.
Ebben a részben bebizonyítjuk a rezolúció teljességét. A fejezet elolvasását nyugodtan kihagyhatja bárki, aki megelégszik azzal, hogy elhiszi ezt az állítást.
Be fogjuk mutatni, hogy a rezolúció cáfolásteljes (refutation-complete), ami azt jelenti, hogy ha egy mondathalmaz kielégíthetetlen, akkor a rezolúció mindig képes levezetni egy ellentmondást. A rezolúció nem alkalmazható arra, hogy mondatok egy halmazának összes logikai következményét generálja, de használható arra, hogy megmondjuk, hogy egy adott mondat következménye-e a mondathalmaznak. Így alkalmazható egy adott kérdésre adható összes válasz megtalálására, felhasználva a korábban a fejezetben már bemutatott célnegálás módszert.
Fontos
Tényként tekintjük, hogy minden (egyenlőséget nem tartalmazó) elsőrendű logikai mondat átírható CNF-klózok halmazára. Ez a mondat alakján végzett indukciós bizonyítással igazolható, az atomi mondatból, mint alapesetből kiindulva (Davis és Putnam, 1960). Célunk tehát bizonyítani a következőt: ha S egy kielégíthetetlen klózhalmaz, akkor az S-en elvégzett véges számú rezolúciós lépés alkalmazása ellentmondáshoz vezet.
Bizonyításunk váza követi Robinson eredeti bizonyítását, néhány Geneserethtől és Nilssontól származó egyszerűsítés hozzáadásával (Genesereth és Nilsson, 1987). A 9.13. ábra mutatja be a bizonyítás alapvető struktúráját, ami a következő:
-
Először megvizsgáljuk, hogy ha S kielégíthetetlen, akkor létezik S klózai között bizonyos alappéldányoknak egy olyan halmaza, ami szintén kielégíthetetlen. (Herbrand-tétel).
-
Ekkor az alap rezolúciós tételhez (ground resolution theorem) fordulunk, amelyet a 7. fejezetben adtunk meg, és amely kijelenti, hogy a propozíciós rezolúció teljes az alapmondatokra.
-
Ezután alkalmazzuk a kiterjesztéslemmát (lifting lemma) annak megmutatására, hogy bármely propozíciós rezolúciós bizonyításhoz, amely alapmondatok halmazát használja, található olyan elsőrendű rezolúciós bizonyítás, amely azokat az elsőrendű logikai mondatokat használja, amelyekből az alapmondatokat megkaptuk.
Az első lépés elvégzéséhez szükségünk lesz három új fogalomra:
-
Herbrand-univerzum: Ha S a klózok egy halmaza, akkor a HS a Herbrand-univerzuma S-nek, vagyis az összes alaptermből álló halmaz, amelyet létrehozhatunk a következőkből:
-
Az S függvény szimbólumai, ha vannak ilyenek.
-
Az S konstansszimbólumai, ha vannak ilyenek. Ha nincs ilyen, akkor az A konstans szimbólum.
-

Például, ha az S csak a ¬P(x, F(x, A)) ∧ ¬Q(x, A) ∨ R(x, B) klózt tartalmazza, akkor a HS az alapmondatok következő végtelen halmaza:
{A, B, F(A, A), F(A, B), F(B, A), F(B, B), F(A, F(A, A)), …}
-
Telítődés: Ha S a klózok egy halmaza, és P az alaptermek egy halmaza, és P(S) az S telített halmaza P-re vonatkoztatva, akkor P(S) az összes alapklóz halmaza, amelyet úgy kapunk meg, hogy alkalmazzuk az összes lehetséges konzisztens helyettesítését a P-beli alaptermeknek az S-beli változókkal.
-
Herbrand-bázis: Egy S klózhalmaznak a hozzá tartozó Herbrand-univerzumra vonatkozó telítődését S Herbrand-bázisának nevezzük, és HS(S)-sel jelöljük. Például, ha S csak a korábban példaként használt klózt tartalmazza, akkor a HS(S) a következő végtelen klózhalmaz :
{¬P(A, F(A, A)) ∨ ¬Q(A, A) ∨ R(A, B),
¬P(B, F(B, A)) ∨ ¬Q(B, A) ∨ R(B, B),
¬P(F(A, A), F(F(A, A), A)) ∨ ¬Q(F(A, A), A) ∨ R(F(A, A), B)
¬P(F(A, B), F(F(A, B), A)) ∨ ¬Q(F(A, B), A) ∨ R(F(A, B), B), …}
Ezek a definíciók lehetővé teszik, hogy a Herbrand-tétel (Herbrand’s theorem) egyik formáját állítsuk:
|
Ha a klózok egy S halmaza nem kielégíthető, akkor létezik egy véges HS(S) részhalmaz, amely szintén nem kielégíthető. |
||
| --(Herbrand, 1930) | ||
Legyen S′ ez a véges részhalmaza az alapmondatoknak. Mármost, alkalmazhatjuk az alap rezolúciós tételt („A rezolúció teljessége” részben), hogy kimutassuk, hogy a rezolúciós! lezárt (resolution! closure) RC(S′) tartalmazza az üres klózt. Ez azt jelenti, hogy a propozíciós rezolúció futtatása a teljességig az S′-en egy ellentmondást fog eredményezni.
Fontos
Gödel nemteljesség tétele
A matematikai indukciós sémákkal (mathematical induction schema) kibővítve az elsőrendű logikát, Gödel nemteljesség tétele (incompleteness theorem) megmutatta, hogy léteznek olyan igaz aritmetikai mondatok, amelyek nem bizonyíthatók.
A nemteljesség elmélet igazolása mintegy 30 oldalt kívánna, így túlmutat ennek a könyvnek a keretein, de a bizonyítás lényegét felvázoljuk a következőkben. Először a számok logikai elméletét vezetjük be. Ebben az elméletben egyetlen konstans létezik, a 0, és egyetlen függvény, az S (az utód-függvény). Az így létrehozott modellben S(0) fejezi ki az 1-et, S(S(0)) jelöli a 2-t és így tovább. A nyelv tehát alkalmas az összes természetes szám kifejezésére. A nyelv szótára tartalmazza ezenkívül a +, a × és az exp (exponenciális) függvényszimbólumokat és a logikai összekötőjelek és a kvantorok szokásos halmazát. Először figyeljük meg, hogy a nyelv mondatai megszámozhatók. (Definiáljunk alfabetikus sorrendet a szimbólumok között, és rendezzük alfabetikus sorrendbe a nyelv 1, 2, …, n, … hosszúságú mondatait.) Így minden α mondathoz hozzárendelhetünk egy egyedi #α természetes számot, a Gödel-számot (Gödel number). Fontos tehát, hogy a számelmélet minden saját mondatához tartalmaz egy nevet. Hasonlóan megszámozhatunk minden egyes P bizonyítást egy G(P) Gödel-számmal, mivel egy bizonyítás nem más, mint mondatok véges sorozata.
Most tegyük fel, hogy adott egy A halmaz, amely a természetes számokról igaz állításokat megfogalmazó mondatokat tartalmaz. Mivel az A halmaz megadható egész számoknak egy adott halmazával (az A halmazban található mondatok Gödel-számaival), ezért létre tudunk hozni a definiált nyelvben egy α(j, A) mondatot, amely a következő állítás:
∀i i nem a Gödel-száma a j Gödel-számú mondat olyan bizonyításának, amely bizonyítás csak A-beli premisszákat használ.
Legyen a σ az α(#σ, A) mondat, vagyis egy olyan mondat, amely kifejezi önmagának a bizonyíthatatlanságát A-ból. (Igazolható, hogy ilyen mondat mindig létezik, de nem egyszerű ezt belátni.)
Kövessük végig a következő ügyes érvelést. Tegyük fel, hogy σ bizonyítható A-ból, de akkor σ hamis, mivel σ épp azt mondja ki, hogy nem igazolható. Ebben az esetben viszont létezik egy hamis mondat, ami bizonyítható A-ból, így A nem tartalmazhatna csak igaz mondatokat – ez az előzetes feltételezésünkkel ellentétes. Tehát σ nem bizonyítható A-ból. Ez viszont éppen az, amit σ állít saját magáról, tehát σ egy igaz mondat.
Tehát megmutattuk (29 és fél oldalnyi levezetést átugorva), hogy bármely, a számelméletben definiálható igaz mondatokat tartalmazó halmaz esetében, bizonyos alapaxiómák feltételezése mellett, léteznek olyan igaz mondatok, amelyek nem bizonyíthatók az axiómákból. Ez az eredmény, más következmények mellett azt jelenti, hogy a matematika bármely axiómarendszerében megfogalmazható olyan tétel, amely nem bizonyítható az adott rendszer axiómáiból. Ez a matematikának egy igen fontos eredménye. A Gödel-tétel hatását a mesterséges intelligencia területére sokan vitatták, köztük maga Gödel is. A 26. fejezetben visszatérünk erre a kérdésre.
Most, hogy megállapítottuk, hogy mindig van egy rezolúciós bizonyítás, amely magában foglal néhány véges részhalmazt a Herbrand S bázisból, a következő lépés annak megmutatása, hogy létezik egy rezolúciós bizonyítás, amely magának az S-nek a klózait tartalmazza, amelyek nem szükségszerűen alapklózok. Azzal kezdjük, hogy megvizsgáljuk a rezolúciós szabály egy egyszerű alkalmazását. Robinson alaplemmája magába foglalja a következő tényt:
Legyen C1 és C2 két klóz, amelyeknek nincsenek közös változói. Legyenek C1′ és C2′ az alappéldányai C1-nek és C2-nek. Ha C′ rezolvense C1′-nek és C2′-nek, akkor létezik egy olyan C klóz, amelyik (1) rezolvense C1-nek és C2-nek és (2) C′ alappéldánya C-nek.
Ezt kiterjesztéslemmának (lifting lemma) nevezik, mivel kiterjeszti a bizonyítási lépést az alap klózokról az általános elsőrendű klózokra. A kiterjesztési lemma bizonyításához Robinsonnak szüksége volt az egyesítés módszerének megalkotására és a legáltalánosabb egyesítő tulajdonságainak levezetésére is. A bizonyítás áttekintése helyett a következőkben illusztráljuk a lemmát:
C1 = ¬P(x, F(x, A)) ∨ ¬Q(x, A) ∨ R(x, B)
C2 = ¬N(G(y), z)) ∨ P(H(y), z)
C'1 = ¬P(H(B), F(H(B), A)) ∨ ¬Q(H(B), A) ∨ R(H(B), B)
C'2 = ¬N(G(B), F(H(B), A)) ∨ P(H(B), F(H(B), A))
C' = ¬N(G(B), F(H(B), A)) ∨ ¬Q(H(B), A) ∨ R(H(B), B)
C = ¬N(G(y), F(H(y), A)) ∨ ¬Q(H(y), A) ∨ R(H(y), B)
Látható, hogy C′ valóban C alaptermje. Általánosságban ahhoz, hogy C1′-nek és C2′-nek legyen rezolvense, úgy kell létrehozni őket, hogy először a C1-beli és a C2-beli komplemens literálok legáltalánosabb egyesítőjét alkalmazzuk C1-re és C2-re. A kiterjesztési lemma felhasználásával könnyű hasonló állításokat levezetni a rezolúciós szabály alkalmazásának bármely sorozatára:
Bármely az S′ lezárásához tartozó C′ klózhoz létezik egy S lezárásában levő C klóz, amelyre a C′ klóz a C klóz alappéldánya, és a C levezetése azonos hosszúságú a C′ levezetésével.
Ebből a tényből következik, hogy ha S′ lezárásában megjelenik az üres klóz, akkor ez szintén megtalálható az S rezolúciós lezárásában. Ez azért van, mivel az üres klóz semmilyen más klóznak sem alappéldánya. Összefoglalva: megmutattuk, hogyha S nem kielégíthető, akkor létezik az üres klóznak egy véges méretű rezolúciós szabályt alkalmazó levezetése.
Az elmélet bizonyításában az alapklózokról az elsőrendű klózokra történő kiterjesztés az állítás erejének igen jelentős növelése. Ez abból következik, hogy az elsőrendű bizonyításban már csak annyiszor kell a változókat helyettesíteni, amennyiszer ez a bizonyításhoz szükséges, míg az alapklózmódszereknél szükséges volt nagyszámú önkényes példányosítást megvizsgálni.
Az ebben a fejezetben az eddig leírt következtetési módszerek közül egyik sem foglalkozott az egyenlőséggel. Három jól elkülöníthető megközelítést alkalmazhatunk. Az első az, hogy axiómákkal látjuk el az egyenlőséget – vagyis leírunk mondatokat az egyenlőségi relációról a tudásbázisban. El kell mondanunk, hogy az egyenlőség reflexív, szimmetrikus, tranzitív, és hogy az egyenlők helyettesíthetők egyenlőkkel bármely predikátumban vagy függvényben. Ezért van szükségünk három alapaxiómára, majd ezután egy továbbira minden egyes predikátumhoz vagy függvényhez:
∀x x = x
∀x, y x = y ⇒ y = x
∀x, y, z x = y ∧ y = z ⇒ x = z
∀x, y x = y ⇒ (P1(x) ⇔ P1(y))
∀x, y x = y ⇒ (P2(x) ⇔ P2(y))
.
.
.
∀w, x, y, z w = y ∧ x = z ⇒ (F1(w, x) = F1(y, z))
∀w, x, y, z w = y ∧ x = z ⇒ (F2(w, x) = F2(y, z))
.
.
.
Mikor ezek a mondatok adottak, egy standard következtetési eljárás, mint amilyen a rezolúció elvégezhet olyan feladatokat, amelyek egyenlőségi következtetést igényelnek, mint például a matematikai egyenletek megoldása.
Az egyenlőség kezelésének másik módja egy további következtetési szabály alkalmazása. A legegyszerűbb szabály, a demoduláció (demodulation) vesz egy egységklózt, x = y és helyettesíti az y-t bármely termmel, ami x-szel egyesíthető egy másik klózban. Formálisabban kifejezve ezt kapjuk:
-
Demoduláció. Bármely x, y és z termekre, ahol
EGYESÍT(x, z) = θ, és az mn[z] egy literál, ami tartalmazza a z-t.
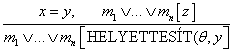
A demodulációt jellemzően arra használják, hogy leegyszerűsítsen állítások kollekcióit használó kifejezéseket, mint például x + 0 = x, x1 = x és így tovább. A szabályt ki lehet terjeszteni, hogy olyan nem egység klózokkal is tudjon foglalkozni, amelyekben egy egyenlőségi literál megjelenik.
-
Paramoduláció (paramodulation). Bármely x, y és z termre, ahol az
EGYESÍT(x, z) = θ
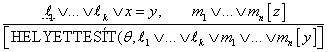
A demodulációval ellentétben a paramoduláció egy teljes következtetési eljárást eredményez az egyenlőséggel rendelkező elsőrendű logikában.
Egy harmadik megközelítés az egyenlőségi következtetést teljes mértékben egy kiterjesztett egyesítési algoritmuson belül kezeli. Ez azt jelenti, hogy a termek egyesíthetők, ha bizonyíthatóan egyenlők egy bizonyos helyettesítés alatt, ahol a „bizonyíthatóan” lehetővé tesz egy bizonyos mennyiségű egyenlőségi következtetést. Például, azok a termek, hogy 1 + 2 és 2 + 1 normális esetben nem egyesíthetők, de egy egyesítési algoritmus, amely ismeri, hogy x + y = y + x, tudná őket egyesíteni az üres helyettesítéssel. Az ilyen fajta egyenleti egyesítés (equational unification) elvégezhető hatékony algoritmusokkal, amelyeket arra terveztek, hogy a felhasznált bizonyos axiómákat használja (kommutativitás, asszociativitás és így tovább), ahelyett hogy explicit következtetéseket tenne ugyanazokkal az axiómákkal. A tételbizonyítások, amelyek ezt a technikát használják, szoros kapcsolatban állnak a korlátozott logikai programozási rendszerekkel, amelyeket a 9.4. alfejezetben írtunk le.
Tudjuk, hogy a rezolúció ismételt alkalmazása megtalálja a bizonyítást, ha létezik. Ebben a részben olyan stratégiákat tekintünk át, amelyek hatékonyan segítenek megtalálni a bizonyításokat.
Ez a stratégia előnybe helyezi azoknak a mondatoknak az alkalmazását, amelyek egyetlen literált tartalmaznak (szokták ezeket egységklóznak (unit clause) is nevezni). A stratégia alapötlete az, hogy próbáljunk meg létrehozni egy üres klózt, így tehát jó ötlet lehet előnyben részesíteni az olyan következtetéseket, amelyek rövidebb klózokat hoznak létre. Egy egységmondat feloldása (mint amilyen a P) egy bármely más mondattal (mint amilyen a ¬P ∨ ¬Q ∨ R), mindig egy olyan klózt eredményez (ebben az esetben: ¬Q ∨ R ), amely rövidebb lesz, mint a másik klóz. Amikor az egységpreferencia-stratégiát először alkalmazták az ítéletkalkulusban, akkor ez drámai gyorsulást eredményezett, megvalósíthatóvá téve olyan bizonyítások elvégzését, amelyek a preferenciák meghatározása nélkül nem voltak kivitelezhetők. Az egységpreferencia azonban önmagában nem csökkenti le eléggé az elágazások számát a közepes méretű problémákban ahhoz, hogy ezek kezelhetők legyenek rezolúcióval. Mindenesetre a módszer egy hasznos heurisztika, amit jól lehet kombinálni más stratégiákkal.
Az egységrezolúció (unit resolution) a rezolúció egy korlátozott formája, amelyben minden rezolúciós lépésnek tartalmaznia kell egy egységklózt. Az egységrezolúció általában nem teljes, de a Horn-tudásbázisokban teljes. Az egységrezolúciós bizonyítások a Horn-tudásbázisokon emlékeztetnek az előrefelé láncolásra.
Hasznosak azok a módszerek, amelyek megpróbálják meghatározni, hogy melyik rezolúciót érdemes először elvégezni, de még hatékonyabbak, ha megpróbáljuk kizárni a lehetséges rezolúciók egy csoportját is. A támogató halmaz (set of support) stratégia pontosan ezt teszi. Az eljárás mondatok egy halmazának kiválasztásával kezdődik, amelyet támogató halmaznak nevezünk. Minden rezolúció egy támogató halmazbeli elemet és egy másik, nem halmazbeli elemet kombinál össze, és hozzáadja a rezolvenst a támogató halmazhoz. Ha a támogató halmaz viszonylag kicsi a tudásbázishoz képest, akkor a módszer alkalmazása jelentős mértékben lecsökkenti a keresési teret.
Óvatosan kell alkalmaznunk a megközelítést, mivel az algoritmus nem lesz teljes, ha a támogató halmazt rosszul választjuk meg. Ha az S támogató halmazt úgy választjuk meg, hogy a maradék mondatok együttesen kielégíthetők, akkor a támogató halmaz stratégiáját alkalmazó rezolúció teljes. Elterjedt módszer, hogy a negált lekérdezés mondatot használjuk támogató halmazként, azt feltételezve, hogy az eredeti tudásbázis konzisztens. (Végül is, ha a tudásbázis nem konzisztens, akkor a lekérdezésből következtethető tény is jelentés nélküli.) A támogató halmaz stratégiának további előnye, hogy a létrehozott bizonyítási fák célorientáltak, így az olvasók számára könnyen érthetők.
A bemeneti rezolúció (input resolution) stratégiában minden rezolúció egy (tudásbázisbeli vagy lekérdező-) mondatot kombinál más mondatokkal. A 9.11. ábrán látható bizonyítás csak bemeneti rezolúciót használ. Ezt az ábrákon sok oldalkapcsolattal rendelkező vonal jellemzi, ahol a kapcsolódásokon egyedi mondatok találhatók. Egyértelmű, hogy az ilyen alakú bizonyítási fák mérete kisebb, mint bármely más bizonyítási fáé. Horn formájú tudásbázisok esetében a Modus Ponens egyfajta bemeneti rezolúciós stratégia, mivel mindig az eredeti TB egy mondatát kombinálja egy másik mondattal. Így nem meglepő, hogy a bemeneti rezolúció teljes a Horn formájú tudásbázisok esetében, de nem teljes általános esetben. A lineáris rezolúció (linear resolution) stratégia egy olyan általánosítás, amely megengedi, hogy P és Q együtt szerepeljenek a rezolúcióban, ha P eredeti eleme a TB-nek, vagy ha P leszármazottja Q-nak a bizonyítási fában. A lineáris rezolúció teljes eljárás.
A bennfoglalás (subsumption) módszere kizárja a keresésből azokat a mondatokat, amelyek benne foglaltatnak (például mert specifikusabbak) más tudásbázisbeli mondatokban. Például ha P(x) megtalálható a tudásbázisban, akkor nincs értelme hozzáadni P(A)-t, még kevesebb értelme van hozzáadni P(A) ∨ Q(B)-t. A bennfoglalás segít kis méreten tartani a TB-t, amely a keresési tér méretének csökkentését eredményezi.
A tételbizonyítók (amelyeket automatizált következtetőknek is szoktunk nevezni) két szempontból különböznek a logikai programozási nyelvektől. Először is a legtöbb logikai programozási nyelv csak Horn klózokkal dolgozik, ezzel szemben a tételbizonyítások elfogadják a teljes elsőrendű logikát. Másodszor, a Prolog programok egymásba fűzik a logikát és a kontrollt. Ha a programozó választása az A:-B, C-re esik az A:-C, B helyett, ez a program végrehajtására van hatással. A legtöbb tételbizonyításban a mondatok választott szintaktikai formája nincs hatással a kapott eredményekre. A tételbizonyításoknak is szükségük van az információ kontrolljára, hogy hatékonyan működhessenek, de ezt az információt általában külön tárolják a tudásbázistól, ahelyett, hogy magának a tudásreprezentációnak a részeként jelenne meg. A legtöbb kutatás a tételbizonyítások tárgyában magában foglalja az általában hasznos kontrollstratégiákat, amelyek a sebességet is növelhetik.
Ebben a részben leírjuk az OTTER (Organized Techniques for Theoremproving and Effective Research) nevű tételbizonyítót (McCune, 1992), különös figyelmet fordítva a vezérlési stratégiájára. Ahhoz, hogy egy problémát készítsen elő az OTTER számára, a felhasználónak négy részre kell osztania a tudásbázist:
-
Egy klózhalmazra, melyet támogató halmaznak (set of support) (vagy sos-nek) nevezünk, és amely definiálja a problémáról szóló legfontosabb tényeket. Minden rezolúciós lépés a támogató halmaz egy tagját rezolválja egy másik axiómához képest, tehát a keresést a támogató halmazra koncentráljuk.
-
A használható axiómákra (usable axioms), amely egy halmaz a támogató halmazon kívül. Ez háttértudást biztosít a problématerületről. A határ megválasztása a probléma részei (tehát ami az sos-en belül van) és a háttér (tehát a használható axiómák) között a felhasználó megítélésén múlik.
-
Az egyenletek egy halmazára, amelyeket átírásoknak (rewrites) vagy demodulátoroknak (demodulators) nevezünk. Habár a demodulátorok egyenletek, mindig balról jobbra irányban alkalmazzák őket. Így tehát egy kanonikus formát határoznak meg, amelyben az összes term leegyszerűsödik. Például az x + 0 = x demodulátor kimondja, hogy minden termet az x + 0 formában az x termmel kell helyettesíteni.
-
Paraméterek és klózok egy halmazára, amelyek meghatározzák a vezérlési stratégiát. A felhasználónak egy heurisztikus funkciót szükséges specifikálni, hogy kontrollálja a keresést, és egy szűrő funkciót, hogy kitöröljön néhány lényegtelen részcélt.
Az OTTER úgy működik, hogy folyamatosan rezolválja a támogatóhalmaz egy elemét az egyik használható axiómával szemben. A Prologgal ellentétben, ez egy „a legjobbat-először” keresést használ. A heurisztikus funkciója megméri minden egyes klóz „súlyát”, ahol a könnyebb klózokat részesíti előnyben. A heurisztika egzakt kiválasztása a felhasználón múlik, de általában a klóz súlyának korrelálnia kell a méretével vagy a nehézségével.
9.14. ábra - Az
OTTER tételbizonyítás vázlata. A heurisztikus kontrollt alkalmazzák a „legkönnyebb” klóz kiválasztására és a FILTER funkcióban, amely kitörli a jelentéktelen klózokat a további vizsgálatból.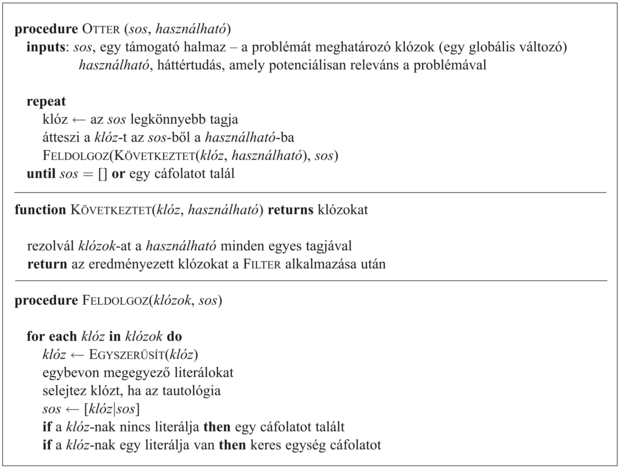
Az egységklózokat könnyűként kezeljük; így tehát a keresést az egységpreferencia-stratégia általánosításának tekinthetjük. Minden egyes lépésnél az OTTER átteszi a „legkönynyebb” klózt a támogatóhalmazból a használható listára, és hozzáadja a használható listához a legkönnyebb klóz és a használható lista elemeinek rezolválásakor keletkezett néhány közvetlen következményt. Az OTTER leáll, amikor talál egy cáfolatot, vagy amikor nincs több klóz a támogatóhalmazban. Az algoritmus a 9.14. ábrán látható részletesebben.
Egy tételbizonyító létrehozásának alternatív módja, ha a Prolog fordítóból indulunk ki, és ezt kiterjesztjük úgy, hogy egy helyes és teljes következtetőgépet kapjunk a teljes elsőrendű logikához. Ezt a megközelítést alkalmazták a Prolog Technológia Tételbizonyítóban (Prolog Technology Theorem Prover, PTTP) (Stickel, 1988). A PTTP négy jelentős változtatást tartalmaz a Prologhoz képest, hogy helyreállítsa a teljességet és a kifejezőképességet:
-
Az előfordulási próba visszakerül az egyesítési folyamatba, hogy azt biztosabbá tegye.
-
A mélységi keresést felváltja egy iteratívan mélyülő keresés. Ez a keresési stratégiát teljessé teszi, és csak egy konstans értékkel vesz több időt igénybe.
-
A negált literálok (mint a ¬P(x)) engedélyezettek. A megvalósításban két különálló folyamat van, az egyik a P-t akarja bebizonyítani, a másik a ¬P-t.
-
Egy n atommal rendelkező klóz n különböző szabályként kerül tárolásra. Például az A ⇐ B ∧ C-t úgy is tárolnánk, mint ¬B ⇐ C ∧ A és úgy is, mint ¬C ⇐ B ∧ ¬A. Ez a technika, amelyet zárásnak (locking) nevezünk, azt eredményezi, hogy az aktuális célt csak minden egyes klóz fejével kell egyesíteni, de még így is lehetővé teszi a negálás helyes kezelését.
-
A következtetést teljessé teszik (még a nem Horn-klózokra is) a lineáris bemeneti szabály hozzáadásával: ha a z aktuális cél egyesül a veremben lévő egyik cél negáltjával, akkor azt a célt rezolváltnak kell tekinteni. Ez egy módja az ellentmondásokkal való következtetésnek. Tételezzük fel, hogy az eredeti cél a P, és ezt redukáltuk következtetések sorozatával a ¬P célra. Ez a ¬P ⇒ P mondatra vezet, amely logikailag egyenértékű a P-vel.
A felsorolt változtatások ellenére a PTTP megőrzi azokat a tulajdonságokat, amelyek a Prologot gyorssá teszik. Az egyesítések még így is a változók közvetlen változtatásával történnek úgy, hogy a lekötések feloldása a visszalépés során az útvonal lezárásával együtt történik. A keresési stratégia itt is a bemeneti rezolúción alapszik, ami azt jeleneti, hogy minden rezolúció a probléma egyik eredeti kijelentésében megadott klózzal szemben történik (és nem egy származtatott klózzal). Ez lehetővé teszi a probléma eredeti kijelentésében adott összes klóz lefordítását.
A PTTP fő hátránya az, hogy a felhasználó elveszít minden vezérlési lehetőséget a megoldások keresése során. Minden következtetési szabályt a rendszer mind az eredeti, mind a kontrapozitív formájában felhasznál. Ez nehezen értelmezhető kereséseket eredményez. Például figyeljük meg ezt a szabályt:
(f(x, y) = f(a, b)) ⇐ (x = a) ∧ (y = b)
Prolog szabályként tekintve, ez is egy következetes módja annak a bizonyításának, hogy két f term megegyezik. De a PTTP még a kontrapozitív állítást is generálhatja:
(x ≠ a) ⇐ (f(x, y) ≠ f(a, b)) ∧ (y = b)
Úgy tűnik, hogy ez igen fáradságos módja annak, hogy bizonyítsuk két term, x és a különbözőségét.
Eddig úgy tekintettünk a következtető rendszerekre, mint független ágensre, amelynek önállóan kell döntéseket hoznia és cselekednie. A tételbizonyítások másik felhasználása, amikor segítőként használjuk, és tanácsokkal lát el, mondjuk egy matematikust. Ebben a használati módban a matematikus felügyelőként viselkedik, feltérképezi a következő lépés meghatározásának stratégiáját, hogy mi legyen, és megkéri a tételbizonyítót, hogy töltse ki a részleteket. Egy bizonyos fokig mellékessé teszi a félig eldönthetőség problémáját, mivel a felügyelő megszüntethet egy lekérdezést, és próbálhat egy másik megközelítést, ha a lekérdezés túl sok időt vesz igénybe. A tételbizonyítás bizonyítás-ellenőrzőként (proof checker) is működhet, ahol a bizonyítást mi adjuk meg vázlatosan, nagyobb lépések sorozataként, és a rendszer tölti ki az egyedi következtetések részleteit, amelyek igazolják lépéseink helyességét.
A Socratic következtető (Socratic reasoner) egy tételbizonyító, amelynek a KÉRDEZ függvénye nem teljes, de amely mindig elérkezhet egy megoldáshoz, ha a megfelelő kérdéssorozatot tesszük fel. Így tehát a Socratic következtetők jó segítők, feltéve, ha van egy felügyelő, aki a megfelelő KÉRDEZ hívásokat összeállítja. Az ONTIC (McAllester, 1989) egy Socratic következtető rendszer matematikai tételbizonyításhoz.
A tételbizonyítók újszerű matematikai eredményeket produkáltak. A SAM (Semi-Automated Mathematics) program volt az első, amely bebizonyított egy lemmát a rácselméletben (Guard és társai, 1969). Az AURA program szintén nyitott kérdéseket válaszolt meg a matematika különféle területein (Wos és Winker, 1983). A Boyer–Moore-tételbizonyítót (Boyer és Moore, 1979) sok éven keresztül használták és bővítették. Natarajan Shankar ezt használta fel, hogy megadja az első teljes, precíz formális bizonyítását Gödel nemteljesség tételének (Shankar, 1986). Az OTTER program az egyik legerősebb tételbizonyító. Használták a kombinatorikus logika néhány nyitott kérdésének megoldására. A legismertebb ezek közül a Robbins-algebra. 1933-ban Herbert Robbins egy egyszerű axiómasorozatot javasolt, amely a Boole-algebra definiálására látszott alkalmasnak, de nem találtak hozzá bizonyítást (több matematikus, köztük Alfred Tarski, jelentős munkája ellenére). 1996. október 10-én, nyolc nap számítás után az EQP (az OTTER egyik változata) megtalálta a bizonyítást (McCune, 1997).
A tételbizonyításokat alkalmazhatjuk a hardver- és szoftvertervezésben a verifikáció (verification) és a szintézis (synthesis) során felmerülő problémákra, mivel mindkét tárgyterülethez lehetséges megfelelő axiómarendszert definiálni. Így tehát a tételbizonyítási kutatást megtalálhatjuk a hardvertervezés, a programozási nyelvek és a szoftverfejlesztés területein is – nem csupán az MI-ben. A szoftver esetében az axiómák meghatározzák a programozási nyelv minden egyes szintaktikus elemének tulajdonságait. (A programokról történő következtetés eléggé hasonló az akciókról történő következtetéshez a szituációkalkulusban.) Egy algoritmus akkor tekinthető igazoltnak, ha a kimenetei megfelelnek a specifikációnak minden bemenet mellett. Az RSA nyilvános kulcskódolási algoritmust és a Boyer–Moore-féle húrillesztési algoritmust is ilyen módon igazolták (Boyer és Moore, 1984). A hardver esetében az axiómák leírják a jelek és az áramkör elemei közötti interakciókat (lásd a 8. fejezetbeli példát). Egy 16 bites összeadó tervét az AURA igazolta (Wojcik, 1983). A logikai következtetők, amelyeket speciálisan igazolásokra terveztek, egész CPU-kat voltak képesek verifikálni, beleértve ezek időzítési tulajdonságait is (Srivas és Bickford, 1990).
Az algoritmusok formális szintézise volt a tételbizonyítások egyik első felhasználása, amint azt Cordell Green (Green, 1969a) felvázolta, aki Simon korábbi ötleteire támaszkodott (Simon, 1963). Az alapötlet az volt, hogy egyféle módon bizonyítsák azt a tételt, hogy „létezik egy p program, amely eleget tesz egy bizonyos specifikációnak”. Ha a bizonyítást úgy korlátozzuk, hogy konstruktív legyen, a program maga is kinyerhető lesz a bizonyításból. Habár ez egy teljesen automatizált deduktív szintézis (deductive synthesis), legalábbis így nevezzük, még nemigen használható általános célú programok készítésére, ám a kézzel irányított deduktív szintézis már sikeresen tervezett néhány újszerű és bonyolult algoritmust. A speciális célú programok szintézise szintén aktív kutatási terület. Az AURA tételbizonyítót sikerrel alkalmazták a hardverszintézis területén olyan áramkörök tervezésére, amelyek kompaktabbak, mint minden azt megelőző terv (Wojciechowski és Wojcik, 1983). Sok áramkör tervezésénél az ítéletlogika elegendő, mivel a legfontosabb ítéletállítások halmaza rögzített, ugyanis ezek az áramkör elemeit írják le. Az ítéletlogikai következtetés alkalmazása a hardverszintézisben ma már egy standard technika, amelynek sok nagyméretű hálózati alkalmazása létezik (lásd például Nowick és társai, 1993).
Ugyanezeket a technikákat mostanában kezdik el alkalmazni a szoftverek verifikációjához is, például a SPIN modell ellenőrző programmal (Holzmann, 1997). A Remote Agent űrhajó vezérlési programot például sikerült verifikálni a repülés előtt és után (Havelund és társai, 2000).
[92] Egy klózt implikációként is reprezentálhatunk a bal oldali atomok konjunkciójával és a jobb oldali atomok diszjunkciójával, mint azt a 7.12. feladatban láthatjuk. Ezt a formát, amelyet Kowalski-formának (Kowalski form) szoktak nevezni, gyakran sokkal könnyebb kiolvasni, ha az implikációk írása jobbról balra történik (Kowalski, 1979b).
