9.3. Előrefelé láncolás
Az ítéletlogikai határozott klózokra már megadtunk egy előrefelé láncolási algoritmust a 7.5. alfejezetben. A gondolat egyszerű: kezdjük a tudásbázisban szereplő atomi mondatokkal, és alkalmazzuk a Modus Ponenst előrefelé haladva, új atomi mondatokat hozzáadva, egészen addig, amíg további következtetések már nem végezhetők. Most megmutatjuk, hogyan alkalmazzuk az algoritmust az elsőrendű határozott klózokra, és hogyan valósíthatjuk ezt meg hatékonyan. A határozott klózok, mint például a Helyzet ⇒ Válasz különösen hasznosak az olyan rendszerek számára, amelyek újonnan érkezett információk alapján végeznek következtetéseket válaszként. Számos rendszert tervezhetünk ilyen módon, és ezekben az esetekben az előrefelé láncolással történő következtetés sokkal hatékonyabb lehet, mint a rezolúciós tételbizonyítás. Ebből az következik, hogy gyakran érdemes megpróbálni olyan tudásbázist építeni, amely csak határozott klózokat használ, és így elkerülhetjük a rezolúcióval járó nehézségeket.
Az elsőrendű határozott klózok nagyon emlékeztetnek az ítéletlogikai határozott klózokra („A rezolúció teljessége”részben). Az ilyen klózok olyan literálok diszjunkciói, amelyek közül pontosan egy diszjunkt pozitív. Egy határozott klóz vagy egy atomi mondat, vagy egy implikáció, amelynek a feltétel része pozitív literálok konjunkciója, és amelynek következménye egyetlen pozitív literál. A következő mondatok elsőrendű határozott klózok:
Király(x) ∧ Mohó(x) ⇒ Gonosz(x)
Király(János)
Mohó(y)
Eltérően az ítéletlogikai literáloktól, az elsőrendű literálok tartalmazhatnak változókat, amely esetben a változókat univerzális kvantorral ellátottnak tételezzük fel. (A határozott klózok írásánál általában elhagyjuk az univerzális kvantorokat.) A határozott klóz egy megfelelő normál forma, hogy az általánosított Modus Ponensszel alkalmazhassuk. Nem minden tudásbázist lehet átalakítani határozott klózok halmazává, az egyetlen pozitív literális korlátja miatt, de sokat igen. Gondoljuk át a következő problémát:
A törvény kimondja, hogy bűntény az, ha egy amerikai polgár fegyvert ad el egy Amerikával ellenséges nemzetnek. A Nono ország, amely ellensége Amerikának, fel van szerelve rakétákkal, és ezeket a rakétákat mind West ezredes adta el, aki amerikai.
Be fogjuk bizonyítani, hogy West bűnöző. Először leírjuk a tényeinket elsőrendű határozott klózokként. A következő alfejezet fogja bemutatni, hogy az előrefelé láncolás algoritmus hogyan oldja meg a problémát.
„…bűntény az, ha egy amerikai polgár fegyvert ad el egy Amerikával ellenséges nemzetnek”:
Amerikai(x) ∧ Fegyver(y) ∧ Ellenséges(z) ∧ Elad(x, z, y) ⇒ Bűnöző(x) (9.3)
„Nono… fel van szerelve rakétákkal.” Azt a mondatot, hogy ∃x Birtokol(Nono, x) ∧ Rakéta(x) átalakítjuk két határozott klózzá Egzisztenciális Eliminációval, egy új konstans, az M1 bevezetésével:
Birtokol(Nono, M1) (9.4)
Rakéta(M1) (9.5)
„És ezeket a rakétákat mind West ezredes adta el”:
Rakéta(x) ∧ Birtokol(Nono, x) ⇒ Elad(West, x, Nono) (9.6)
Tudnunk kell még, hogy a rakéták fegyverek:
Rakéta(x) ⇒ Fegyver(x) (9.7)
és hogy Amerika ellensége „ellenségesnek” számít:
Ellensége(x, Amerika) ⇒ Ellenséges(x) (9.8)
„West ezredes…, aki amerikai”:
Amerikai(West) (9.9)
„Nono ország, amely ellensége Amerikának…”
Ellensége(Nono, Amerika) (9.10)
A tudásbázis nem tartalmaz függvényszimbólumokat, és így egy példája a Datalog (Datalog) tudásbázisok osztályának – ami függvényszimbólumok nélküli elsőrendű határozott klózok halmaza. Látni fogjuk, hogy a függvényszimbólumok hiánya sokkal könnyebbé teszi a következtetést.
Az első előrefelé láncolási algoritmus, amit megvizsgálunk, nagyon egyszerű lesz, amint azt láthatjuk a 9.3. ábrán. Az algoritmus az ismert tényekből kiindulva végrehajtja az összes olyan szabályt, amelynek premisszái ki vannak elégítve, és ezek következményeit hozzáadja az ismert tényekhez. Ez az eljárás addig ismétlődik, amíg a kérdést meg nem válaszoltuk (feltételezve, hogy csak egy válaszra van szükségünk), vagy amikor már nem tudunk új tényeket a tudásbázishoz hozzáadni. Vegyük észre, hogy egy tény nem számít „újnak”, ha csak átnevezése (rename) egy már ismert ténynek. Egy mondat átnevezése egy másiknak, ha az alkalmazott változók neveitől eltekintve megegyeznek. Például a Szereti(x, Fagylalt) és a Szereti(y, Fagylalt) mondatok egymás átnevezésének számítanak, mert csak az x és az y választásában különböznek. A két mondat jelentése megegyezik: mindenki szereti a fagylaltot.
Az előző bűntényproblémánkat fogjuk felhasználni az ERL-EL-KÉRDEZ algoritmus bemutatásához. Az implikációs mondatok a (9.3), (9.6), (9.7) és a (9.8). Két iterációs lépés szükséges:
-
Az első iterációban a (9.3) szabály nem elégítette ki a premisszákat.
A (9.6) szabályt kielégíti az {x/M1} és az Elad(West, M1, Nono) hozzáadása.
A (9.7) szabályt kielégíti az {x/M1} és a Fegyver(M1) hozzáadása.
A (9.8) szabályt kielégíti az {x/Nono} és az Ellenséges(Nono) hozzáadása.
-
A második iterációban a (9.3) szabályt kielégíti az {x/West, y/M1, z/Nono), és hozzáadjuk azt, hogy: Bűnöző(West).
9.3. ábra - Egy koncepcionálisan egyszerű, de kevéssé hatékony előrefelé láncolási algoritmus. Minden egyes iterációban hozzáadja a TB-hez az összes atomi mondatot, amelyet egy lépésben az implikációs mondatokból és a TB-ben már meglévő atomi mondatokból kikövetkeztethetünk.

9.4. ábra - Az előrefelé láncolás algoritmus által generált bizonyítási fa a bűntény példára. A kiinduló tények az alsó sorban jelennek meg, az első iterációban kikövetkeztetett tények a középső sorban, míg a második iterációban kikövetkeztetett tények a legfelső sorban.
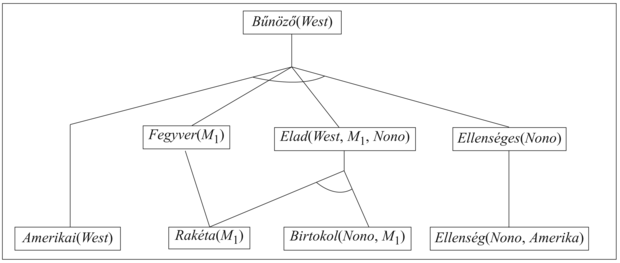
A 9.4. ábra bemutatja a generált bizonyítási fát. Vegyük észre, hogy új következtetések már nem lehetségesek ezen a ponton, mivel minden mondatot, amelyet kikövetkeztethetnénk az előrefelé láncolással, már explicit módon tartalmaz a TB. Egy ilyen tudásbázist a következtetési folyamat fix pontjának (fixed point) nevezzük. Az elsőrendű határozott klózok előrefelé láncolásával létrehozott fix pontok hasonlítanak az ítéletlogikai előrefelé láncolással (7.5.2. szakasz - Előre- és hátrafelé láncolásrészben) generáltakhoz. A leglényegesebb különbség az, hogy egy elsőrendű fix pont tartalmazhat univerzális kvantorral ellátott atomi mondatokat.
A ERL-EL-KÉRDEZ-t könnyű kielemezni. Először is megállapítható, hogy az eljárás helyes (sound), mivel minden következtetés csak az általánosított Modus Ponens alkalmazása, amelyről már igazoltuk, hogy helyes. Másodszor, teljes (complete) a határozott klózokat tartalmazó tudásbázisokra, ami azt jelenti, hogy képes minden olyan lekérdezést megválaszolni, amely következik bármely határozott kózokból álló tudásbázisból. A Datalog tudásbázisok esetére, amelyek nem tartalmaznak függvényszimbólumokat, a teljesség bizonyítása meglehetősen egyszerű. Először megszámoljuk a TB-hez hozzáadható tényeket, amely szám meghatározza az iterációk maximális számát. Legyen a k ez a maximális érték (argumentumok száma) az adott predikátumokra, p a predikátumok száma és n a konstansszimbólumok száma. Egyértelmű, hogy nem lehet pnk különböző alapténynél több, tehát ennyi iteráció után az algoritmus el fog érni egy fix pontot. Ezután már az ítéletlogikai előrefelé láncolás bizonyításánál leírtakhoz nagyon hasonlóan érvelhetünk (7.5.2. szakasz - Előre- és hátrafelé láncolásrészben.) Az ítéletlogikai teljes eljárás átalakítását egy elsőrendű teljes eljárássá a 9.5. alfejezetben mutatjuk majd meg.
Függvényszimbólumokat is tartalmazó általános határozott klózok esetében az ERL-EL-KÉRDEZ végtelen számú új tényt generálhat, így ilyenkor óvatosabbnak kell lennünk. Ha egy lekérdezésre adható válaszmondat levezethető a TB-ből, akkor Herbrand tételét kell alkalmaznunk, hogy biztosítsuk, hogy az algoritmus megtalál egy bizonyítást (lásd a 9.5. alfejezetet a rezolúciós esetre). Ha a lekérdezésre nincs válasz, akkor az algoritmus néhány esetben nem tud leállni. Például ha a tudásbázis a Peano-axiómákat tartalmazza,
TermSzám(0)
∀n TermSzám(n) ⇒ TermSzám(S(n))
akkor az előrefelé láncolás hozzáadja a TermSzám(S(0)), TermSzám(S(S(0))), TermSzám(S(S(S(0)))) mondatokat és így tovább. Általánosságban ezt a problémát nem lehet kikerülni. Hasonlóan, mint az általános elsőrendű logikában, a határozott klózokkal való következtetés félig eldönthető.
A 9.3. ábrán látható előrefelé láncolási algoritmust inkább a megértés megkönnyítése céljából mutattuk be, és nem mint egy hatékonyan végrehajtható algoritmust. A komplexitásnak három lehetséges forrása van. Először is, az algoritmus „belső hurka” elvégzi az összes lehetséges egyesítés megtalálását, ahol egy szabály premisszája egyesíthető a TB egy alkalmas tényhalmazával. Ezt gyakran mintaillesztésnek (pattern matching) nevezzük, és igen költséges lépés. Másodszor, az algoritmus újra ellenőriz minden szabályt minden iterációban, hogy megvizsgálja, hogy a premisszák ki vannak-e elégítve, még olyankor is, amikor nagyon kevés változtatást végzünk a tudásbázisban az egyes ciklusokban. Végül, az algoritmus számos olyan tényt is generálhat, melyek irrelevánsak a cél szempontjából. Mindhárom problémaforrást meg fogjuk vizsgálni.
A szabályok premisszáinak a TB tényeihez történő illesztése egyszerű problémának tűnhet. Például tételezzük fel, hogy a következő szabályt akarjuk alkalmazni:
Rakéta(x) ⇒ Fegyver(x)
Ezután meg kell találnunk az összes tényt, amely egyesíthető a Rakéta(x)-szel. Egy megfelelően indexelt tudásbázisban ez elvégezhető a tények számával lineáris időben. Vizsgáljunk meg egy szabályt, mint amilyen például a:
Rakéta(x) ∧ Birtokol(Nono, x) ⇒ Elad(West, x, Nono)
Itt is megkereshetjük a Nono által birtokolt összes objektumot objektumonként konstans idő alatt. Ezután minden egyes objektumra meg tudjuk vizsgálni, hogy az rakéta-e.
Amennyiben a tudásbázis sok Nono által birtokolt objektumot tartalmaz és nagyon kevés rakétát, akkor azonban célszerűbb lenne először az összes rakétát megkeresni, és aztán ellenőrizni, hogy azokat Nono birtokolja-e. Ez a konjunkt sorrendezés (conjunct ordering) probléma: találjunk egy olyan sorrendet, amely a szabály premissza részének konjunktjait megoldja úgy, hogy ezzel a teljes költséget minimalizáljuk. Megmutatható, hogy az optimális sorrend megtalálása önmagában is NP-nehéz, de egy jó heurisztika elérhető. Például ilyen a legkorlátozottabb változó (most constrained variable) heurisztikája, amelyet az 5. fejezetben a kényszerkielégítési problémákra használtunk. Ez azt a logikát követi, hogy rendezzük sorba a konjunktokat úgy, hogy először a rakétákat keressük, ha kevesebb rakéta van, mint Nono által birtokolt objektum.
Fontos
A kapcsolat a mintaillesztés és a kényszer kielégítése között valójában nagyon szoros. Bármelyik konjunktot úgy tekinthetünk, mint az általa tartalmazott változók korlátozását – például, a Rakéta(x) egy unáris korlátozás az x-en. Ezt a gondolatot kiterjesztve, minden véges tárgyterületű kényszerkielégítési problémát kifejezhetünk egyszeri határozott klózként, néhány társított alapténnyel kiegészítve. Vizsgáljuk meg az 5.1. ábrán látható térképszínezési problémát, amelyet a 9.5. (a) ábrán újra bemutatunk. Egy ezzel megegyező formulát adtunk meg egy határozott klóz formájában a 9.5. (b) ábrán. Világos, hogy a Színezhető() konklúzió csak akkor kikövetkeztethető, ha a kényszerkielégítési problémának van egy megoldása. Mivel a kényszerkielégítési problémák általában magukba foglalják a 3SAT problémákat különleges esetekként, levonhatjuk azt a következtetést, hogy egy határozott klóz illesztése egy tényhalmazhoz NP-nehéz.
9.5. ábra - (a) Ausztrália térképének kiszínezését bemutató kényszergráf (5.1. ábra). (b) A térképszínező kényszerkielégítési probléma egy határozott klózzal reprezentálva. Vegyük észre, hogy a változók tárgyterülete a
KÜL-re megadott alaptények konstansai által implicit módon definiáltak.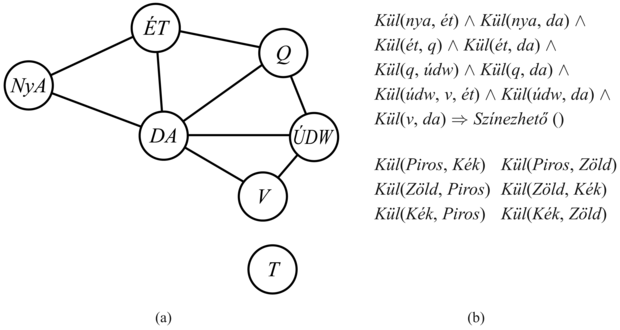
Elég elkeserítőnek tűnhet, hogy az előrefelé láncolás tartalmaz egy NP-nehéz illesztési problémát a belső hurokban. Három módja van annak, hogy felvidítsuk magunkat:
-
Emlékezhetünk arra, hogy a legtöbb szabály a valódi tudásbázisokban kisméretű és egyszerű (mint a bűntény példa szabályai), és nem nagy és komplex (mint a 9.5. ábrán látható kényszerproblémánál). Az adatbázisok területén fel szokták tételezni, hogy mind a szabályok mérete, mind a predikátumok argumantumszáma egy konstanssal megadható korlát alatt marad, és így csak az adatkomplexitás (data complexity) miatt kell aggódni – vagyis a következtetés komplexitása miatt, ami az adatbázisban lévő alaptények számának függvénye. Könnyű megmutatni, hogy az előrefelé láncolás adatkomplexitása polinomiális.
-
Tekinthetjük a szabályok azon csoportját, amelyekre az illesztés hatékony tud lenni. Alapjában véve minden Datalog klózt tekinthetünk úgy, mint ami egy kényszerkielégítési problémát határoz meg, így az illesztés kivitelezhető akkor, ha a megfelelő kényszerkielégítési probléma is nyomon követhető. Az 5. fejezet leírja a kényszerkielégítési problémák néhány praktikusan megoldható családját. Például ha a kényszergráf (egy olyan gráf, amelynek a csomópontjai változók és az élei kényszerek) fát formáz, akkor a kényszerkielégítési probléma lineáris időben megoldható. Pontosan ugyanez a szabály áll fenn a szabályillesztésre. Például ha eltávolítjuk Dél-Ausztráliát a 9.5. ábráról, akkor az új klóz a következő lesz:
Kül(nya, ét) ∧ Kül(ét, q) ∧ Kül(q, údw) ∧ Kül(údw, v) ⇒ Színezhető()
Ez megfelel az 5.11. ábrán bemutatott redukált kényszerkielégítési problémának. A faszerkezetű kényszerkielégítési problémák megoldására használt algoritmusokat közvetlenül alkalmazhatjuk a szabályillesztés problémájára.
-
És végül dolgozhatunk azon, hogy megszüntessük a felesleges szabályillesztési kísérleteket az előrefelé láncolási algoritmusban, amely a következő alfejezet témája lesz.
Fontos
Amikor a bűntény példán bemutattuk az előrefelé láncolás működését, akkor csaltunk, nevezetesen abban, hogy kihagytunk néhány szabályillesztést, amelyet a 9.3. ábrán bemutatott algoritmus elvégzett. Például a második iterációban a:
Rakéta(x) ⇒ Fegyver(x)
szabály (ismét) illeszthető a Rakéta(M1)-hez, és természetesen a Fegyver(M1) konklúziót már ismerjük, így semmi sem történik. Az ilyen felesleges szabályillesztést elkerülhetjük, ha figyelembe vesszük a következő megfigyelést: Minden, α t-edik iterációban kikövetkeztethető új tény levezetéséhez szükséges legalább egy, α t – 1 ciklusban kikövetkeztetett új tény felhasználása. Ez azért igaz, mert bármely olyan következtetés, amely nem igényel egy új tényt a t – 1 ciklusból, már elvégezhető lett volna a t – 1 ciklusban.
Ez a megfigyelés természetes módon elvezet minket egy inkrementális előrefelé láncolási algoritmushoz, ahol a t ciklusban csak akkor ellenőrzünk egy szabályt, ha annak premisszája tartalmaz egy pi konjunktot, amely egyesíthető egy p′i ténnyel, és amelyre újonnan következtettünk a t – 1 ciklusban. A szabályillesztő lépés aztán rögzíti a pi-t, hogy illeszkedjen a p′i-hez, de lehetővé teszi, hogy a szabály többi konjunktja illeszkedjen bármely megelőző ciklus tényeihez. Ez az algoritmus pontosan ugyanazokat a tényeket generálja minden egyes ciklusban, mint amelyeket a 9.3. ábrán látható algoritmus, de annál sokkal hatékonyabb.
Megfelelő indexeléssel könnyű megtalálni azokat a szabályokat, amelyeket egy adott tény kielégíthetővé tehet. Valójában számos rendszer egy ilyen frissítési módban működik, ahol az előrefelé láncolás minden egyes olyan tényre aktualizálódik, amelyet KIJELENT-ettünk a rendszernek. A következtetések sorban végigveszik a szabályok halmazát, amíg el nem érik a fix pontot, és ez a folyamat a következő új ténynél újra kezdődik.
A tudásbázisban lévő szabályoknak tipikusan csak egy kis töredékét eredményezi egy adott tény hozzáadása. Ez azt jelenti, hogy jelentős mennyiségű felesleges munkát végzünk néhány ki nem elégített premisszát is tartalmazó részleges illesztések ismételt létrehozásával. A bűntény példánk túl kicsi ahhoz, hogy ezt megfelelően bemutassuk, de vegyük észre, hogy egy részleges illesztést az első ciklusban már létrehoztunk az:
Amerikai(x) ∧ Fegyver(y) ∧ Elad(x, y, z) ∧ Ellenséges(z) ⇒ Bűnöző(x)
szabály és az Amerikai(West) tény között. Ezt a részleges illesztést aztán kiselejtezzük, de újraépítjük a második ciklusban is (amikor a szabály sikeres). Hatékonyabb lenne megőrizni, és fokozatosan kiegészíteni újabb részleges illesztésekkel, amikor az új tények beérkeznek, ahelyett hogy kiselejteznénk őket.
A rete algoritmus[89] volt az első, amely alaposan foglalkozott ezzel a problémával. Az algoritmus feldolgozza a tudásbázis szabályait, hogy létrehozzon egy adatfolyam-hálózatot, amelyben minden csomópont egy literál egy szabály premissza részéből. Változó lekötések áramlanak a hálózaton, megszűrve azokat, amelyek nem illeszkednek egy literálhoz. Ha egy szabályban két literálnak ugyanaz a változója – például Elad(x, y, z) ∧ Ellenséges(z) a bűnöző példában –, akkor a literálokhoz tartozó lekötések egy egyenlőségi csomóponton mennek keresztül. Egy változó lekötésnek, amely elér egy csomópontot egy n argumentumú literálnál úgy, mint az Elad(x, y, z), várakoznia kell, mielőtt a folyamat újra kezdődne, amíg a többi változóhoz tartozó lekötéseket is létrehozzuk. Egy adott pontban a rete háló állapota megadja a szabályok összes, addig elvégzett részleges illesztéseit, és így elkerülhető a jelentős újraszámolás.
A rete hálók, és más, hatékonyságot növelő fejlesztések mindig is jelentős szerepet játszottak az úgynevezett produkciós rendszerekben (production systems), amelyek az első széles körben használt előrefelé láncolási rendszerek voltak.[90] Az XCON szakértői rendszer (eredetileg R1-nek hívták, McDermott, 1982) egy produkciós rendszer felépítését felhasználva készült. Az XCON néhány ezer szabályt tartalmazott számítógép-tartozékok konfigurációinak megtervezésére a DEC cég vásárlóinak számára. Ez volt az egyik első igazi kereskedelmi siker a szakértő rendszerek feltörekvő piacán. Sok más hasonló rendszer épült ugyanezt a technológiát felhasználva, amelyet be is építettek egy általános célú programozási nyelvbe, az OPS-5-be.
A produkciós rendszerek a kognitív architektúrákban (cognitive architectures), mint például az ACT (Anderson, 1983) vagy a SOAR (Laird és társai, 1987), is népszerűek. A kognitív architektúrák az emberi gondolkodás modelljei. Az ilyen rendszerekben a rendszer „munkamemóriája” az ember rövid távú memóriáját modellezi, és a produkált következmények a hosszú távú memória részei. A működés minden egyes ciklusában a produkciókat a tények munkamemóriájához illesztik. Egy olyan következmény, amelynek feltételeit kielégítik, hozzátehet és kitörölhet tényeket a működő memóriából. Az adatbázisokkal ellentétben a produkciós rendszerekben gyakran sok szabály és viszonylag kevés tény van. Megfelelően optimalizált illesztési technológiával néhány modern rendszer képes valós időben működni több mint egymillió szabállyal is.
Úgy tűnik, hogy a rossz hatékonyság problémájának az utolsó forrása az előrefelé láncolásban a megközelítésből fakad, ez már az ítéletlogikai kontextusban is felmerült. (lásd 7.5. alfejezet). Az előrefelé láncolás az ismert tényeken alapuló összes lehetséges következtetést elvégzi, akkor is, ha azok irrelevánsak az elérendő célhoz. A bűntény példánkban nem voltak olyan szabályok, amelyek irreleváns konklúziókat vontak volna maguk után, így az irányítottság hiánya nem jelentett problémát. Más esetekben (például ha több szabályunk van, amelyek leírják az amerikaiak étkezési szokásait és a rakéták árát is), a ERL-EL-KÉRDEZ számos irreleváns konklúziót fog generálni.
Az irreleváns konklúziók elkerülésének egy lehetséges módja a hátrafelé láncolás használata, amint az a 9.4. alfejezetben látható lesz. Másik megoldás, hogy az előrefelé láncolást a kiválogatott szabályok egy részhalmazára korlátozzuk. Ezt a megközelítést az ítéletlogikai kontextusban már tárgyaltuk. Egy harmadik megközelítést használnak a deduktív adatbázisok területén, ahol az előrefelé láncolás elterjedt eszköznek számít. Az alapötlet az, hogy írjuk át a szabályhalmazt felhasználva a célállítást, hogy aztán csak releváns változó kapcsolatokat – amelyek az úgynevezett mágikus halmazhoz (magic set) tartoznak – vegyük figyelembe az előrefelé következtetésben. Például ha a cél állítás a Bűnöző(West), akkor a szabályt, amely a Bűnöző(x)-re következtet, át kell írni úgy, hogy tartalmazzon egy további konjunktot, amely korlátozza az x értékét:
Mágikus(x) ∧ Amerikai(x) ∧ Fegyver(y) ∧ Elad(x, y, z) ∧ Ellenséges(z) ⇒ Bűnöző(x)
A Mágikus(West) tény is hozzáadódik a TB-hez. Ily módon, még akkor is, ha a tudásbázis amerikaiak millióiról tartalmaz is adatokat, csak West ezredest fogjuk figyelembe venni az előrefelé láncolási folyamatban. A mágikus halmazok definiálásának és a tudásbázis átírásának teljes folyamata túl összetett ahhoz, hogy most itt részletezzük, de az alapötlet egyfajta „generikus” hátrafelé való következtetés elvégzése a célból kiindulva azért, hogy megtaláljuk, mely változókapcsolatokat kell korlátozni. A mágikus halmaz megközelítést egy hibrid algoritmusnak tekinthetjük az előrefelé következtetés és a hátrafelé haladó előfeldolgozó folyamat között.
