9.2. Egyesítés és kiemelés
Az előző alfejezet bemutatta az elsőrendű következtetésnek azt az értelmezését, amely az 1960-as évekig létezett. Az éles szemű olvasók (és bizonyára a hatvanas évek elejének logikával foglalkozó kutatói) észrevehették, hogy az ítéletlogikai megközelítés nem nagyon hatékony. Például ha megnézzük a Gonosz(x) lekérdezést és az ehhez tartozó tudásbázist a (9.1) egyenletben, feleslegesnek tűnik olyan mondatok generálása, mint a Király(Richárd) ∧ Mohó(Richárd) ⇒ Gonosz(Richárd). Valójában a Gonosz(János) mondatra vonatkozó következtetés bárki számára teljesen nyilvánvaló a következő mondatok alapján:
∀x Király(x) ∧ Mohó(x) ⇒ Gonosz(x)
Király(János)
Mohó(János)
Most megmutatjuk, hogyan tehetjük ezt a számítógép számára is egyértelművé.
Az a következtetés, hogy János gonosz a következőképpen megy végbe: találjon egy x-et, amelyre igaz, hogy x egy király és x mohó, majd következtesse ki, hogy x gonosz. Általánosabban, ha van valamely θ helyettesítés, amely az implikáció premisszáját megegyezővé teszi a tudásbázisban már létező mondatokkal, akkor a θ helyettesítés elvégzése után az implikációkövetkezmény részét hozzáadhatjuk a tudásbázishoz. Ebben az esetben az {x/János} helyettesítés eléri ezt a célt.
Tulajdonképpen több feladatot is elvégeztethetünk a következtetés ezen lépésével. Tételezzük fel, hogy a Mohó(János) mondat ismerete helyett csak azt tudjuk, hogy mindenki mohó:
∀y Mohó(y) (9.2)
Ebben az esetben is szeretnénk azt a következtetést levonni, hogy Gonosz(János), mivel tudjuk, hogy János egy király (ez adott), és hogy János mohó (mert mindenki mohó). Egy megfelelő helyettesítés megtalálására van szükségünk ennek elvégzéséhez, mind az implikációs mondatban, mind az ehhez illesztendő mondatokban található változókra. Ebben az esetben az {x/János, y/János} helyettesítés alkalmazása az implikáció Király(x) és Mohó(x) premisszáihoz és a Király(János) és Mohó(y) tudásbázis mondatokhoz létrehozza az azonosságot. Így tehát ki tudjuk következtetni az implikáció konklúzióját.
Ez a következtetés elvégezhető egyetlen következtetési szabály alkalmazásával, amelyet általánosított Modus Ponensnek (Generalized Modus Ponens) nevezünk: a pi, p′i és q atomi mondatokra, amelyekre létezik olyan θ helyettesítés, hogy HELYETTESÍT (θ, p′i) = HELYETTESÍT (θ, pi) minden i-re, akkor:
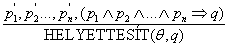
A szabály n + 1 premisszát tartalmaz: n számú p′i atomi mondatot és egy implikációt. A konklúzió a q konzekvenciára történő helyettesítés alkalmazásának az eredménye. A mi példánkra ezt így alkalmazhatjuk:
p′1 – Király(János) p1 – Király(x)
p′2 – Mohó(y) p2 – Mohó (x)
θ – {x/János, y/János} q – Gonosz(x)
Helyettesít(θ, q) – Gonosz(János)
Könnyű megmutatni, hogy az általánosított Modus Ponens helyes következtetési szabály. Először is, megfigyelhetjük, hogy bármely p mondatra (amelyeknek változóiról feltételezzük, hogy univerzális kvantorokkal vannak ellátva) és bármely θ helyettesítésre:
p ⊭ Helyettesít(θ, p)
Ez hasonlóan igazolható, mint az univerzális példányosítás szabály, és alkalmazható olyan θ-ra, amely kielégíti az általánosított Modus Ponens szabály feltételeit. Így tehát, a p1′,…, pn′ -ből következtethetjük, hogy:
Helyettesít(θ, p′1) ∧ … ∧ Helyettesít(θ, p′n)
és a p1 ∧ … ∧ pn ⇒ q implikációból ezt következtethetjük, hogy:
Helyettesít(θ, p1) ∧ … ∧ Helyettesít(θ, pn) ⇒ Helyettesít(θ, q)
Mivel a θ az általánosított Modus Ponensben úgy van definiálva, hogy: HELYETTESÍT (θ, pi′) = HELYETTESÍT (θ, pi) minden i-re; ebből kifolyólag a két mondatból az első pontosan illeszkedik a másodiknak a premisszájához. Így tehát a HELYETTESÍT (θ, q) következik a Modus Ponensből.
Az általánosított Modus Ponens egy kiemelt (lifted) változata a Modus Ponensnek – átemeli a Modus Ponenst az ítéletlogikából az elsőrendű logikába. Látni fogjuk a fejezet későbbi részében, hogy kifejleszthetjük az előrefelé láncolás, a hátrafelé láncolás és a 7. fejezetben bemutatott rezolúciós algoritmusok kiemelt változatait is. A kiemelt következtetési szabályok legfontosabb előnye az ítéletlogikára történő átalakítással szemben az, hogy csak azokat a helyettesítéseket hajtják végre, amelyek bizonyos következtetések végrehajtását teszik lehetővé. Egy potenciális korlát az, hogy egy bizonyos szempontból az Általánosított Modus Ponens kevésbé általános, mint a Modus Ponens (lásd 7.5. szakasz - Az ítéletkalkulus következtetési mintái részben): a Modus Ponens bármely α mondatot megenged az implikáció bal oldalán, ezzel szemben az Általánosított Modus Ponens speciális formátumot kíván meg erre a mondatra. Csak abban az értelemben nevezhető általánosítottnak, hogy tetszőleges számú pi′-re alkalmazható.
A kiemelt következtetési szabályok olyan helyettesítések megtalálását igénylik, amelyek a különböző logikai kifejezéseket látszólag azonossá teszik. Ezt a folyamatot egyesítési lépésnek (unification) nevezzük, ami kulcsfontosságú eleme minden elsőrendű következtetési algoritmusnak. Az EGYESÍT algoritmus vesz két mondatot, és visszaad egy rájuk vonatkozó egyesítést (unifier), ha létezik ilyen:
Egyesít(p, q) = θ, ahol Helyettesít(θ, p) = Helyettesít(θ, q)
Nézzünk meg néhány példát arra, hogy az EGYESÍT-nek hogyan kell viselkednie. Tételezzük fel, hogy van egy Ismer(János, x) lekérdezésünk: kit ismer János? Erre a kérdésre néhány választ úgy találhatunk, hogy megkeressük az összes mondatot a tudásbázisban, amely egyesíthető az Ismer(János, x)-szel. Itt vannak az egyesítési eredmények négy különböző, a tudásbázisban előforduló mondatra.
Egyesít(Ismer(János, x), Ismer(János, Júlia)) = {x/Júlia}
Egyesít(Ismer(János, x), Ismer(y, Lajos)) = {x/Lajos, y/János}
Egyesít(Ismer(János, x), Ismer(y, Anyja(y))) = {y/János, x/Anyja(János)}
Egyesít(Ismer(János, x), Ismer(x, Erzsébet)) = sikertelen
Az utolsó egyesítés sikertelen, mert az x nem tudja a János és az Erzsébet értékeit egyszerre felvenni. Emlékezzünk arra, hogy az Ismer(x, Erzsébet) azt jelenti, hogy: „Mindenki ismeri Erzsébetet”, így képesnek kellene lennünk azt kikövetkeztetni, hogy János ismeri Erzsébetet. A probléma abból származik, hogy a két mondat történetesen ugyanazt a változónevet, az x-et használja. A problémát úgy kerülhetjük el, hogy az egyesítendő mondatokban átnevezzük a változókat (standardizing apart) úgy, hogy elkerüljük a nevek egybeeséseit. Például átnevezhetjük az x-et az Ismer(x, Erzsébet)-ben például z17-re (egy tetszőleges új változónévre) anélkül, hogy a jelentését megváltoztatnánk. Most már működik az egyesítésünk:
Egyesít(Ismer(János, x), Ismer(z17, Erzsébet)) = {x/Erzsébet, z17/János}
A 9.7. feladat tovább vizsgálja az átnevezés szükségességének problémáját.
9.1. ábra - Az egyesítési algoritmus. Az algoritmus összehasonlítja a bemenetek felépítését elemről elemre. A θ helyettesítés, amely az
EGYESÍTÉS argumentuma, útközben épül fel, és arra használjuk, hogy meggyőződjünk arról, hogy a későbbi összehasonlítások konzisztensek lesznek az általunk előzőleg létrehozott lekötésekkel. Egy összetett kifejezésben, mint például az F(A, B), a VÁL függvény kiveszi az F függvényszimbólumot, és az ARGOK függvény kiveszi az (A, B) argumentumlistát.
Még egy további nehézségen kell túljutni. Azt mondtuk, hogy az EGYESÍT olyan helyettesítéseket ad vissza, amelyek a két argumentumot látszólag azonossá teszi. Azonban több különböző ilyen egyesítés létezhet. Például az EGYESÍT (Ismer(János, x), Ismer(y, z)) visszaadhatja azt is, hogy: {y/János, x/z}, vagy azt is, hogy: {y/János, x/János, z/János}. Az első egyesítési lépés azt eredményezi, hogy: Ismer(János, z), ezzel szemben a második azt adja, hogy: Ismer(János, János). A második eredményt megkaphatjuk az elsőből is egy további helyettesítés hozzáadásával: {z/János}. Láthatjuk, hogy az első egyesítés általánosabb, mint a második, mert kevesebb korlátozást ad meg a változók értékeire. Azt állapíthatjuk meg, hogy minden egyesítendő kifejezéspárra létezik egy legáltalánosabb egyesítés (most general unifier), amely egyedi a változók átnevezésében. Ebben az esetben ez: {y/János, x/z}.
A legáltalánosabb egyesítések kiszámításához a 9.1. ábrán láthatunk egy algoritmust. Az eljárás igen egyszerű: egy rekurzív algoritmussal egymással párhuzamosan tárjuk fel a két kifejezést, felépítve az egyesítést, kivéve akkor, ha a struktúrákban a két megfelelő elem nem illeszkedik. Van egy drága lépés: amikor egy változót kell egy komplex termhez illesztünk, meg kell vizsgálni, hogy a változó előfordul-e a termben; ha igen, akkor az illesztés sikertelen, mert nem tudunk konzisztens egyesítést megalkotni. Ez a lépés az úgynevezett előfordulási próba (occur check), amely az algoritmus komplexitását az egyesítendő kifejezés méretével négyzetesen növekvővé teszi. Néhány rendszer, beleértve az összes logikai programozási rendszert, egyszerűen kihagyja az előfordulási próbát, és ennek eredményeként a következtetésük nem helyes. Más rendszerek időben lineáris komplexitású, ennél összetettebb algoritmusokat használnak.
A KIJELENT és a KÉRDEZ függvények, amelyek szerepe, hogy informálják és lekérdezzék a tudásbázist, két egyszerűbb függvényt, a TÁROL és a BETÖLT függvényeket használják fel. A TÁROL (s) eltárol egy s mondatot a tudásbázisban, míg a BETÖLT (q) visszaadja az összes egyesítést, amelyet a q lekérdezés felhasználásával lehet létesíteni a tudásbázis illeszthető mondataival. A probléma, amivel illusztráltuk az egyesítést – az összes olyan tény megtalálása, amely egyesíthető az Ismer(János, x)-szel – a BETÖLT egyik példája.
A TÁROL és a BETÖLT megvalósításának legegyszerűbb módja, hogy a tudásbázisban az összes tényt egyetlen hosszú listán tároljuk, és egy q lekérdezés megválaszolásakor meghívjuk az EGYESÍT (q, s)-t minden s mondatra a listán. Ez az eljárás nem hatékony, de működik, és egyelőre elég a fejezet további részének megértéséhez. Az alfejezet hátralévő része áttekinti azokat az eljárásokat, amelyekkel a visszakeresést hatékonyabbá tehetjük, így ezt első olvasásra átugorhatjuk.
A BETÖLT függvényt azzal tehetjük hatékonyabbá, hogy biztosítjuk, hogy az egyesítési lépést csak olyan mondatokkal kíséreljük meg, amelyeknél van egyáltalán esély az egyesítésre. Például nincs értelme, hogy megpróbáljuk az egyesítést az Ismer(János, x)-re és a Fivér(Richárd, János)-re. Elkerülhetjük az ilyen egyesítési lépéseket, ha indexeljük (indexing) a tényeket a tudásbázisban. Egy egyszerű séma, amit predikátum indexelésnek (predicate indexing) nevezünk, beteszi az összes Ismer tényt egy verembe és az összes Fivér tényt egy másikba. A vermek egy hash-táblában[88] tárolhatók, hogy hatékonyan elérhessük őket.
A predikátumok indexelése hasznos, ha sok predikátumszimbólum van, de csak kevés állítás az egyes szimbólumokhoz. Néhány alkalmazásban azonban sok mondat tartozik egy adott predikátumszimbólumhoz. Például tételezzük fel, hogy az adóhatóságok nyomon akarják követni, hogy ki alkalmaz kit, és ezeket a kapcsolatokat egy Alkalmaz(x, y) predikátum használatával írjuk le. Ez egy igen nagy verem lenne, akár munkaadók millióival és alkalmazottak tízmillióival. Egy olyan kérdés megválaszolása, mint az Alkalmaz(x, Richárd), a predikátumok indexelésével az egész verem átböngészését igényelné.
Egy ilyen lekérdezés esetében segítene, ha a tényeket mind a predikátummal, mind a második argumentummal indexelnénk, például úgy, hogy egy kombinált hash-tábla kulcsot használunk. A kulcsot egyszerűen előállíthatjuk a lekérdezésből, és pontosan visszakereshetjük közvetlenül azokat a tényeket, amelyek egyesíthetők a lekérdezéssel. Más lekérdezésekhez, mint amilyen az Alkalmaz(AIMA.org, y), szükségünk van arra, hogy a tényeket a predikátum és az első argumentum kombinálásával indexeljük. Így aztán a tényeket tárolhatjuk többszörös indexkulcsok alatt, azonnal hozzáférhetővé téve minden, a ténnyel egyesíthető lekérdezés számára.
Ha adott egy tárolandó mondat, akkor létre lehet hozni az indexeket az összes lehetséges vele egyesíthető lekérdezéshez. Arra a tényre, hogy Alkalmaz(AIMA.org, Richárd), ezek a lekérdezések:
Alkalmaz(AIMA.org, Richárd) Az AIMA.org alkalmazza Richárdot?
Alkalmaz(x, Richárd) Ki alkalmazza Richárdot?
Alkalmaz(AIMA.org, y) Kit alkalmaz az AIMA.org?
Alkalmaz(x, y) Ki alkalmaz kit?
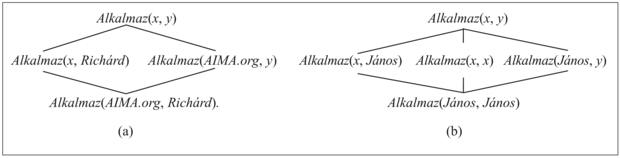
Ezek a lekérdezések egy bennfoglalási hálót (subsumption lattice) alkotnak, amint az a 9.2. (a) ábrán látható. A hálónak van néhány érdekes tulajdonsága. Például a háló bármely csomópontjának a gyereke a szülőjéből egy egyszerű behelyettesítéssel megkapható, és a „legmagasabb” közös leszármazottja bármely két csomópontnak a legáltalánosabb egyesítőjük használatával érhető el. A háló részeiből bármely alaptény szisztematikusan létrehozható (9.5. feladat). Egy ismétlődő konstansokkal rendelkező mondatnak egy kissé más hálója van, ezt a 9.2. (b) ábrán láthatjuk. A függvényszimbólumok és a változók az eltárolandó mondatokban még érdekesebb hálófelépítéseket tesznek szükségessé.
9.2. ábra - (a) A bennfoglalási háló, amelynek a legalacsonyabb csomópontja ez a mondat: Alkalmaz(AIMA.org, Richárd). (b) A bennfoglalási háló arra a mondatra, hogy: Alkalmaz(János, János).
A séma, amelyet leírtunk, nagyon jól működik, amikor a háló csak kisszámú csomópontot tartalmaz. Egy n argumentumú predikátumra a háló O(2n) csomópontot tartalmaz. Ha a függvényszimbólumok használata megengedett, akkor a csomópontok száma szintén exponenciális a tárolandó mondat termjeinek függvényében. Ez rendkívül nagy számú indexet eredményezhet. Egy ponton az indexelés elveszti előnyeit az összes index tárolásának és fenntartásának problémája miatt. Ez ellen egy rögzített stratégia bevezetésével próbálhatunk védekezni úgy, hogy csak azokon a kulcsokon tartunk fenn indexeket, amelyek predikátumokból és az egyes argumentumokból állnak. Egy másik megoldás, hogy egy adaptív tervet használunk, amely mindig olyan indexeket hoz létre, amelyek megfelelnek az aktuális lekérdezéstípus igényeinek. A legtöbb MI-rendszerben a tárolni kívánt tények száma elég kicsi ahhoz, hogy a hatékony indexelés problémáját megoldottnak tekintsük. Az ipari és kereskedelmi adatbázisok esetében jelentős technikai fejlesztések történtek a feladat megoldására.
[88] A hash-tábla információk tárolására és visszakeresésére szolgáló olyan adatstruktúra, amelyeket rögzített kulcsokkal indexelünk. Gyakorlati okokból egy hash-táblát tekinthetünk olyannak, mint amelynek a tárolási és a visszakérdezési ideje állandó, akkor is, ha a tábla nagyon nagy számú elemet tartalmaz.
